Organizations are embracing AI agents to enhance productivity and streamline operations. To maximize their impact, these agents need strong reasoning abilities to navigate complex problems, uncover hidden connections, and make logical decisions autonomously in dynamic environments.
Due to their ability to tackle complex problems, reasoning models have become a key part of the agentic AI ecosystem. By using techniques like long thinking, Best-of-N, or self-verification, these models are better at the reasoning-heavy tasks that are integral to agentic pipelines.
Reasoning models are powering diverse applications, from automating customer support to optimizing supply chains and executing financial strategies. In logistics, they enhance efficiency by simulating what-if scenarios, such as rerouting shipments during disruptions. In scientific research, they assist with hypothesis generation and multistep problem-solving. In healthcare, they enhance diagnostics and treatment planning. By enabling precise, logical reasoning, these models are driving more reliable and scalable AI solutions across industries.
This post introduces the NVIDIA Llama Nemotron reasoning family of models. We’ll walk through the process that built this state-of-the-art family of models. We’ll also explore how these models can be used in AI agents and collaborative multi-agent systems to push beyond reasoning and into open-ended, general-domain tasks.
NVIDIA Llama Nemotron reasoning model family
Today, NVIDIA announced NVIDIA Llama Nemotron, an open family of leading AI models that deliver exceptional reasoning capabilities, compute efficiency, and an open license for enterprise use.
The family comes in three sizes, providing developers with the right model size based on their use case, compute availability, and accuracy requirements.
- Nano: 8B fine-tuned from Llama 3.1 8B for highest accuracy on PC and edge.
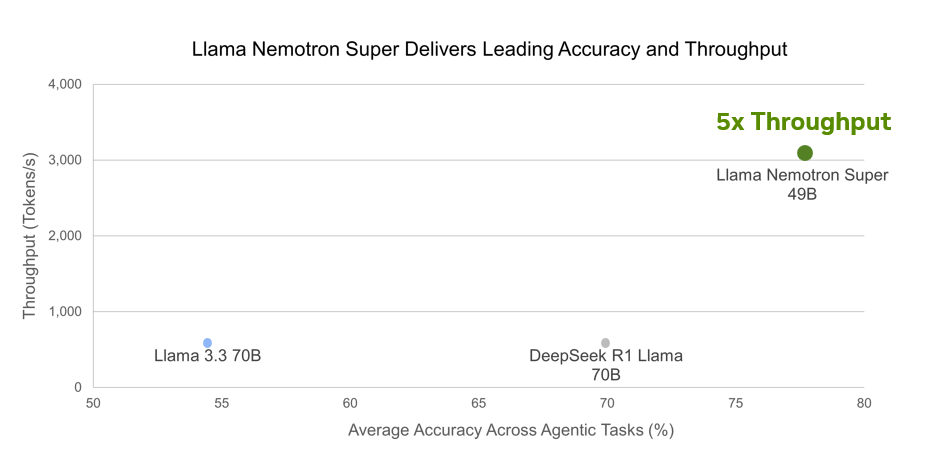
- Super: 49B distilled from Llama 3.3 70B for best accuracy with highest throughput on a data center GPU. This model is the focus of this post.
- Ultra: 253B distilled from Llama 3.1 405B for maximum agentic accuracy on multi-GPU data center servers (coming soon).
