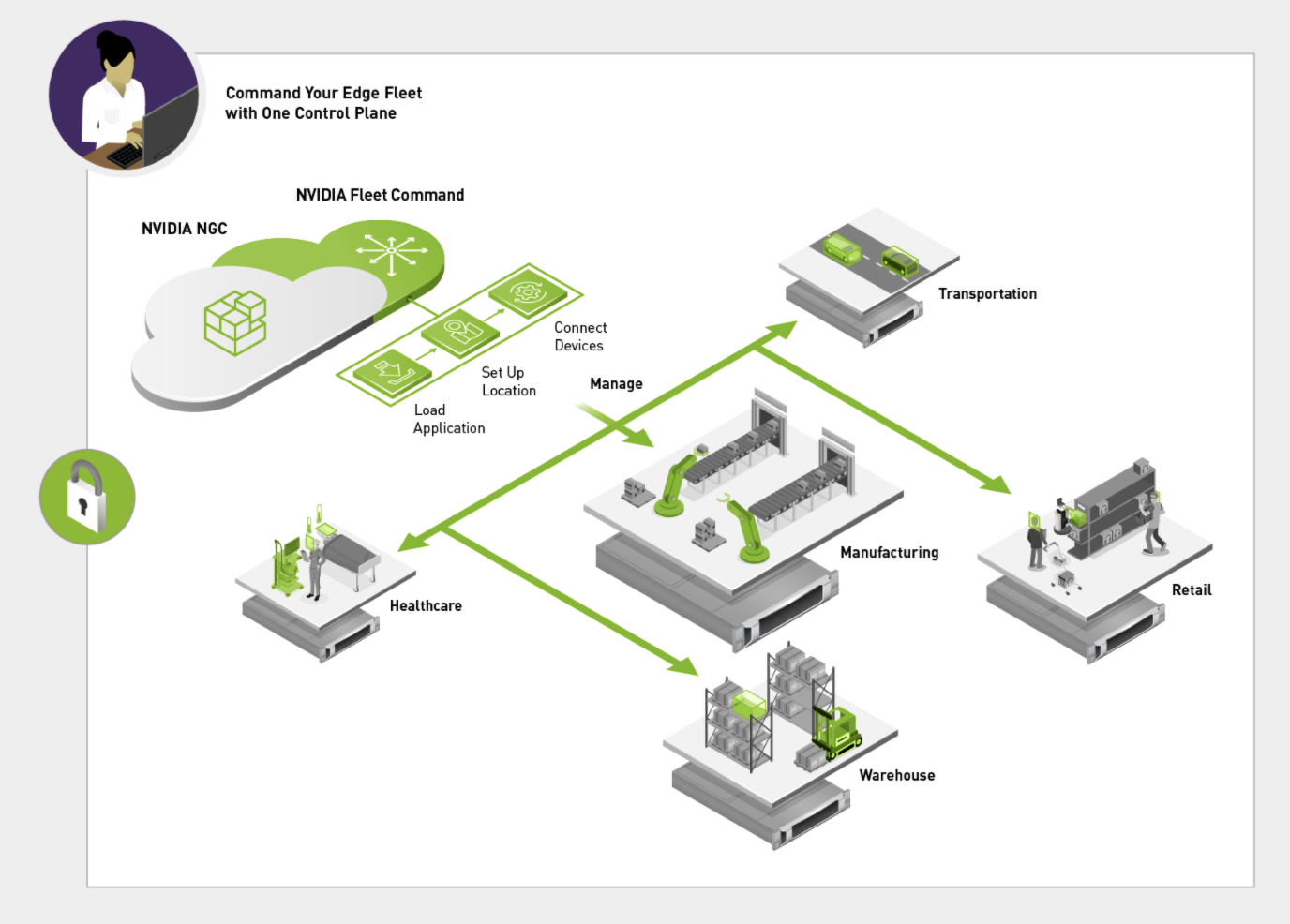
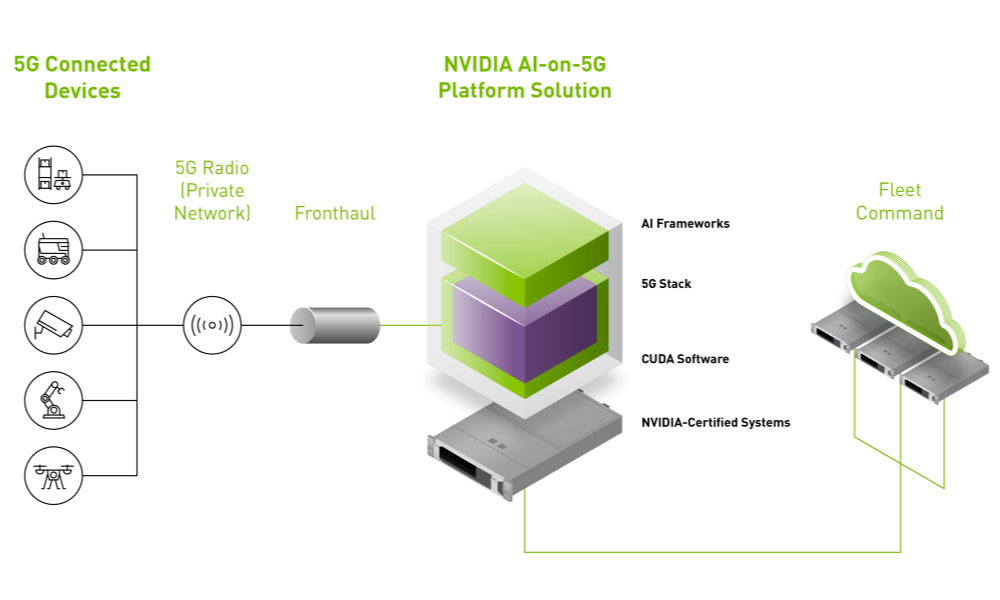
Modern expectations for agile capabilities and constant innovation—with zero downtime—calls for a change in how software for embedded and edge devices are developed and deployed. Adopting cloud-native paradigms like microservices, containerization, and container orchestration at the edge is the way forward but complexity of deployment, management, and security concerns gets in the way of scaling.
The NVIDIA EGX platform is a cloud-native Kubernetes and container-based software platform that enables you to quickly and easily provision NVIDIA Jetson-based microservers or edge IoT systems. By bringing the EGX cloud-native agility to Jetson Xavier NX edge devices, enterprises can use the same technologies and workflows that revolutionized the cloud to build, deploy, and manage edge devices at scale.
In this post, you learn about the key components of a cloud-native SW stack, how to install the EGX DIY stack on Jetson Xavier NX Developer Kit and use it to easily deploy intelligent video analytics (IVA) apps at the edge.
AI containers
Enterprises today are shifting intelligence to the edge and deploying edge infrastructures at geographically diverse points of presence (PoPs) to achieve lower network costs and better response times. Containers are enablers for agile software development and delivery and conserve bandwidth to help reduce transmission costs.
EGX runs AI containers from NGC, a GPU-optimized hub for AI and data analytics software. NGC was built to simplify and accelerate end-to-end workflows. NGC has over 150 enterprise-grade containers, 100+ models, and industry-specific SDKs and Helm charts that can be deployed on-premises, in the cloud, or at the edge. You can use the software as-is or “refine and customize,” making it easy to deploy powerful software or build customized solutions and gather insights to deliver business value.
EGX also includes access to the NGC private registry, where you can securely store your unique IP and customized solutions, share and deploy at edge, on-premises, or cloud with maximum security.
Kubernetes
Kubernetes, a container orchestration system, is one of the most active open source projects in the cloud and in enterprises today. It has become a de facto standard and an important foundation for edge computing with features such as automated container deployment and self-healing.
A core component of the EGX cloud-native software strategy is enabling GPUs with the resiliency of Kubernetes. EGX includes a GPU Operator that automates the installation and configuration of all components required to use GPUs in a Kubernetes cluster.
This greatly simplifies Day 0 IT operations and completely automates Day 1…n operations. All required components like the NVIDIA driver, NVIDIA Container Runtime, Kubernetes device plugin, and monitoring are containerized and run on Kubernetes as services, resulting in IT departments having to manage only a single image for CPU and GPU nodes.
Helm charts
Helm charts are the recommended package format for Kubernetes because they allow you to easily configure, deploy, and update applications on Kubernetes clusters with a button click and a couple of CLI commands.
NGC hosts these Kubernetes-ready Helm charts to deploy powerful third-party software. DevOps can also push and share their Helm charts on NGC, so teams can take advantage of consistent, secure, and reliable environments to speed up development-to-production cycles.
