Advanced AI models such as DeepSeek-R1 are proving that enterprises can now build cutting-edge AI models specialized with their own data and expertise. These models can be tailored to unique use cases, tackling diverse challenges like never before.
Based on the success of early AI adopters, many organizations are shifting their focus to full-scale production AI factories. Yet the process of creating productive AI factories is complex, time-consuming, and differs from the goal of building vertical-specific AI.
It involves building automation that provisions and manages the complex infrastructure, maintaining a team of site reliability engineers (SREs) with specialized skills on the latest platforms, and developing processes at scale that allow for hyperscaler-level efficiency. As well, developers need a means to harness the power of AI infrastructure with the agility, efficiency, and scale of a hyperscaler, but without the accompanying burdens of cost, complexity, and expertise.
This post unpacks how NVIDIA Mission Control, an integrated software stack for powering the AI factories built using NVIDIA reference architectures, addresses these challenges by codifying NVIDIA best practices, thus enabling organizations to confidently focus on building models instead of managing infrastructure.
New standard for enterprise infrastructure and developer productivity
NVIDIA Mission Control equips IT administrators with powerful tools to optimize AI workload utilization, performance, and efficiency at scale. With automated workload recovery, developers can maintain productivity even during hardware anomalies or maintenance—ensuring unmatched uptime and faster AI experimentation. Designed for scalability, NVIDIA Mission Control provides advanced cluster-wide control and visibility, seamlessly managing thousands of GPUs for peak operational efficiency.
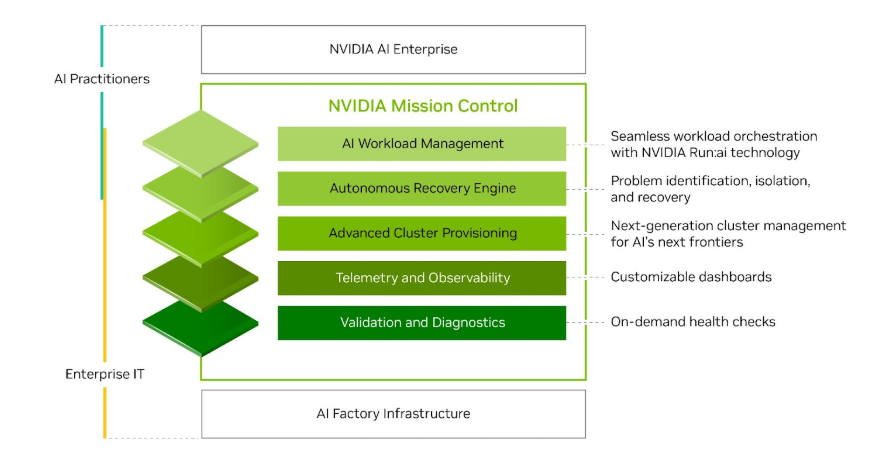
Key functionalities of NVIDIA Mission Control
Key functionalities include a scalable control plane, advanced cluster provisioning, telemetry and observability, AI workload management, and more.
Scalable control plane for rapid deployment
Accelerating AI factory deployment starts with a standardized, scalable control plane that delivers centralized configuration, management, and observability for both training and inference workloads. Designed for flexibility, this control plane seamlessly supports heterogeneous architectures, enabling deployment across NVIDIA DGX SuperPOD with both NVIDIA DGX B200 systems and NVIDIA DGX GB200 systems within the same AI factory.
Advanced cluster provisioning
Advanced cluster provisioning in NVIDIA Mission Control, powered by NVIDIA Base Command Manager, simplifies AI factory operations, slashing deployment time with automated workflows designed for peak efficiency. Purpose-built for cutting-edge architectures like NVIDIA GB200 NVL72, it introduces rack management capabilities, leak detection policies, provisioning for thousands of GPUs, and secure networking at scale.
With integrated inventory management and intuitive visualizations, IT teams gain real-time asset tracking and streamlined maintenance. Smart power optimization policies empower administrators to fine-tune performance at both user and datacenter levels, maximizing efficiency. Plus, with advanced integration for datacenter building management systems (BMS) through standardized interfaces, NVIDIA Mission Control ensures a future-ready AI infrastructure.