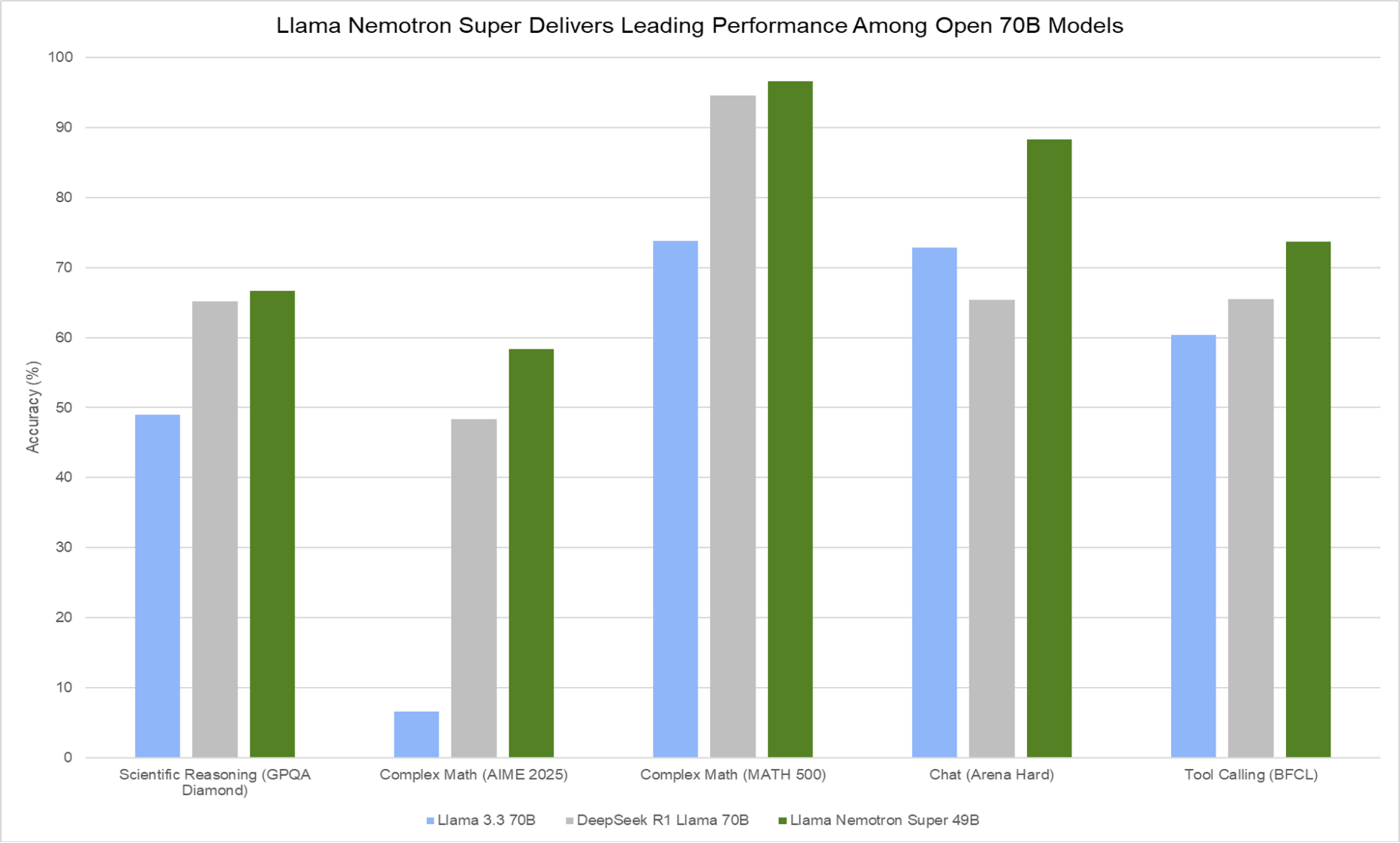
The Llama Nemotron with reasoning models provide leading accuracy across industry-standard reasoning and agentic benchmarks: GPQA Diamond, AIME 2024, AIME 2025, MATH 500, and BFCL, as well as Arena Hard. Additionally, these models are commercially viable, as they are built on open Llama models and trained on NVIDIA-vetted datasets as well as synthetically generated data using open models.
Along with the recipes outlined in this post, and the model being permissively licensed, we are also sharing a large portion of the data that was used during the post-training pipeline on Hugging Face. This data includes post-training data, with nearly 30 million samples of high-quality data with a focus on math, code, instruction following, safety, chat, and reasoning capabilities.
