
Multilingual large language models (LLMs) are increasingly important for enterprises operating in today’s globalized business landscape. As businesses expand their reach across borders and cultures, the ability to communicate effectively in multiple languages is crucial for success. By supporting and investing in multilingual LLMs, enterprises can break down language barriers, foster inclusivity, and gain a competitive edge in the global marketplace.
Foundation models often face challenges when dealing with multilingual languages. A majority are primarily trained on English text corpora, leading to an inherent bias towards Western linguistic patterns and cultural norms.
This results in LLMs struggling to accurately capture the nuances, idioms, and cultural contexts specific to non-Western languages and societies. Additionally, the lack of high-quality digitized text data for many low-resource languages exacerbates the resource scarcity issue, making it difficult for LLMs to learn and generalize effectively across these languages. Consequently, LLMs often fail to reflect the culturally appropriate expressions, emotional connotations, and contextual subtleties inherent in non-Western languages, leading to potential misinterpretations or biased outputs.
According to a recent Meta Llama 3 blog post, “To prepare for upcoming multilingual use cases, over 5% of the Llama 3 pretraining dataset consists of high-quality non-English data that covers over 30 languages. However, we do not expect the same level of performance in these languages as in English.”
In this post, we explore two LoRA-tuned adapters from different regions and deploy them with Llama 3 NIM so that the NVIDIA NIM performs better in Chinese and Hindi.
Using these adapters enhances the accuracy of these languages over Llama 3, as they are specifically fine-tuned on additional Chinese and Hindi text, respectively. Additionally, we use LoRA’s design to our advantage, as it captures all of the extra language information in smaller, low-rank matrices for each model.
This enables us to load a single base model with the low-rank matrices A and B for each respective LoRA-tuned variant. In this manner, it’s possible to store thousands of LLMs and run them dynamically and efficiently within a minimal GPU memory footprint.
Tutorial prerequisites
