Since the release of ChatGPT in November 2022, the capabilities of large language models (LLMs) have surged, and the number of available models has grown exponentially. With this expansion, LLMs now vary widely in cost, performance, and specialization. For example, straightforward tasks like text summarization can be efficiently handled by smaller, general-purpose models. In contrast, complex operations such as code generation benefit from larger models with advanced reasoning capabilities and scaling test-time compute.
For AI developers and MLOps teams, the challenge lies in selecting the right model for each prompt—balancing accuracy, performance, and cost. A one-size-fits-all approach is inefficient, leading to either unnecessary expenses or suboptimal results.
To solve this, the NVIDIA AI Blueprint for an LLM router provides an accelerated, cost-optimized framework for multi-LLM routing. It seamlessly integrates NVIDIA tools and workflows to dynamically route prompts to the most suitable LLM, offering a powerful foundation for enterprise-scale LLM operations.
Key features of the LLM router include:
- Configurable: Easily integrates with foundational models, including NVIDIA NIM and third-party LLMs.
- High-performance: Built with Rust and powered by NVIDIA Triton Inference Server, ensuring minimal latency compared to direct model queries.
- OpenAI API-compliant: Acts as a drop-in replacement for existing OpenAI API-based applications.
- Flexible: Includes default routing behavior and enables fine-tuning based on business needs.
The AI Blueprint for an LLM router demonstrates how to deploy and configure the router but also provides tools for monitoring performance, customizing routing behavior, and integrating with client applications. This enables enterprises to build scalable, cost-efficient, and high-performance AI workflows tailored to their needs. In this post, we’ll provide instructions for deploying and managing the LLM router as well as an example of using the LLM router to handle multiturn conversations.
Prerequisites
To deploy the LLM router, ensure your system meets the following requirements:
- Operating System: Linux (Ubuntu 22.04 or later)
- Hardware: NVIDIA V100 GPU (or newer) with 4 GB of memory
- Software:
- CUDA and NVIDIA Container Toolkits
- Docker and Docker Compose
- Python
- API keys (see the NVIDIA NIM for LLMs Getting Started guide – Options 1 and 2):
- NVIDIA NGC API key
- NVIDIA API catalog key
Steps to deploy and manage the LLM router
Deploy the LLM router
Follow the blueprint notebook to install the necessary dependencies and run the LLM router services using Docker Compose.
Test the routing behavior
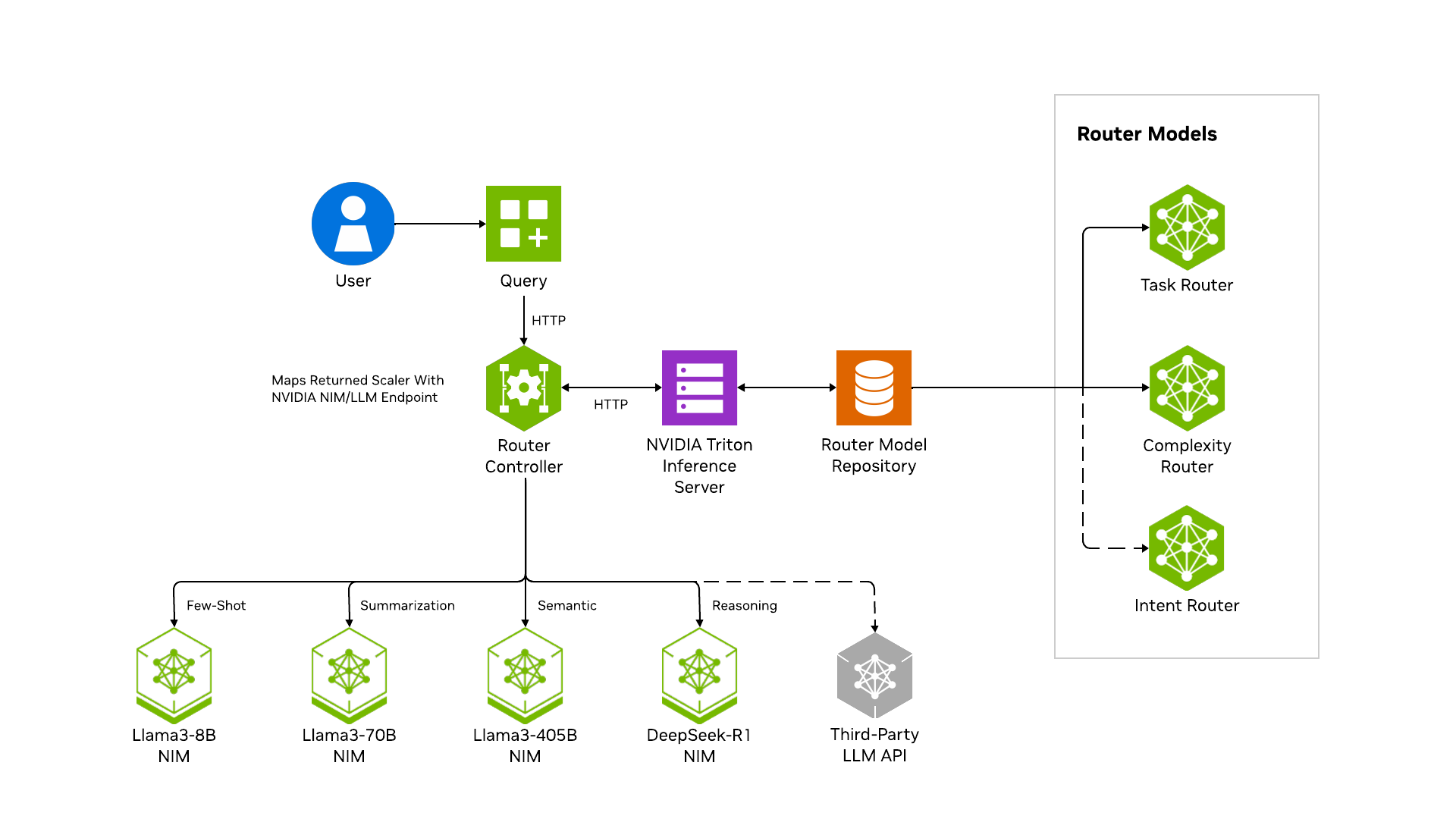
Make a request to the LLM router using the sample Python code or the sample web application. The LLM router handles the request by acting as a reverse proxy:
- LLM router receives the request and parses the payload
- LLM router forwards the parsed payload to a classification model
- Model returns a classification
- LLM router forwards the payload to a LLM based on the classification
- LLM router proxies the results from the LLM back to the user
Table 1 provides example prompts classified by task and routed to appropriate models.
