
NVIDIA ACE is a suite of digital human technologies that bring game characters and digital assistants to life with generative AI. ACE on-device models enable agentic workflows for autonomous game characters that can perceive their environment, understand multi-modal inputs, strategically plan a set of actions and execute them all in real time, providing dynamic experiences for players.
To run these models alongside the game engine, the NVIDIA In-Game Inferencing (NVIGI) SDK enables you to integrate AI inference directly into C++ games and applications for optimal performance and latency.
This post shows how NVIGI integrates with ACE to enable seamless AI inference in game development. We cover the NVIGI architecture, key features, and how to get started creating autonomous characters with NVIDIA ACE on-device models.
NVIDIA ACE on-device models
NVIDIA ACE enables speech, intelligence, and animation powered by generative AI. It delivers a suite of AI models that enable game characters to perceive, reason, and act based on player interactions in real time:
- Perception: The upcoming NeMoAudio-4B-Instruct model enhances character interactions with greater contextual awareness from audio. You can easily integrate more multimodal models to further expand these capabilities by incorporating additional sensory inputs.
- Cognition: The Mistral-Nemo-Minitron-Instruct family of small language models top the charts in terms of instruction following capabilities enabling characters to accurately roleplay.
- Memory: Embedding models like E5-Large-Unsupervised enable characters to recall past interactions, enriching immersion.
- Animation: Real-time AI-driven animation such as Audio2Face delivers accurate lip sync for dynamic and lively emotions.
- Action: Simple interfaces and custom logic enable characters to take meaningful actions, from selecting in-game responses to executing strategic plans through model-driven decision-making and prompts.
What is the NVIDIA In-Game Inferencing SDK?
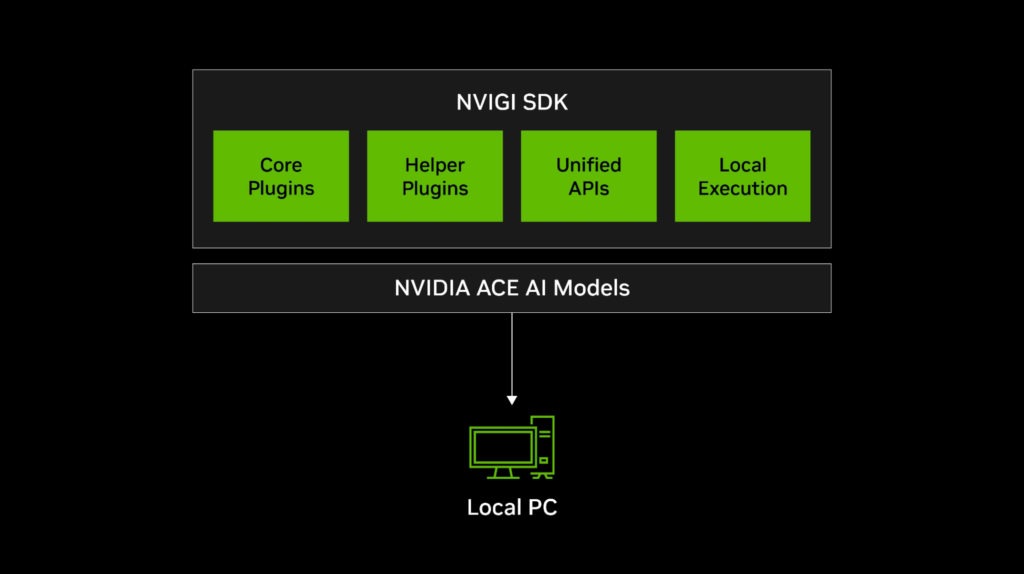
The NVIGI SDK is a GPU-optimized, plugin-based inference manager designed to simplify the integration of ACE models into gaming and interactive applications. It offers the following functionality:
- Plugin flexibility: Add, update, and manage AI plugins (ASR, language models, embeddings) with ease.
- Windows-native DLLs: Streamline workflows for C++ games and applications.
- GPU optimization: Use compute-in-graphics (CIG) technology for efficient AI inference alongside rendering tasks.
By combining NVIGI with ACE, you can create autonomous characters with advanced generative AI capabilities, such as real-time NPC dialogue, contextual memory, and lifelike animation.
How NVIGI works
At its core, the NVIGI architecture is based on modular plugins that enable flexible integration of various AI functionalities:
- Core plugins: Provide AI capabilities such as automatic speech recognition (ASR), generative reasoning, and embedding retrieval.