To make the best use of this tutorial, you need basic knowledge of LLM training and inference pipelines, as well as:
- Hugging Face registered user access and general familiarity with the transformers library.
- Llama3-8B Instruct NIM from the NVIDIA API catalog. Deploy it by clicking on “Run Anywhere with NIM.”
What is NVIDIA NIM?
NVIDIA NIM, part of NVIDIA AI Enterprise, is a set of easy-to-use microservices designed to speed up generative AI deployment in enterprises. Supporting a wide range of AI models, including NVIDIA AI foundation, community, and custom models, it ensures seamless, scalable AI inferencing, on-premises or in the cloud, leveraging industry-standard APIs.
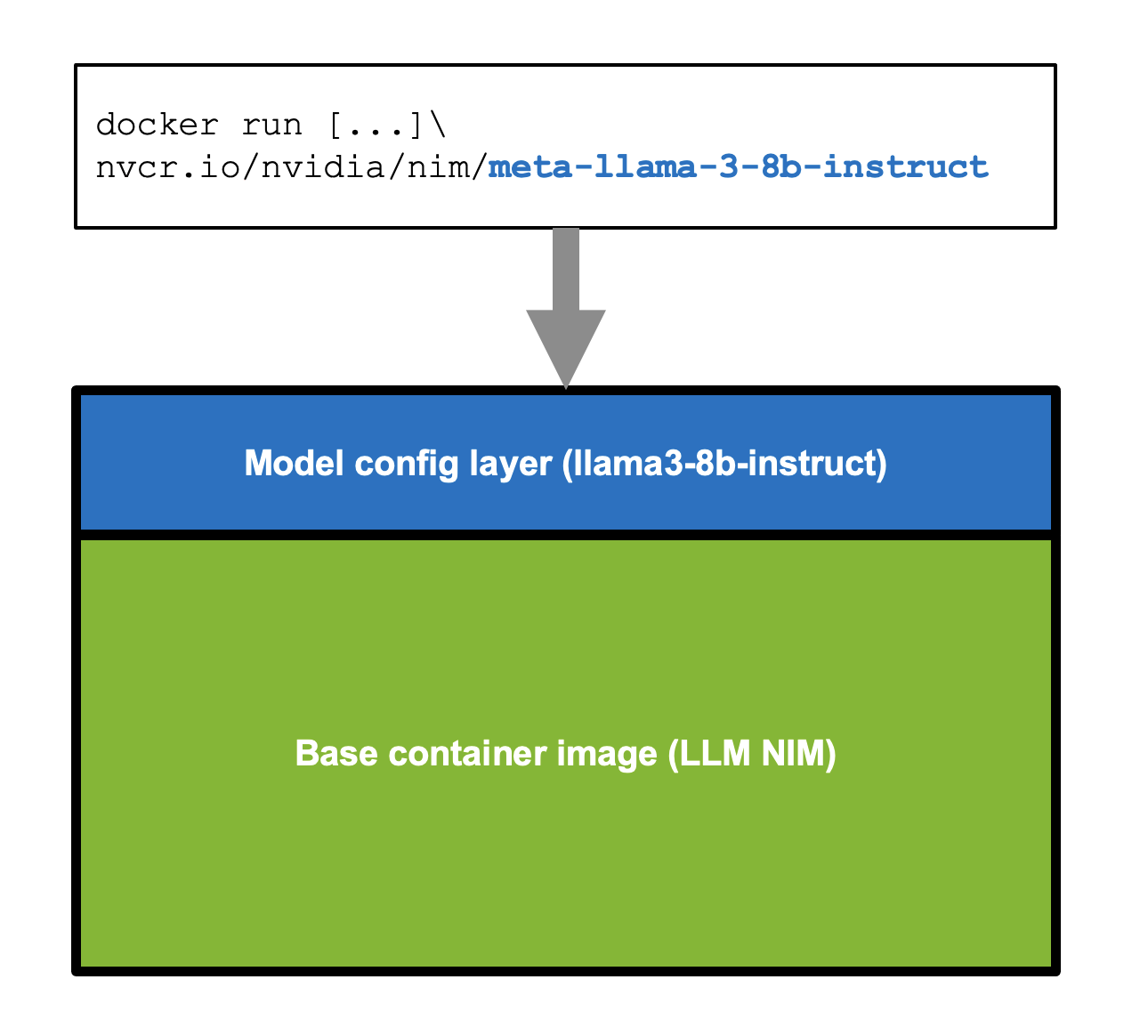
NIMs provide interactive APIs for running inference on an AI model. The container images are packaged on a per-model or model-family basis (see Figure 1). Each NIM is its own Docker container with a model and includes a runtime that runs on any NVIDIA GPU with sufficient GPU memory. Under the hood, NIMs use NVIDIA TensorRT-LLM to optimize the models, with specialized accelerated profiles optimally selected for NVIDIA H100 Tensor Core GPUs, NVIDIA A100 Tensor Core GPUs, NVIDIA A10 Tensor Core GPUs, and NVIDIA L40S GPUs.
In this blog post, we extend the base NIM with multilingual capabilities by dynamically serving multiple LoRA models, one for each language.
Basic workflow for foundation LLMs
NVIDIA NIM has a set of pre-built LLMs, which can be easily set up and served. The following command will serve the Llama-3-8b-instruct NIM using one GPU.
docker run -it --rm --name=meta-llama-3-8b-instruct \
--runtime=nvidia \
--gpus all \
-p 8000:8000 \
nvcr.io/nvidia/nim/meta-llama3-70b-instruct:1.0.0Once deployed, we can run inference using the following command:
curl -X 'POST' \
'http://0.0.0.0:8000/v1/completions' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"model": "meta/llama-3-8b-instruct",
"prompt": "Once upon a time",
"max_tokens": 64,
}'Before continuing to the next step, stop the server:
docker stop meta-llama-3-8b-instructAdvanced workflow for custom-tuned LLMs
In the case of non-Western languages, foundation models don’t always have the same level of accuracy and robustness as English, as there is considerably less training data for those languages.