Installing the EGX 2.0 stack
The NVIDIA Jetson Xavier NX Developer Kit brings supercomputer performance to the edge, providing 21 TOPs of AI compute in 15W of power and a small form factor. Jetson Xavier NX is perfect for high-performance AI systems like commercial robots, medical instruments, smart cameras, high-resolution sensors, automated optical inspection, smart factories, and other IoT embedded systems.
Cloud-native support for Jetson Xavier NX is now also possible through this latest update to the EGX software stack. This stack on the Jetson Xavier NX Developer Kit is the NVIDIA functional- and performance-validated reference design that enables rapid, cloud-native deployment on embedded devices.
Here are the steps to install the EGX 2.0 stack on a Jetson Xavier NX Developer Kit. After a successful installation, an EGX 2.0 platform–ready Jetson Xavier NX Developer Kit includes the following:
- NVIDIA JetPack SDK 4.4
- Kubernetes version 1.17.5
- Helm/Tiller 3.1.0
- NVIDIA Container Runtime 1.0.1-dev
In this post, we used a 32-GB microSD card with the Jetson Xavier NX Developer Kit.
Setting up the Developer Kit and installing JetPack 4.4
JetPack contains the libraries, tools, and core OS for building AI applications on the Jetson platform. For more information about setting up your Jetson Xavier NX Developer Kit and installing JetPack 4.4, see Getting Started with Jetson Xavier NX Developer Kit.
Updating the Docker config
Edit the Docker daemon configuration to add the following line and save the file:
"default-runtime" : "nvidia"
Here’s an example configuration block:
$ sudo nano /etc/docker/daemon.json
{
"runtimes": {
"nvidia": {
"path": "nvidia-container-runtime",
"runtimeArgs": []
}
},
"default-runtime" : "nvidia"
}
Restart the Docker daemon:
sudo systemctl daemon-reload && sudo systemctl restart docker
Validating the Docker default runtime
Validate the Docker default runtime as NVIDIA:
$ sudo docker info | grep -i runtime
Here’s the sample output:
Runtimes: nvidia runc Default Runtime: nvidia
Installing Kubernetes version 1.17.5
Make sure that Docker has been started and enabled before starting installation:
$ sudo systemctl start docker && sudo systemctl enable docker
Install kubelet, kubeadm, and kubectl:
$ sudo apt-get update && sudo apt-get install -y apt-transport-https curl $ curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add - $ sudo mkdir -p /etc/apt/sources.list.d/
Create the kubernetes.list file:
$ sudo nano /etc/apt/sources.list.d/kubernetes.list
Add the following lines in the kubernetes.list file and save it:
deb https://apt.kubernetes.io/ kubernetes-xenial main
Install kubelet, kubectl, and kubeadm:
$ sudo apt-get update $ sudo apt-get install -y -q kubelet=1.17.5-00 kubectl=1.17.5-00 kubeadm=1.17.5-00 $ sudo apt-mark hold kubelet kubeadm kubectl
Initializing the Kubernetes cluster to run as master
Disable the swap:
$ sudo swapoff -a
Initialize the cluster:
$ sudo kubeadm init --pod-network-cidr=10.244.0.0/16
The output shows you commands to execute for deploying a pod network to the cluster, as well as commands to join the cluster.
Using the output instructions, run the following commands:
$ mkdir -p $HOME/.kube $ sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config $ sudo chown $(id -u):$(id -g) $HOME/.kube/config
Install a pod-network add-on to the control plane node. Use calico as the pod-network add-on:
$ kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
Make sure that all pods are up and running:
$ kubectl get pods --all-namespaces
Here’s the sample output:
NAMESPACE NAME READY STATUS RESTARTS AGE kube-system kube-flannel-ds-arm64-gz28t 1/1 Running 0 2m8s kube-system coredns-5c98db65d4-d4kgh 1/1 Running 0 9m8s kube-system coredns-5c98db65d4-h6x8m 1/1 Running 0 9m8s kube-system etcd-#yourhost 1/1 Running 0 8m25s kube-system kube-apiserver-#yourhost 1/1 Running 0 8m7s kube-system kube-controller-manager-#yourhost 1/1 Running 0 8m3s kube-system kube-proxy-6sh42 1/1 Running 0 9m7s kube-system kube-scheduler-#yourhost 1/1 Running 0 8m26s
The get nodes command shows that the master node is up and ready:
$ kubectl get nodes
Here’s the sample output:
NAME STATUS ROLES AGE VERSION #yournodes Ready master 10m v1.17.5
Because you are using a single-node Kubernetes cluster, the cluster can’t schedule pods on the control plane node by default. To schedule pods on the control plane node. you must remove the taint with the following command:
$ kubectl taint nodes --all node-role.kubernetes.io/master-
For more information, see Installing kubeadm.