- Helper plugins: Handle utilities such as GPU scheduling and network communication.
- Unified APIs: Simplify plugin management and reduce code complexity.
- Local and cloud execution: Supports both on-device inference (CPU/GPU) and cloud-based AI workflows.
These components work together to deliver a seamless AI-driven gaming experience. For example, imagine a player asking a question to an NPC. NVIGI orchestrates an agentic workflow, enabling characters to listen, reason, speak, and animate in real time.
This process follows a few key steps:
- Listen to users with ASR: The NPC processes player speech using NVIDIA Riva ASR, converting spoken input into text for further reasoning.
- Generate a response with an SLM: The transcribed text is passed to a small language model (SLM), such as Mistral-Nemo-Minitron-128K-Instruct, which generates a dynamic, contextually relevant response. If additional context is needed, a retrieval-augmented generation (RAG) approach can be used, where an embedding model like E5-Large-Unsupervised converts text into vector representations. These vectors are then used in a similarity search to retrieve relevant knowledge, enriching the SLM’s response with additional context.
- Give characters a voice with TTS: The generated response is synthesized into lifelike voices, ensuring natural intonation and expressiveness.
- Create interactive animation: The spoken response then drives facial blendshapes for real-time animation using Audio2Face-3D, ensuring accurate lip sync and expressive character movements.
Throughout this process, GPU scheduling and CiG ensure that AI inference workloads run alongside rendering tasks while minimizing impact to frame rates. This ensures a seamless, real-time experience.
For more information about implementing these plugins and models for in-process execution, see the next sections.
Getting started with ACE on-device inference
This section outlines how to use NVIGI with ACE SLMs to enable in-process, AI inference alongside your rendering workloads.
NVIGI includes batch files that fetch models from repositories like NVIDIA NGC and Huggingface. This keeps the initial download minimal and ensures that you only have to download the models you want to work with. It also includes a suite of local inference plugins, which we highlight later to help you get started.
Initialize NVIGI
The first step is to initialize the NVIGI framework. This process sets up plugin paths, logging, and core configurations needed for NVIGI to function within your game.
The following code example shows how to initialize NVIGI in your game:
nvigi::Preferences preferences{};preferences.logLevel = nvigi::LogLevel::eVerbose; // Enable verbose loggingpreferences.utf8PathsToPlugins = {"path/to/plugins"}; // Set plugin pathpreferences.utf8PathToLogsAndData = "path/to/logs"; // Define log pathif (nvigiInit(preferences, nullptr, nvigi::kSDKVersion) != nvigi::kResultOk) { std::cerr << "Failed to initialize NVIGI." << std::endl;} |
Load plugins and model
The NVIGI architecture is built around a plugin system that offers modularity and flexibility. Plugins are included for AI model classes such as LLMs, ASR, and embedding retrieval. These plugins enable you to deploy AI models from the ACE range to implement the features and behaviors you need.
Each plugin is designed to support multiple models that share a designated backend and underlying API. NVIGI includes in-process plugins with support for popular backends such as GGML (llama.cpp, whisper.cpp, embedding.cpp), ONNX Runtime, and DirectML.
Here are some examples:
nvigi.plugin.asr.ggml.cuda: Converts speech into text using GGML and CUDA.nvigi.plugin.gpt.ggml.cuda: Powers the AI-generated dialogue and reasoning.nvigi.plugin.embed.ggml.*: Finds relevant text based on sentiment, to provide better context.
To use the GPT plugin, first load its interface to query the model’s capabilities:
// Load GPT plugin interfacenvigi::IGeneralPurposeTransformer* gpt = nullptr;nvigiGetInterfaceDynamic(nvigi::plugin::gpt::ggml::cuda::kId, &gpt, ptr_nvigiLoadInterface); |
NVIGI comes pre-loaded with a selection of manually downloadable models to get started, but you can get more GGUF models either from NGC or on Huggingface. You then define model parameters for the plugin, such as the following example:
// Configure model parametersnvigi::CommonCreationParameters common{};common.utf8PathToModels = "path/to/models";common.numThreads = 8; // Number of CPU threadscommon.vramBudgetMB = vram; // VRAM allocation in MBcommon.modelGUID = "{YOUR_MODEL_GUID}"; // Model GUID |
When the interface and model parameters are loaded, configure an instance or in-process inference:
// Create GPT instancenvigi::InferenceInstance* gptInstance = nullptr;if (gpt->createInstance(common, &gptInstance) != nvigi::kResultOk || !gptInstance) { std::cerr << "Failed to create GPT instance." << std::endl;}// Use GPT instance for inference |
Create the runtime configuration and inference
The InferenceInstance interface provides the API for executing inference tasks and is configured through InferenceExecutionContext. This interface enables the setup of input slots, runtime parameters, and callback mechanisms to retrieve model responses.