You can learn more about the dataset on Hugging Face. Our team is committed to continued data releases. We have also made HelpSteer3 public, as a continuation of our earlier work on HelpSteer and HelpSteer2.
Overview of test-time scaling
Before we dive into how NVIDIA created these incredible models, we need to briefly explain test-time scaling and reasoning, and why they’re important to organizations building with AI.
Test-time scaling is a technique that applies more compute during inference time to think and reason through various options, improving the responses of the model or system. This enables scaling the performance of the model or system on key downstream tasks.
Reasoning through problems is a complex task, and test-time compute is a significant part of what enables these models to achieve the level of reasoning required to be useful for the use cases previously mentioned. Enabling the model to spend more resources during inference opens a larger space of possibilities to be explored. This increases the likelihood that the model makes the connection it needs to, or achieves a solution it might not otherwise reach, without the additional time.
While reasoning and test-time scaling are of great benefit to a number of important tasks in agentic workflows, there exists a common issue in the current state-of-the-art reasoning models. Specifically, developers cannot select when the model reasons, as in they cannot select between “reasoning on” and “reasoning off” operation. The Llama Nemotron family of models turn reasoning on or off through the system prompt, allowing the models to retain their usefulness in nonreasoning problem domains as well.
Building Llama Nemotron with reasoning
Llama 3.3 Nemotron 49B Instruct started from a base of Llama 3.3 70B Instruct. It went through an extensive post-training phase to reduce the size of the model, while retaining—and then augmenting—the model’s original capabilities.
Three broad phases of post-training were used:
- Distillation through Neural Architecture Search and Knowledge Distillation. To learn more, see Puzzle: Distillation-Based NAS for Inference-Optimized LLMs.
- Supervised fine-tuning, with 60B tokens of synthetic data (representing 4M of the 30M generated samples) created by NVIDIA to ensure high quality content across both reasoning off and reasoning on domains. During this stage, the team leveraged the NVIDIA NeMo framework to scale the post-training pipeline effectively and efficiently.