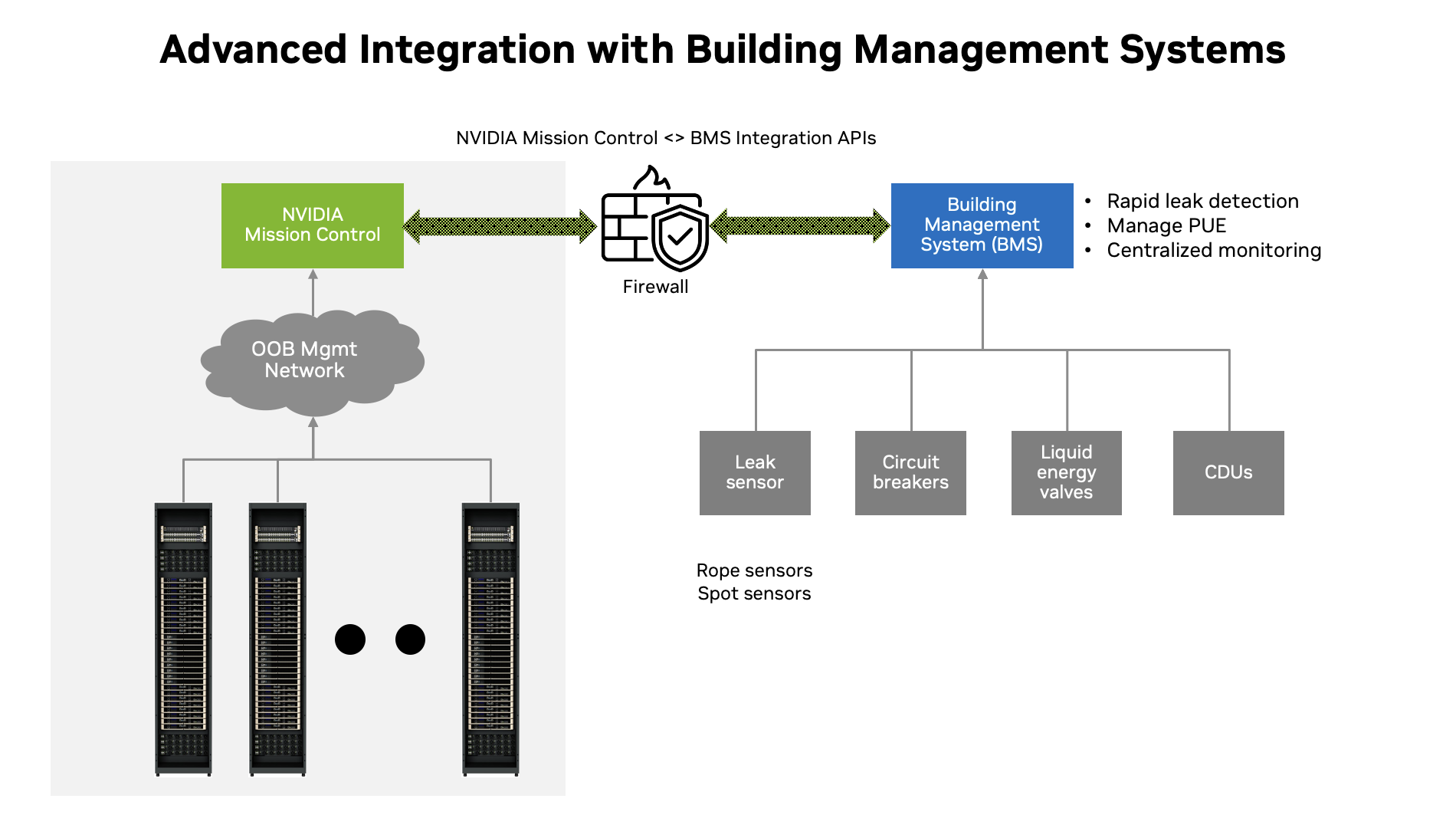
Telemetry and observability
The telemetry and observability stack provides real-time monitoring and advanced analytics, giving IT administrators deep visibility into AI infrastructure performance. Built for scalability and resilience, the telemetry collection system parallelizes data gathering across thousands of GPUs, NVIDIA Spectrum-X Ethernet and NVIDIA Quantum InfiniBand networking switches, and NVIDIA NVLink switches in an AI factory. The system is powered by NVIDIA Unified Fabric Manager (UFM) and NVIDIA NMX Manager.
A centralized observability hub processes key system metrics into a time-series database for monitoring, visualization, and alerting. With centralized dashboards, proactive alerts, and intelligent log management, NVIDIA Mission Control empowers IT admins to maintain unmatched control and operational efficiency for their AI factory.
Validation and diagnostic
NVIDIA Mission Control ensures comprehensive AI factory validation, rigorously verifying components from basic functionality to complex interactions. Built on the scalable testing framework that achieved industry-leading MLPerf benchmark performance for NVIDIA AI supercomputers—Selene, Eos, and more—this suite delivers real-time health monitoring and early issue detection from installation onward. IT admins can also leverage these on demand health checks to assess their AI infrastructure throughout its lifecycle, ensuring peak performance and reliability at scale.
AI workload management
The NVIDIA Run:ai platform brings enterprise-grade AI workload orchestration, seamlessly combining a centralized control plane with intelligent cluster management for multi-cluster efficiency boosting GPU utilization by up to 5x. Built on Kubernetes and now integrated with NVIDIA Mission Control, it supports NVLink topology awareness as well as built in health checks for unlocking the full potential of next-generation architectures like NVIDIA DGX GB300. Developers also gain the flexibility to use Slurm for workload management, ensuring an adaptable, scalable AI infrastructure from research labs to enterprise-wide deployments.
Autonomous recovery engine
NVIDIA Mission Control leverages an autonomous recovery engine that works in the background of large scale training jobs. This improves AI training reliability with event-driven, microservices that detect, isolate, and resolve workload disruptions, improving GPU use across AI factories. The autonomous recovery engine integrates with Slurm and leverages NVIDIA Run:ai for Kubernetes to manage workloads.