Installing Helm/Tiller 3.1.0
Download Helm 3.1.0:
$ sudo wget https://get.helm.sh/helm-v3.1.0-linux-arm64.tar.gz $ sudo tar -zxvf helm-v3.1.0-linux-arm64.tar.gz $ sudo mv linux-arm64/helm /usr/local/bin/helm
For more information, see Helm releases and Introduction to Helm.
Validating a successful EGX 2.0 installation
To validate that the EGX stack works as expected, follow these steps to create a pod yaml file. If the get pods command shows the pod status as completed, the installation has been successful. You can also verify the successful run of the cuda-samples.yaml file by verifying that the output shows Result=PASS.
Create a pod yaml file, add the following contents to it, and save it as samples.yaml:
$ sudo nano cuda-samples.yaml
Add the following content and save it as cuda-samples.yaml:
apiVersion: v1 kind: Pod metadata: name: nvidia-l4t-base spec: restartPolicy: OnFailure containers: - name: nvidia-l4t-base image: "nvcr.io/nvidia/l4t-base:r32.4.2" args: - /usr/local/cuda/samples/1_Utilities/deviceQuery/deviceQuery
Compile the CUDA examples to validate from the pod:
$ cd /usr/local/cuda/samples/1_Utilities/deviceQuery $ sudo make $ cd ~
Create a sample GPU pod:
$ sudo kubectl apply -f cuda-samples.yaml
Check whether the samples pod was created:
$ kubectl get pods
Here’s the sample output:
nvidia-l4t-base 0/1 Completed 2m
Validate the sample pod logs to support CUDA libraries:
kubectl logs nvidia-l4t-base
Here’s the sample output:
/usr/local/cuda/samples/1_Utilities/deviceQuery/deviceQuery Starting... CUDA Device Query (Runtime API) version (CUDART static linking) Detected 1 CUDA Capable device(s) Device 0: "Xavier" CUDA Driver Version / Runtime Version 10.2 / 10.2 CUDA Capability Major/Minor version number: 7.2 Total amount of global memory: 7764 MBytes (8140709888 bytes) ( 6) Multiprocessors, ( 64) CUDA Cores/MP: 384 CUDA Cores GPU Max Clock rate: 1109 MHz (1.11 GHz) Memory Clock rate: 1109 Mhz Memory Bus Width: 256-bit L2 Cache Size: 524288 bytes Maximum Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 16384) Maximum Layered 1D Texture Size, (num) layers 1D=(32768), 2048 layers Maximum Layered 2D Texture Size, (num) layers 2D=(32768, 32768), 2048 layers Total amount of constant memory: 65536 bytes Total amount of shared memory per block: 49152 bytes Total number of registers available per block: 65536 Warp size: 32 Maximum number of threads per multiprocessor: 2048 Maximum number of threads per block: 1024 Max dimension size of a thread block (x,y,z): (1024, 1024, 64) Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535) Maximum memory pitch: 2147483647 bytes Texture alignment: 512 bytes Concurrent copy and kernel execution: Yes with 1 copy engine(s) Run time limit on kernels: No Integrated GPU sharing Host Memory: Yes Support host page-locked memory mapping: Yes Alignment requirement for Surfaces: Yes Device has ECC support: Disabled Device supports Unified Addressing (UVA): Yes Device supports Compute Preemption: Yes Supports Cooperative Kernel Launch: Yes Supports MultiDevice Co-op Kernel Launch: Yes Device PCI Domain ID / Bus ID / location ID: 0 / 0 / 0 Compute Mode: < Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) > deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 10.2, CUDA Runtime Version = 10.2, NumDevs = 1 Result = PASS
For more information about EGX SW releases and install guides, see EGX Stack – v2.0 Install Guide for Jetson Xavier NX DevKit.