| User Prompt | Task Classification | Route To |
| “Help me write a python function to load salesforce data into my warehouse.” | Code Generation | Llama Nemotron Super 49B |
| “Tell me about your return policy.” | Open QA | Llama 3 70B |
| “Rewrite this user prompt to be better for an LLM agent. User prompt: What is the best coffee recipe?” | Rewrite | Llama 3 8B |
The code generation task is the most complex and is routed to a reasoning LLM. The relatively high expense of this LLM is justified to ensure an accurate response. In contrast, the user prompt to “Rewrite the user prompt” is less complex and is accurately answered by the more cost-efficient LLM.
Customize the router
Follow the instructions in the blueprint to change the routing policy and LLMs. By default, the blueprint includes examples for routing based on task classification or complexity classification. Fine-tuning a custom classification model is demonstrated in the customization template notebooks.
Monitor performance
Run a load test by following the instructions in the blueprint’s load test demonstration. The router captures metrics that can be viewed in a Grafana dashboard.
Multiturn routing example
One of the key capabilities of the LLM router is the ability to handle multiturn conversations by sending each new query to the best LLM. This ensures that each request is handled optimally while maintaining context across different types of tasks. An example is outlined below.
User Prompt 1:
“A farmer needs to transport a wolf, a goat, and a cabbage across a river. The boat can only carry one item at a time. If left alone together, the wolf will eat the goat, and the goat will eat the cabbage. How can the farmer safely transport all three items across the river?”
Complexity Router → Chosen Classifier: Reasoning
- This first prompt requires logical reasoning to break down a classic puzzle and determine the correct steps.
- The response establishes the foundational understanding needed for further exploration.
User Prompt 2:
“Resolve this problem using graph theory. Define nodes as valid states (for example, FWGC-left) and edges as permissible boat movements. Formalize the solution as a shortest-path algorithm.”
Complexity Router → Chosen Classifier: Domain-Knowledge
- Although this prompt discusses the same problem as before, it requires a different approach: applying graph theory.
- The conversation builds on the previous reasoning but shifts to a structured mathematical framework.
- The response connects to the first answer by formalizing the farmer’s moves as a state-space search.
User Prompt 3:
“Analyze how Step 2 in your solution specifically prevents the wolf-cabbage conflict you mentioned in Step 4. Use your original step numbering to trace dependencies between these actions.”
Complexity Router → Chosen Classifier: Constraint
- Now, the user is drilling down into a specific part of the solution, focusing on constraint analysis.
- This step ties directly to the previous response, ensuring that dependencies in the problem-solving process are clear.
- Instead of solving the problem again, this response verifies correctness and logical consistency.
User Prompt 4:
“Based on the above, write a scientific fiction story.”
Complexity Router → Chosen Classifier: Creativity
- The focus shifts dramatically from structured reasoning to creative storytelling.
- However, the context of transporting items under constraints remains, ensuring the story is inspired by the logical problem discussed earlier.
- This highlights how AI can bridge analytical and imaginative tasks while preserving continuity.
User Prompt 5:
“Now summarize the above in a short and concise manner.”
Task Router → Chosen Classifier: Summarization
- The final step extracts the key insights from the entire discussion, condensing logical reasoning, mathematical modeling, dependency tracking, and storytelling into a brief, coherent summary and uses a task router instead of a complexity router.
- This demonstrates how the LLM router ensures all responses stay contextually linked while optimizing task execution.
By using different LLMs, the LLM router enables each turn of the conversation to be handled by the most appropriate model.
Get started
Implementing the NVIDIA AI Blueprint for an LLM router enables organizations to ensure high performance and accuracy in responses to specific user intents while maintaining the flexibility of plug-and-play model scaling. Cost savings are also achieved compared to the baseline approach of routing all requests to the most sophisticated model.
Overall, an LLM router deployment enables AI teams to:
- Reduce costs: By matching simple tasks with smaller, more efficient models, you significantly reduce operational costs while maintaining fast response times.
- Boost performance: More complex queries are routed to the best-fit models, ensuring the highest accuracy and efficiency.
- Scale seamlessly: Whether you need open-source models, closed-source models, or a mix of both, the blueprint provides the flexibility to scale and adapt to your organization’s needs.
Experience this blueprint now through NVIDIA Launchables. View the full source code in the NVIDIA-AI-Blueprints/llm-router GitHub repo. To learn more about router classification models, read about the NVIDIA NeMo Curator Prompt Task and Complexity Classifier.
Want to know more about AI agents? Check out these NVIDIA GTC 2025 Agentic AI sessions.