In this case, parameter-efficient finetuning techniques such as LoRA can be used to adapt a pre-trained LLM to perform better for such languages.
Deploying multilingual LLMs comes with the challenge of efficiently serving hundreds or even thousands of tuned models. For example, a single-base LLM, such as Llama 2, may have many LoRA-tuned variants per language or locale. A standard system would require loading all the models independently, taking up large amounts of memory capacity.
We specifically chose LoRA as it captures all the information in smaller low-rank matrices per model, by loading a single base model together with the low-rank matrices A and B for each respective LoRA tuned variant. In this manner, it’s possible to store thousands of LLMs and run them dynamically and efficiently within a minimal GPU memory footprint. See more theoretical background on LoRA in this post.
NVIDIA NIM supports LoRA adapters trained using either HuggingFace or NVIDIA NeMo, which we will use to add more robust support for non-Western languages on top of Llama 3 8B Instruct. Check out this blog post to learn more about deploying LoRA adapters with NIM.
We now show how we can enrich NIM capabilities with multiple languages using LoRA.
Download model:
1. Install git lfs if needed
git lfs install2. Git clone Chinese and Hindi LoRa-tuned models from Hugging Face
export LOCAL_PEFT_DIRECTORY=~/loras
mkdir $LOCAL_PEFT_DIRECTORY
pushd $LOCAL_PEFT_DIRECTORY
git clone https://huggingface.co/AdithyaSK/LLama3-Gaja-Hindi-8B-Instruct-alpha
git clone https://huggingface.co/shibing624/llama-3-8b-instruct-262k-chinese-lora
popd
chmod -R 777 $LOCAL_PEFT_DIRECTORYOrganize your LoRA model store
LoRA adapters must be stored in separate directories, and one or more LoRA directories within the LOCAL_PEFT_DIRECTORY directory. The loaded adapters are automatically named after the directories they’re stored in. NVIDIA NIM for LLMs supports the NeMo and HuggingFace Transformers compatible format.
In the case of HuggingFace, the LoRA must contain an adapter_config.json file and one of {adapter_model.safetensors, adapter_model.bin} files. The supported target modules for NIM are ["gate_proj", "o_proj", "up_proj", "down_proj", "k_proj", "q_proj", "v_proj"].
The LOCAL_PEFT_DIRECTORY should be organized according to the structure below:
loras
├── llama-3-8b-instruct-262k-chinese-lora
│ ├── adapter_config.json
│ └── adapter_model.safetensors
└── LLama3-Gaja-Hindi-8B-Instruct-alpha
├── adapter_config.json
└── adapter_model.safetensorsDeploy multiple LoRA models with NIM
After setting up relevant LoRA-tuned models, we can serve the model for inference. This is similar to running the base NIM, but we now specify the LoRA directory.
export NIM_PEFT_SOURCE=/home/nvs/loras
export LOCAL_PEFT_DIRECTORY=/home/nvs/loras
export NIM_PEFT_REFRESH_INTERVAL=3600
export CONTAINER_NAME=meta-llama3-8b-instruct
export NIM_CACHE_PATH=~/nim-cache
chmod -R 777 $NIM_CACHE_PATHNIM enables loading of multiple LoRAs with different rank sizes, but sets an upper limit at 32. In the case of Hindi LoRA, we need to set the maximum rank above the default, as this particular model is tuned with a rank of 64.
export NIM_MAX_LORA_RANK=64Now serve the NIM with LoRAs. The command is similar to running the Llama 3 foundation model, but will also load all the LoRA models stored in LOCAL_PEFT_DIRECTORY.
docker run -it --rm --name=$CONTAINER_NAME \
--runtime=nvidia \
--gpus all \
--shm-size=16GB \
-e NGC_API_KEY \
-e NIM_PEFT_SOURCE \
-e NIM_PEFT_REFRESH_INTERVAL \
-e NIM_MAX_LORA_RANK \
-v $NIM_CACHE_PATH:/opt/nim/.cache \
-v $LOCAL_PEFT_DIRECTORY:$NIM_PEFT_SOURCE \
-p 8000:8000 \
nvcr.io/nim/meta/llama3-8b-instruct:1.0.0Once served, we can run inference on any of the LoRA models we stored beforehand. Check for available LoRA NIMs using the following command:
url -X GET 'http://0.0.0.0:8000/v1/models'This will output all the LoRA-tuned models we can now use for inference.