Use case: Simplifying deployment of IVA apps
Build and deploy AI-powered IVA apps and services using NVIDIA DeepStream on EGX-based Jetson Xavier NX. The DeepStream SDK offers a scalable accelerated framework with TLS security to deploy on the edge and connect to any cloud.
Create a DeepStream Helm chart directory on your EGX Jetson device.
$ mkdir deepstream-helmchart
Create a template directory in /deepstream-helmchart to store the Kubernetes manifests:
$ mkdir -p deepstream-helmchart/templates
Create the Chart.yaml file, add the following content, and save it in the /deepstream-helmchart directory:
$ nano Chart.yaml apiVersion: v1 name: deepstream-helmchart version: 1.0.0 appVersion: 0.1
Create a new file as configmap.yaml in /deepstream-helmchart/templates and add the following content:
$ nano configmap.yaml apiVersion: v1 kind: ConfigMap metadata: name: deepstream-configmap data: source4_1080p_dec_infer-resnet_tracker_sgie_tiled_display_int8.txt: |- # Copyright (c) 2018 NVIDIA Corporation. All rights reserved. # # NVIDIA Corporation and its licensors retain all intellectual property # and proprietary rights in and to this software, related documentation # and any modifications thereto. Any use, reproduction, disclosure or # distribution of this software and related documentation without an express # license agreement from NVIDIA Corporation is strictly prohibited. [application] enable-perf-measurement=1 perf-measurement-interval-sec=5 #gie-kitti-output-dir=streamscl [tiled-display] enable=1 rows=2 columns=2 width=1280 height=720 gpu-id=0 #(0): nvbuf-mem-default - Default memory allocated, specific to a platform #(1): nvbuf-mem-cuda-pinned - Allocate Pinned/Host cuda memory, applicable for Tesla #(2): nvbuf-mem-cuda-device - Allocate Device cuda memory, applicable for Tesla #(3): nvbuf-mem-cuda-unified - Allocate Unified cuda memory, applicable for Tesla #(4): nvbuf-mem-surface-array - Allocate Surface Array memory, applicable for Jetson nvbuf-memory-type=0 [source0] enable=1 #Type - 1=CameraV4L2 2=URI 3=MultiURI 4=RTSP type=3 uri=file://../../streams/sample_1080p_h264.mp4 num-sources=4 #drop-frame-interval =2 gpu-id=0 # (0): memtype_device - Memory type Device # (1): memtype_pinned - Memory type Host Pinned # (2): memtype_unified - Memory type Unified cudadec-memtype=0 [sink0] enable=1 type=1 sync=0 codec=1 bitrate=4000000 rtsp-port=8554 udp-port=5400 gpu-id=0 nvbuf-memory-type=0 [sink1] enable=0 type=3 #1=mp4 2=mkv container=1 #1=h264 2=h265 codec=3 sync=0 bitrate=2000000 output-file=out.mp4 source-id=0 gpu-id=0 [sink2] enable=0 #Type - 1=FakeSink 2=EglSink 3=File 4=RTSPStreaming type=4 #1=h264 2=h265 codec=1 sync=1 bitrate=1000000 cuda-memory-type=1 # set below properties in case of RTSPStreaming rtsp-port=8554 udp-port=5400 gpu-id=0 [osd] enable=1 gpu-id=0 border-width=1 text-size=15 text-color=1;1;1;1; text-bg-color=0.3;0.3;0.3;1 font=Serif show-clock=0 clock-x-offset=800 clock-y-offset=820 clock-text-size=12 clock-color=1;0;0;0 nvbuf-memory-type=0 [streammux] gpu-id=0 ##Boolean property to inform muxer that sources are live live-source=0 batch-size=4 ##time out in usec, to wait after the first buffer is available ##to push the batch even if the complete batch is not formed batched-push-timeout=40000 ## Set muxer output width and height width=1920 height=1080 ##Enable to maintain aspect ratio wrt source, and allow black borders, works ##along with width, height properties enable-padding=0 nvbuf-memory-type=0 # config-file property is mandatory for any gie section. # Other properties are optional and if set will override the properties set in # the infer config file. [primary-gie] enable=1 gpu-id=0 model-engine-file=../../models/Primary_Detector/resnet10.caffemodel_b4_int8.engine batch-size=4 bbox-border-color0=1;0;0;1 