- A reinforcement learning (RL) phase completed with NVIDIA NeMo to enhance chat capabilities and instruction-following performance. This ensures high-quality responses across a wide range of tasks.
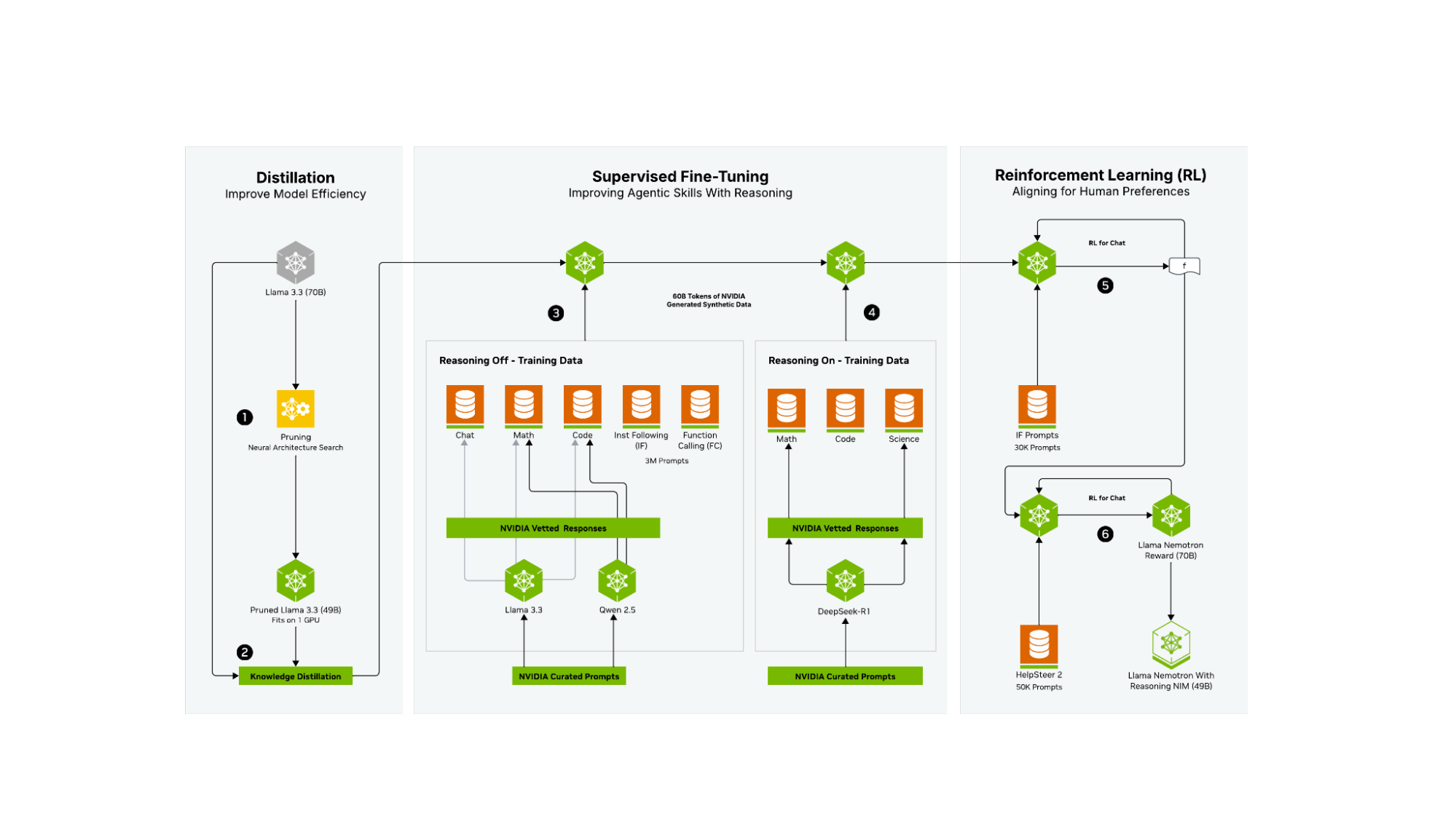
The first phase (Steps 1 and 2 in Figure 1) is explained in detail in the Neural Architecture Search (NAS) technical report. In simplified form, it can be thought of as being used to “right-size” each model’s parameter count to a preselected optimal count based on specific flagship hardware through a number of distillation and NAS approaches.
The second phase of model post-training (Steps 3 and 4 in Figure 1) involves synthetic data-powered supervised fine-tuning that seeks to achieve a few important objectives. The first objective is to improve the non-reasoning performance across a number of tasks. This part of the post-training pipeline (Step 3) leveraged NVIDIA-curated prompts to create synthetic data through the baseline model (Llama 3.3 70B Instruct) as well as Qwen2.5 7B Math and Coder models. This data was then curated and vetted by NVIDIA to be used in augmenting the reasoning-off performance on Chat, Math, and Code tasks. As well, significant effort was used to ensure the reasoning-off performance on Instruction Following and Function Calling was best-in-class during this phase.
The second objective (Step 4) was to create a best-in-class reasoning model by training on curated DeepSeek-R1 data (for Math, Code, and Science only). Each prompt and response was curated to ensure only high quality data was used during the reasoning enhancement process and was aided by the use of NVIDIA NeMo framework. This approach ensures that we selectively distill the strong reasoning capabilities of DeepSeek-R1 in domains where it excels.
Reason ON/OFF (Steps 3 and 4 in Figure 1) were trained at the same time and differed only by their system prompt, meaning that the resultant model can act both as a reasoning model, as well as a traditional LLM with a switch (the system prompt) to change between each mode. This was done so that organizations can use a single right-sized model for both reasoning and nonreasoning tasks.