{
"Object":"list",
"Data":[
{"id":
"meta/llama3-8b-instruct","object":"model","created":1717511877,"owned_by":"system","root":"meta/llama3-8b-instruct","parent":null,"permission":[{"id":"modelperm-06017a10c1b1422cb0596baa7fec744d","object":"model_permission","created":1717511877,"allow_create_engine":false,"allow_sampling":true,"allow_logprobs":true,"allow_search_indices":false,"allow_view":true,"allow_fine_tuning":false,"organization":"*","group":null,"is_blocking":false}]},
{"id":"llama-3-8b-instruct-262k-chinese-lora","object":"model","created":1717511877,"owned_by":"system","root":"meta/llama3-8b-instruct","parent":null,"permission":[{"id":"modelperm-ad5ce194c084490ca9f8aa5f23c4fd2f","object":"model_permission","created":1717511877,"allow_create_engine":false,"allow_sampling":true,"allow_logprobs":true,"allow_search_indices":false,"allow_view":true,"allow_fine_tuning":false,"organization":"*","group":null,"is_blocking":false}]},
{"id":"LLama3-Gaja-Hindi-8B-Instruct-alpha","object":"model","created":1717511877,"owned_by":"system","root":"meta/llama3-8b-instruct","parent":null,"permission":[{"id":"modelperm-e11405b8a2f746f5b189de2766336eac","object":"model_permission","created":1717511877,"allow_create_engine":false,"allow_sampling":true,"allow_logprobs":true,"allow_search_indices":false,"allow_view":true,"allow_fine_tuning":false,"organization":"*","group":null,"is_blocking":false}]},
}Inference with NIM
Use the following cURL command for inference, specifying the name of the LoRA model:
curl -X 'POST' \
'http://0.0.0.0:8000/v1/completions' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"model": "llama-3-8b-instruct-262k-chinese-lora",
"prompt": "介紹一下機器學習",
"max_tokens": 512
}'These are the results:
{
"Id":"cmpl-92780e47ef854328a48330d6813e8a26",
"Object":"text_completion",
"Created":1717512584,
"Model":"llama-3-8b-instruct-262k-chinese-lora",
"Choices":[
{
"Index":0,
"text":"算法的基本概念和應用場景?\n\n機器學習算法是一類用于自動處理和分析數據的算法。這些算法可以學習從數據中提取模式、關系和預測性質。在這個回答中,我們將介紹機器學習算法的基本概念和應用場景。\n\n機器學習算法的基本概念:\n\n1. 訓練數據集:機器學習算法學習從數據集中獲取的樣本。\n2. 模型訓練:算法分析訓練數據集,學習模式和關系。\n3. 測試數據集:訓練后的模型評估性能在新的數據集上。\n4. 訓練和測試迭代:重復訓練和測試步驟,以提升算法的準確性。\n\n機器學習算法的應用場景:\n\n1. 數據挖掘:機器學習算法用于發現隱藏在數據中的模式和關系。\n2. 預測和預測分析:算法用于預測未來事件、趨勢和績效。\n3. recommender systems:機器學習算法推薦產品、服務或內容,基于用戶行為和偏好。\n4. 自然語言處理(NLP):機器學習算法用于理解、翻譯和生成人類語言。\n5. 圖像和視頻處理:算法用于圖像和視頻分類、識別和無人機。\n\n總之,機器學習算法是自動處理和分析數據的強大工具。它們可以用于各種應用場景,包括數據挖掘、預測分析和自然語言處理。通過 sürekli 進化和改進,機器學習算法繼續驅動各種 industries 和領域的創新。",
"Logprobs":null,
"Finish_reason":"stop",
"Stop_reason":null}],
"Usage":{
"Prompt_tokens":6,
"Total_tokens":370,
"completion_tokens":364}}Now let’s try the Hindi LoRA.
