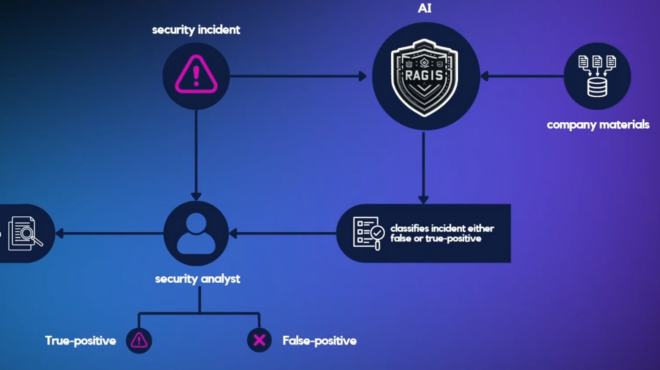
The accuracy of citations is crucial for maintaining the integrity of both academic and AI-generated content. When citations are inaccurate or wrong, they can mislead readers and spread false information. As a team of researchers from the University of Sydney specializing in machine learning and AI, we are developing an AI-powered tool capable of efficiently cross-checking and analyzing semantic citation accuracy.
Including a reference to a claim-of-fact can help readers trust its validity, strengthen the writer’s credibility, and encourage transparency by showing the source of the information. However, ensuring semantic citation accuracy—confirming that claims not only match but also faithfully represent the cited source’s conclusions without distortion or misinterpretation—is time-consuming and often requires deep subject matter understanding.
Our firsthand experience encountering the frustrations and challenges posed by inaccurate citations motivated us to develop a robust and scalable solution—a Semantic Citation Validation tool. This solution streamlines the citation verification process and enhances research integrity across various fields.
The need for citation verification has become more pressing with the increasing adoption of large language models (LLMs). Recent advances in retrieval-augmented generation (RAG) methods help reduce hallucinations in generated content. However, significant challenges remain in establishing trustworthiness without additional verification methods.
We have encountered this issue while developing the Research Impact Assessment App, which generates custom impact reports for scientific work in medicine and health. While powerful, the application currently cannot independently validate citation claims or verify their alignment with statements in original sources.
This post introduces the Semantic Citation Validation tool, which aims to accelerate validation processes, maintain high accuracy, and provide relevant contextual snippets for deeper understanding of the cited material. This tool automates citation validation by comparing statements of facts against referenced texts. Built using NVIDIA NIM microservices with additional support for mainstream LLM API providers, it combines a custom fine-tuned model trained on reference datasets with flexible deployment options.

Technical implementation and NVIDIA integration
The Semantic Citation Validation tool emerged from the Generative AI CodeFest Australia in December 2024, an event focused on practical AI tool development and skills enhancement. The implementation strategy centered on developing a microservices-based application leveraging the NVIDIA NIM ecosystem, particularly using NVIDIA NeMo Retriever for embedding and retrieval tasks, alongside fine-tuned language models for semantic analysis and verification. NeMo Retriever is a collection of microservices that provide world-class information retrieval with high accuracy and maximum data privacy.
Core NVIDIA components include the following:
- Advanced embedding and reranking: NVIDIA specialized services transform text into high-dimensional embeddings and rank passages based on claim relevance, significantly reducing false positives in content filtering through optimized semantic matching.
- LLM-powered verification: Using NVIDIA NIM for LLMs, the system performs deep semantic analysis of ranked passages, providing detailed reasoning for verification decisions that align with expert judgment.
- Model fine-tuning: To optimize accuracy and processing speed, we fine-tuned LLama 3.1 models (8B and 70B variants) using a custom dataset of citation claims, references, and verification outcomes. The dataset was derived from the top-cited publications of 2024 across a diverse range of research domains, including Medicine, Physics, Mathematics, Computer Science, Geology, and Environmental Science. Citation claims and references (from 2023 and onwards) were extracted and annotated. We also augmented the dataset with synthetic claims and annotations generated using GPT-4o. For model training we used eight NVIDIA A100 Tensor Core GPUs with 640 GB total GPU memory (provided by NVIDIA as part of the Generative AI CodeFest Australia).
Pipeline architecture
The Semantic Citation Validation tool operates through five streamlined stages:
- Input Processing: Handles citation statements and referenced documents through a robust intake system with built-in format validation and error handling. The document uploader supports text, .pdf, and .docx files.
- Document Processing: Performs format validation, parsing, and strategic chunking while generating optimized embeddings for semantic matching. It also processes the citation text into structured claims using an LLM.
- Vector Management: Implements a dual-cache architecture for document and vector storage, enabling rapid retrieval and reduced processing overhead.
- Matching and Analysis: Combines similarity matching, reranking, and LLM analysis in a multilayered approach for comprehensive verification.
- Output Generation: Produces support classification, verification reasoning, relevant snippets, and confidence scores.
The processing pipeline uses LangChain and ChromaDB for the RAG implementation and can interact with OpenAI and NVIDIA language and embedding models. Figure 2 provides an overview of the process pipeline for the Semantic Citation Validation tool.