bbox-border-color1=0;1;1;1 bbox-border-color2=0;0;1;1 bbox-border-color3=0;1;0;1 interval=0 gie-unique-id=1 nvbuf-memory-type=0 config-file=config_infer_primary.txt [tracker] enable=1 tracker-width=640 tracker-height=384 ll-lib-file=/opt/nvidia/deepstream/deepstream-5.0/lib/libnvds_mot_iou.so #ll-lib-file=/opt/nvidia/deepstream/deepstream-4.0/lib/libnvds_nvdcf.so ll-lib-file=/opt/nvidia/deepstream/deepstream-5.0/lib/libnvds_mot_klt.so #ll-config-file required for DCF/IOU only #ll-config-file=tracker_config.yml #ll-config-file=iou_config.txt gpu-id=0 #enable-batch-process applicable to DCF only enable-batch-process=1 [secondary-gie0] enable=1 model-engine-file=../../models/Secondary_VehicleTypes/resnet18.caffemodel_b16_int8.engine gpu-id=0 batch-size=16 gie-unique-id=4 operate-on-gie-id=1 operate-on-class-ids=0; config-file=config_infer_secondary_vehicletypes.txt [secondary-gie1] enable=1 model-engine-file=../../models/Secondary_CarColor/resnet18.caffemodel_b16_int8.engine batch-size=16 gpu-id=0 gie-unique-id=5 operate-on-gie-id=1 operate-on-class-ids=0; config-file=config_infer_secondary_carcolor.txt [secondary-gie2] enable=1 model-engine-file=../../models/Secondary_CarMake/resnet18.caffemodel_b16_int8.engine batch-size=16 gpu-id=0 gie-unique-id=6 operate-on-gie-id=1 operate-on-class-ids=0; config-file=config_infer_secondary_carmake.txt [tests] file-loop=1
Create a new file named deepstream.yaml in /deepstream-helmchart/templates and add the following content:
$ nano deepstream.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
annotations:
deployment.kubernetes.io/revision: "1"
generation: 1
labels:
app.kubernetes.io/name: deepstream
name: deepstream
spec:
replicas: 1
selector:
matchLabels:
app.kubernetes.io/name: deepstream
template:
metadata:
labels:
app.kubernetes.io/name: deepstream
spec:
containers:
- args:
- -c
- /opt/nvidia/deepstream/deepstream-5.0/samples/configs/deepstream-app/source4_1080p_dec_infer-resnet_tracker_sgie_tiled_display_int8.txt
command:
- deepstream-app
image: nvcr.io/nvidia/deepstream-l4t:5.0-dp-20.04-samples
imagePullPolicy: IfNotPresent
name: deepstream
ports:
- containerPort: 8554
name: http
protocol: TCP
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /opt/nvidia/deepstream/deepstream-5.0/samples/configs/deepstream-app/source4_1080p_dec_infer-resnet_tracker_sgie_tiled_display_int8.txt
name: ipmount
subPath: source4_1080p_dec_infer-resnet_tracker_sgie_tiled_display_int8.txt
dnsPolicy: ClusterFirst
imagePullSecrets:
- name: nvidia-registrykey-secret
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
volumes:
- configMap:
defaultMode: 420
name: deepstream-configmap
name: ipmount
Set the power mode and fix the clocks on Jetson devices:
$ sudo nvpmodel -m 2 $ sudo jetson_clocks
Install the DeepStream Helm chart on the Jetson device:
$ helm install --name-template deepstream deepstream-helmchart/
Verify that the DeepStream pod is up and running:
$ kubectl get pods NAME READY STATUS RESTARTS AGE deepstream-76787ffbf7-mfwk7 1/1 Running 0 1m
Check the DeepStream pod logs and see the performance:
$ kubectl logs <deepstream-podname>
Here’s the sample output:
$ kubectl logs deepstream-9f8b6b68d-rc5lq **PERF: 101.42 (100.29) 101.42 (100.29) 101.42 (100.29) 101.42 (100.29)
Clean up the DeepStream Helm chart on the Jetson device:
$ helm del deepstream
Conclusion
In this post, you learned about the key components of a cloud-native SW stack. We also showed you how to install the EGX DIY stack on the Jetson Xavier NX Developer Kit. Use it to easily deploy IVA apps at the edge.
To learn more about other Jetson Xavier NX supported containerized, pre-trained AI models, see NGC. Those models can serve as building blocks for your AI application development and help you take the next leap in edge computing today!