curl -X 'POST' 'http://0.0.0.0:8000/v1/completions' -H 'accept: application/json' -H 'Content-Type: application/json' -d '{
"model": "LLama3-Gaja-Hindi-8B-Instruct-alpha",
"prompt": "??? ???? ??? ??????? ???? ?? ???? ????? ???? ???? ???? ???? ????? ????? ?? ???? ????? ?????",
"max_tokens": 512
}'The following results are:
{
"Id":"cmpl-ddf3fa6e78fc4d24b0bbbc446fb57451",
"Object":"text_completion",
"Created":1717513888,
"model":"LLama3-Gaja-Hindi-8B-Instruct-alpha",
"Choices":[
{"index":0,
"text":" ????? ????? ??? ???? ?????? ??????? ?? ????????? ?? ???? ??? ???? ???? ??, ????? ?? ???, ??? ?? ?? ??? ?????? ?? ????? ???? ?? ????\n????? ???? ?????, ??????, ?? ????? ?? ????? ????????? ?? ??? ?????? ???? ?? 24 ???? ?? ???????? ???? ?? ??, ?? ?????? ???? ???????????? ?? ???????? ???? ?? ???? ???? ????? ????? ??? ?? ??? ????? ???????? ???? ????, ?? ??? ??? ????? ??? ?? ???? ??????? ?? ?????? ????? ?? ???? ?? ??? ???? ??? ?? ??? ???? ????? ??? ??, ????? ??? ?? ???? ???? ?? ?? ???? ???? ???? ??? ??? ????????? ?? ???????????? ?? ?????? ?? ?? ?????? ???? ??? ??, ?? ?? ?????? ??????????? ??? ??? ??? ??????? ?? ??????? ??????, ????????? ?? ?????? ?? ???? ?????? ??????? ?? ??????? ???? ?? ??? ?????? ???? ????, ???? ???? ??? ????????? ?? ??????? ??? ??? ????? ???\n??? ???? ????????? ????? ?? ????? ???????? ???? ????? ???, ???? ???? ???? ???? ?? ?????? ???? ?? ??????? ????? ????? ???? ?? ???? ???????? ?? ???? ??? ?? ??? ??, ?? ??_epsilon.org ?? ??? ???? ?? ??? ???? ?????? trauma ?? ??? ?? ?????? ??? ?_registers (???????, ??????, ???",
"Logprobs":null,
"Finish_reason":"length",
"Stop_reason":null}],
"Usage":{"prompt_tokens":47,"total_tokens":559,"completion_tokens":512}
}You can also use the locally-served NIM in LangChain.
from langchain_nvidia_ai_endpoints import ChatNVIDIA
llm = ChatNVIDIA(base_url="http://0.0.0.0:8000/v1", model="llama-3-8b-instruct-262k-chinese-lora", max_tokens=1000)
result = llm.invoke("介紹一下機器學習")
print(result.content)Note that as a new version of NIM is released, the most up-to-date documentation will always be at https://docs.nvidia.com/nim.
Conclusion
NVIDIA NIM enables you to seamlessly deploy and scale multiple LoRA adapters, empowering developers with the ability to add support for additional languages. Using this feature, enterprises can serve hundreds of LoRAs over the same base NIM, dynamically selecting the relevant LoRA adapter per respective language.
Getting started with NVIDIA NIM is easy. Within the NVIDIA API catalog, developers have access to a wide range of AI models to build and deploy their AI applications.
Start prototyping directly in the catalog using the graphical user interface or interact directly with the API for free. To deploy NIM inference microservices on your infrastructure, check out A Simple Guide to Deploying Generative AI with NVIDIA NIM.