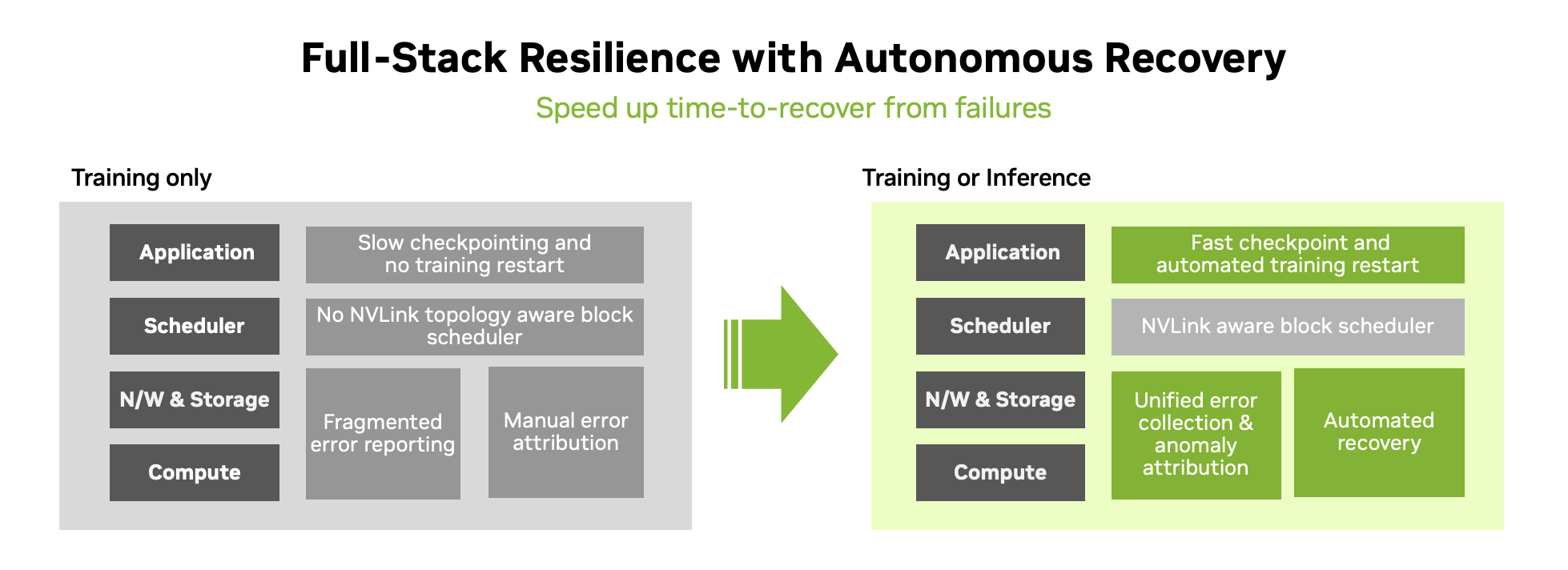
The autonomous recovery engine continuously detects anomalies by analyzing real-time system health, using AI models and predefined rules to pinpoint operational issues and link them to specific hardware behaviors. When anomalies arise, NVIDIA Mission Control intervenes—restarting the job from the last known good checkpoint provided by the NVIDIA Resiliency Extension (NVRx), eliminating the need for developers or SREs to monitor progress manually. This minimizes downtime and accelerates time-to-recovery by 10x leading to faster training and inference runs. Faulty hardware is automatically excluded, ensuring smooth execution.
Meanwhile, NVIDIA Mission Control takes charge of diagnostics, identifying root causes in sidelined hardware. These diagnostics have been built on NVIDIA’s own experience building AI factories and saves the manual debug efforts for developers. Its workflow engine executes automated recovery playbooks, working to repair and reintegrate healthy components back into operation.
If a component remains unrecoverable, NVIDIA MIssion Control flags it for return merchandise authorization (RMA). The software can initiate a support ticket with NVIDIA Enterprise Support, streamlining the resolution process. This intelligent orchestration maximizes AI factory uptime, maximizes efficiency, and ensures developers can achieve results in a predictable manner.
Get started with NVIDIA Mission Control
The AI factory isn’t just a traditional data center—it’s the backbone that ensures mission-critical workloads stay up and running, enabling organizations to accelerate their investments in AI. As organizations scale AI, the focus shifts to empowering model builders and accelerating AI experimentation, which is crucial for achieving faster time to market and maintaining a competitive edge.
With NVIDIA Mission Control, enterprises will benefit from streamlined AI operations—across the workloads to infrastructure layer—with codified expertise delivered through new software automation. NVIDIA Mission Control is an essential component that powers NVIDIA Blackwell data centers, bringing instant agility for inference and training while providing full-stack intelligence for infrastructure resilience.
Every enterprise can now run AI with hyperscale efficiency, simplifying and accelerating AI experimentation. To learn more, check out the on-demand replay for the NVIDIA GTC 2025 session, Next-Gen Data Centers: Intelligent Automation and Integrated Observability for Peak Developer Productivity.