Web app overview and key functionalities
As an initial prototype, we developed an intuitive web interface using Streamlit to make the citation validation tool easily accessible and to streamline the workflow for automated citation verification.
Users can input citation statements and a reference file directly, as shown in the example below. The system processes this information and generates three key outputs:
- Classification (shown as PARTIALLY_SUPPORTED in this case)
- Detailed reasoning for the classification (listing three specific points about the core finding, missing context, and age range in this case)
- Relevant supporting snippets from the source text
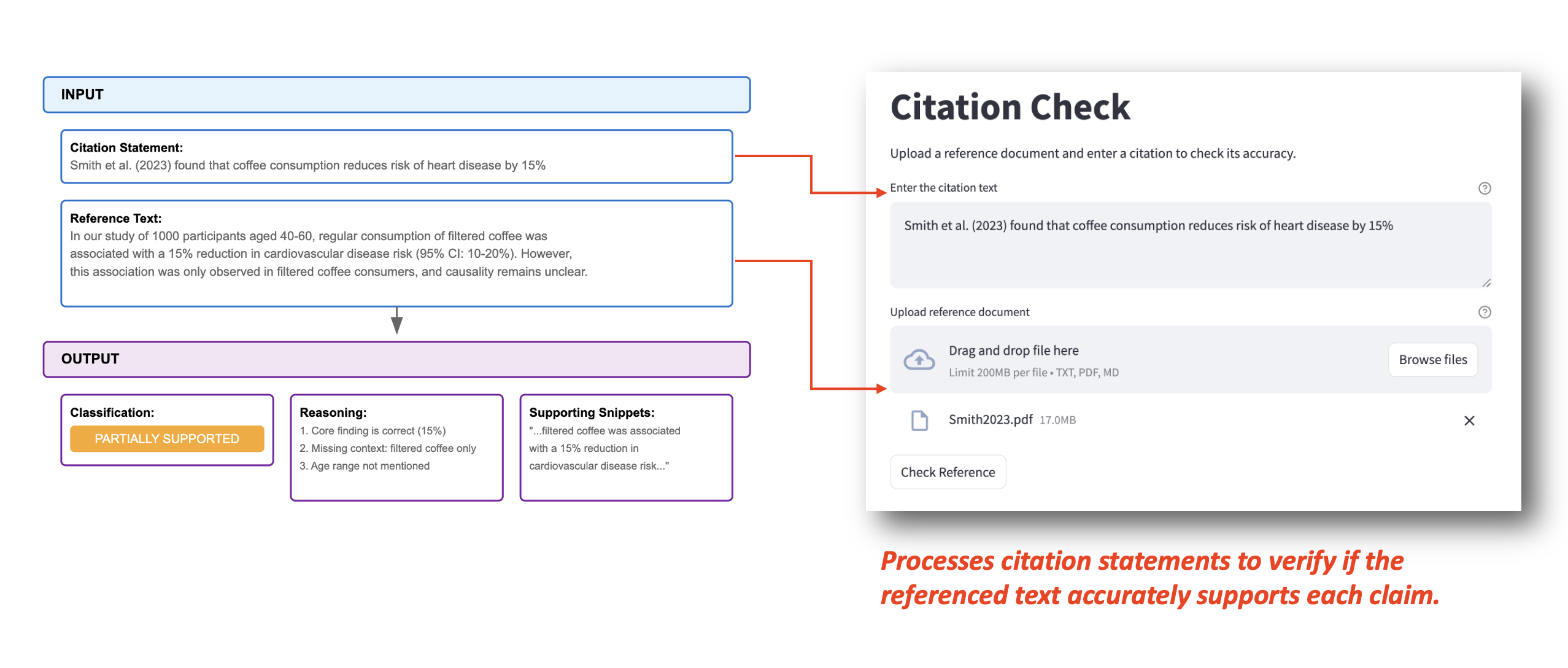
Leveraging NVIDIA microservices to implement LLMs, document retrieval, and ranking
The configuration interface showcases core NVIDIA integrations through flexible LLM provider selection, optimized embedding services, and powerful retrieval mechanisms using Chroma vector store and FlashrankRerank. The local endpoint configuration ensures secure processing of sensitive data while maintaining performance.