The final phase used RL to improve alignment with user intentions and expectations (Steps 5 and 6 in Figure 1). The model undergoes RL leveraging the REINFORCE algorithm and heuristic based verifiers on both tasks, for Instruction Following and Function Calling enhancements (Step 5). Afterward, using Reinforcement Learning from Human Feedback (RLHF), the final model is aligned for chat use cases using the HelpSteer2 dataset, and the NVIDIA Llama 3.1 Nemotron Reward model (Step 6).
These meticulous post-training steps result in best-in-class reasoning models, without compromising on function-calling and instruction-following performance by nature of providing a switch between these two paradigms. This post-training pipeline creates models that are effective at each step of agentic AI workflows and pipelines, while maintaining optimal parameter counts for flagship NVIDIA hardware.
Achieving leading accuracy across benchmarks with Llama Nemotron Super
The NVIDIA Llama Nemotron models combine the strong reasoning capabilities of models like DeepSeek-R1, with the exceptional world knowledge and focus on reliable tool calling and instruction following of Meta’s Llama 3.3 70B Instruct, resulting in models that lead across key agentic tasks.
Powering systems with Llama Nemotron Super for complex tasks
This section explains a new test-time scaling approach that uses a multi-agent collaborative system, powered by NVIDIA Llama 3.3 Nemotron 49B Instruct. It achieves state-of-the-art performance on the Arena Hard benchmark, a key predictor of Chatbot Arena performance, with a score of 92.7. For more details, see Dedicated Feedback and Edit Models Empower Inference-Time Scaling for Open-Ended General-Domain Tasks.
Many test-time scaling methods are primarily designed to be used for problems with verifiable solutions, including math problems, logical reasoning, and competitive programming. However, many important tasks do not have verifiable solutions, including coming up with research ideas, writing research papers, or developing an effective approach for delivering a complex software product.
The Llama Nemotron test-time scaling system addresses this limitation. The approach leverages a more humanlike approach to these problems and involves the following steps:
- Brainstorm one or more initial solutions to a problem
- Get feedback on the solutions, from friends, colleagues, or other experts
- Edit the initial solutions based on provided feedback
- Select the most promising solution after incorporating edits
This method enables taking advantage of test-time scaling in broad, general-domain tasks.
A good analogy for conceptualizing this multi-agent collaboration system is as a team working together to come up with the best solution to a problem that doesn’t have a predefined solution. In contrast, long-thinking can be conceptualized as a single person trained to ponder a problem for a long time, to arrive at an answer that can be checked against an answer key.
Get started with NVIDIA Llama Nemotron models
A sophisticated combination of distillation, neural architecture search, reinforcement learning, and traditional alignment strategies were used to create the best-in-class NVIDIA Llama Nemotron reasoning models. These models enable you to select right-sized models that don’t compromise capability and were constructed to retain their instruction-following and function-calling strengths, ensuring that they are set up to be force multipliers in agentic AI systems. You can leverage these models to power multi-agent collaboration systems to tackle difficult open-ended general-domain tasks.
In addition to the models being open-sourced as part of this release, a large component of the data used for each step in the training process is being released for permissive use, and the recipes (through technical reports) used to train each of the models, as well as the test-time scaling system. You can build your own custom models with both SFT and RL using NVIDIA NeMo framework.
Explore this model family and start prototyping on build.nvidia.com. For production, deploy a dedicated API endpoint on any GPU-accelerated system, backed by NVIDIA AI Enterprise, for high performance and reliability. Or, get a dedicated hosted NVIDIA NIM endpoint with a few clicks through the NVIDIA ecosystem partners including Baseten, Fireworks AI, and Together AI.
To learn more about customizing reasoning models and use cases for reasoning, check out the NVIDIA GTC 2025 session, Build Reasoning Models to Achieve Advanced Agentic AI Autonomy.