Inference tasks rely on input data, such as player text or audio, combined with runtime configurations. The context for defining a game character’s personality and role can be established using the nvigi::kGPTDataSlotSystem slot:
// Define NPC role in a system promptstd::string npcPrompt = "You are a helpful NPC named TJ in a fantasy game.";nvigi::CpuData systemPromptData(npcPrompt.length() + 1, npcPrompt.c_str());nvigi::InferenceDataText systemPromptSlot(systemPromptData);// Set runtime parametersnvigi::GPTRuntimeParameters runtime{};runtime.tokensToPredict = 200; // Limit token prediction to 200 tokensruntime.interactive = true; // Enable multi-turn conversationsstd::vector<nvigi::InferenceDataSlot> slots = { {nvigi::kGPTDataSlotSystem, &systemPromptSlot}};// Inference contextnvigi::InferenceExecutionContext gptExecCtx{};gptExecCtx.instance = gptInstance;gptExecCtx.runtimeParameters = runtime;gptExecCtx.inputs = slots.data(); |
Dynamic interaction between the player and game character can be managed as follows:
std::string userInput = "What’s your name?"; // example user inputnvigi::CpuData userInputData(userInput.length() + 1, userInput.c_str());nvigi::InferenceDataText userInputSlot(userInputData);slots = {{nvigi::kGPTDataSlotUser, &userInputSlot}};gptExecCtx.inputs = slots.data(); |
Run inference and handling of the response asynchronously:
if (gptExecCtx.instance->evaluate(&gptExecCtx) == nvigi::kResultOk) { std::cout << "Inference completed successfully!" << std::endl;} |
Each turn of the conversation is processed through the nvigi::kGPTDataSlotUser input slot, maintaining context for multi-turn dialogue.
You can also implement a callback function to capture the character response for display in-game, with the example shown in the next section.
Enable GPU scheduling and rendering integration
AI workloads in games run alongside rendering tasks, so effective GPU scheduling is crucial to maintain frame rates. NVIGI uses CIG to schedule GPU workloads efficiently.
To schedule graphics and compute efficiently, NVIGI must get the D3D direct queue that your game is using for graphics. The D3D12Parameters structure ensures that NVIGI integrates directly with the rendering pipeline, enabling AI tasks to run in parallel without impacting graphical performance.
The following code example shows how to enable CIG for AI inference using the NVIGI IHWICuda interface, using the ASR plugin as an example:
// Enable Compute-in-Graphics (CIG)nvigi::IHWICuda* icig = nullptr;if (nvigiGetInterface(nvigi::plugin::hwi::cuda::kId, &icig) != nvigi::kResultOk || !icig) { std::cerr << "Failed to load CIG interface." << std::endl; return;}// Set up D3D12 parametersnvigi::D3D12Parameters d3d12Params{};d3d12Params.device = myD3D12Device; // D3D12 device used for renderingd3d12Params.queue = myD3D12CommandQueue; // Graphics command queue// Activate GPU scheduling for both inference and renderingif (icig->enableComputeInGraphics(d3d12Params) != nvigi::kResultOk) { std::cerr << "Failed to enable Compute-in-Graphics." << std::endl; return;}std::cout << "Compute-in-Graphics enabled successfully." << std::endl; |
To set up NVIGI GPU scheduling in Unreal Engine 5 (UE5), use the global dynamic rendering hardware interface (RHI) to access the game’s D3D device and command queue.