Accuracy classifications
The validation tool provides nuanced citation assessment through four distinct categories:
- Supported: Indicating full alignment and proper context
- Partially Supported: Showing core claims supported but missing context or nuances
- Unsupported: For claims contradicting or absent from the source
- Uncertain: For cases with ambiguous or insufficient information
The classification scheme is designed to balance granularity and simplicity, ensuring alignment with potential actions for researchers and reviewers. Supported citations require no change, partially supported ones may need minor revisions, unsupported citations require major revisions or removal, and uncertain cases warrant further review.

Reasoning and supporting evidence
The tool also provides detailed reasoning for its classification by analyzing specific gaps between the citation and source text, such as missing details, methodological nuances, contextual omissions, or potential misrepresentations of findings. Supporting evidence is presented through relevant text snippets from the reference document, complete with relevance scores, enabling users to verify the tool’s decision-making process directly.

Conclusion
The Semantic Citation Validation Tool automates citation validation by comparing statements of facts against referenced texts. Built using NVIDIA NIM microservices with additional support for mainstream LLM API providers, it combines a custom fine-tuned model trained on reference datasets with flexible deployment options. The tool performs semantic claim verification and extracts supporting evidence, classifying citations into four categories: Supported, Partially Supported, Unsupported, and Uncertain. The tool can be easily deployed as a web application, enabling systematic review of citations, reducing checking time from hours to seconds while improving research accuracy and quality.
In the future, we plan on streamlining the citation validation process. We will implement automatic citation and reference extraction from any document, along with full-text retrieval of open-source references. This enhancement will eliminate manual input requirements, significantly reducing validation time for both traditional academic content and AI-generated outputs. This will enable direct source retrieval and verification by integrating with academic databases and preprint servers.
Further development includes batch processing capabilities to handle multiple citations simultaneously, making it valuable for manuscript editing, systematic reviews, and rapid verification of AI-generated content. These improvements will transform the tool into a comprehensive solution for citation integrity, supporting researchers, editorial teams, and content creators in maintaining high standards of accuracy across both human-authored and AI-generated work. For more information and updates, visit RefCheckAI.
Explore NVIDIA NIM to accelerate your AI development and solve real-world challenges. Learn more about NIM and its capabilities to build innovative solutions like this citation validation tool.
Acknowledgments
This work was completed in part at the Generative AI Codefest, Australia, part of the Open Hackathons program. We would like to acknowledge OpenACC-Standard.org for their support. We would like to thank the Australian Government Department of Industry, Science and Resources through the National AI Centre, and the National Computational Infrastructure (NCI) for hosting the Generative AI CodeFest Australia together with NVIDIA and Sustainable Metal Cloud (SMC). The project is supported by the Sydney Informatics Hub (SIH) at the University of Sydney.