Configuring CIG in UE5 is straightforward:
// UE5-specific code to retrieve D3D12 resources#include "ID3D12DynamicRHI.h"ID3D12DynamicRHI* RHI = nullptr;if (GDynamicRHI && GDynamicRHI->GetInterfaceType() == ERHIInterfaceType::D3D12){ RHI = static_cast<ID3D12DynamicRHI*>(GDynamicRHI);}ID3D12CommandQueue* CmdQ = nullptr;ID3D12Device* D3D12Device = nullptr;if (RHI) { CmdQ = RHI->RHIGetCommandQueue(); // Get graphics command queue int DeviceIndex = 0; D3D12Device = RHI->RHIGetDevice(DeviceIndex); // Get D3D12 device}// Configure D3D12 parameters for IGInvigi::D3D12Parameters d3d12Params{};d3d12Params.device = D3D12Device;d3d12Params.queue = CmdQ;// Pass the parameters to IGI instancesnvigi::CommonCreationParameters commonParams{};commonParams.chain(d3d12Params);// Example: Creating an ASR instance with CIGnvigi::ASRCreationParameters asrParams{};asrParams.common = &commonParams;nvigi::InferenceInstance* asrInstance = nullptr;iasr->createInstance(asrParams, &asrInstance); |
Run inference
Inference tasks on NVIGI involve setting up a conversation context, processing user inputs, and generating responses dynamically. The following steps outline how to run inference tasks efficiently in your game environment.
To execute inference, you must create an inference context, which includes the following:
- Input slots: Prepare input data (user text, voice data) in a format that the model can process.
- Runtime parameters: Define the behavior of the inference, such as the number of tokens to predict or interactivity settings.
- Callback mechanisms: Specify how to handle the output results.
The inference context defines how inputs and outputs are processed. Start by enabling interactive mode and preparing runtime parameters:
// Configure runtime parameters for GPTnvigi::GPTRuntimeParameters runtime{};runtime.tokensToPredict = 200; // Predict up to 200 tokensruntime.interactive = true; // Enable interactive mode// Set up inference contextnvigi::InferenceExecutionContext gptExecCtx{};gptExecCtx.instance = gptInstance; // Use the GPT instance created earliergptExecCtx.runtimeParameters = runtime;gptExecCtx.callback = [](const nvigi::InferenceExecutionContext* execCtx, nvigi::InferenceExecutionState state, void* userData) { if (state == nvigi::kInferenceExecutionStateDone && execCtx->outputs){ const nvigi::InferenceDataText* responseText = nullptr; execCtx->outputs->findAndValidateSlot(nvigi::kGPTDataSlotResponse, &responseText); if (responseText) { std::cout << "NPC Response: " << responseText->getUtf8Text() << std::endl; } } return state;}; |
You can begin the conversation by providing a system prompt that defines the NPC’s personality or role. Use the nvigi::kGPTDataSlotSystem slot for this purpose:
// Set up conversation contextstd::string npcPrompt = "You are a helpful NPC in a fantasy game. Respond thoughtfully to player questions.";nvigi::CpuData systemPromptData(npcPrompt.length() + 1, npcPrompt.c_str());nvigi::InferenceDataText systemPromptSlot(systemPromptData);std::vector<nvigi::InferenceDataSlot> slots = { {nvigi::kGPTDataSlotSystem, &systemPromptSlot} // Set the system prompt};gptExecCtx.inputs = slots.data();gptExecCtx.numInputs = slots.size();// Execute to initialize conversation contextif (gptExecCtx.instance->evaluate(&gptExecCtx) != nvigi::kResultOk) { std::cerr << "Failed to initialize conversation context." << std::endl; return;} |
List of available NVIGI plugins
You can begin building agentic frameworks for on-device inference with the following speech and intelligence models today.
| NVIGI Plugin | Supported Inference Hardware | Supported Models |
| Speech – ASR Local GGML | CUDA-Enabled GPU or CPU | Whisper ASR |
| Speech – ASR Local TRT | CUDA-Enabled GPU | NVIDIA RIVA ASR (coming soon) |
| Language – GPT Local ONNX DML | ONNX-supported GPU or CPU | Mistral-7B-Instruct |
| Language- GPT Local GGML | CUDA-Enabled GPU or CPU | Llama-3.2-3b InstructNemotron-Mini-4B-InstructMistral-Nemo-Minitron-2B-128k-InstructMistral-Nemo-Minitron-4B-128k-InstructMistral-Nemo-Minitron-8B-128k-InstructNemovision-4B-Instruct |
| RAG – Embed Local GGML | CUDA-Enabled GPU or CPU | E5 Large Unsupervised |
Conclusion
NVIDIA ACE and NVIGI represent the next step in the evolution of AI-driven game development. By combining ACE’s advanced generative AI models with NVIGI seamless integration and GPU-optimized performance, you can unlock new levels of interactivity and immersion.
From dynamic NPC dialogue and real-time speech recognition to lifelike animations and contextual memory, ACE and NVIGI provide a cost-effective, scalable solution for creating intelligent, autonomous characters.
Get started with NVIDIA ACE with NVIGI today.












