Editor’s Note: This post has been updated. Here is the revised post.
 Training deep learning models with vast amounts of data is necessary to achieve accurate results. Data in the wild, or even prepared data sets, is usually not in the form that can be directly fed into neural network. This is where NVIDIA DALI data preprocessing comes into play.
Training deep learning models with vast amounts of data is necessary to achieve accurate results. Data in the wild, or even prepared data sets, is usually not in the form that can be directly fed into neural network. This is where NVIDIA DALI data preprocessing comes into play.
There are various reasons for that:
- Different storage formats
- Compression
- Data format and size may be incompatible
- Limited amount of high quality data
Addressing the above issues requires your training pipeline provide extensive data preprocessing capabilities, such as loading, decoding, decompression, data augmentation, format conversion, and resizing. You may have used the native implementation in existing machine learning frameworks, such as Tensorflow, Pytorch, MXnet, and others, for these pre-processing steps. However, this creates portability issues due to use of framework-specific data format, set of available transformations, and their implementations. ?Training in a truly portable fashion needs augmentations and portability in the data pipeline.
The CPU bottleneck
Data preprocessing for deep learning workloads has garnered little attention until recently, eclipsed by the tremendous computational resources required for training complex models. As such, preprocessing tasks ?typically ran on the CPU due to simplicity, flexibility, and availability of libraries such as OpenCV or Pillow.
Recent advances in GPU architectures introduced in the NVIDIA Volta and Turing architectures, have significantly increased GPU throughput in deep learning tasks. In particular, ?half-precision arithmetic and Tensor Cores accelerate certain types of FP16 matrix calculations useful for training DNNs. Dense multi-GPU systems like NVIDIA’s DGX-1 and DGX-2?train a model much faster than data can be provided by the processing framework, leaving the GPUs starved for data.
Today’s DL applications include complex, multi-stage data processing pipelines consisting of ?many serial operations. To rely on the CPU to handle these pipelines limits your performance and scalability.
DALI?To the Rescue
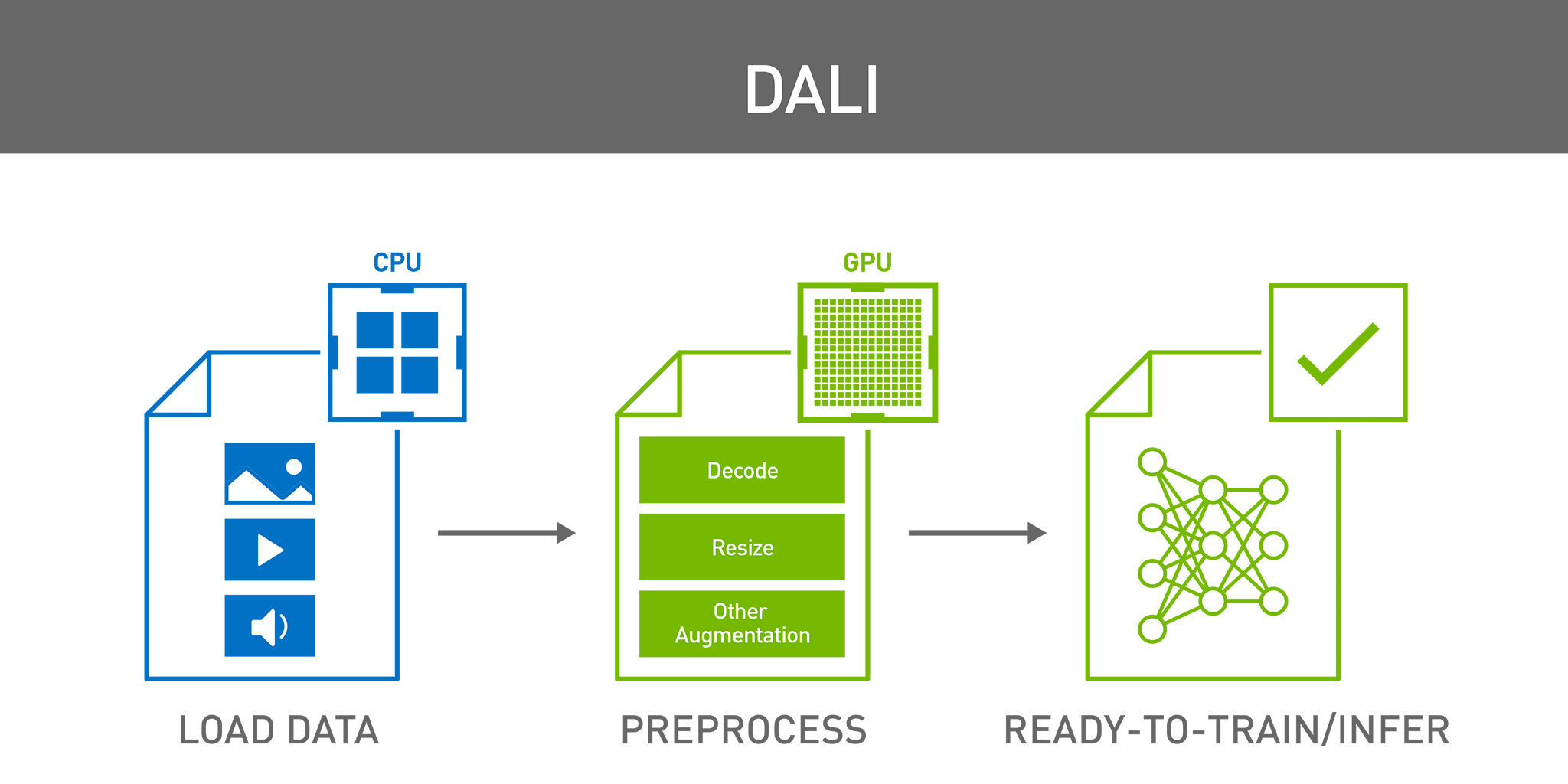
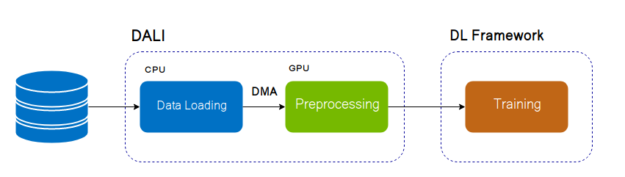
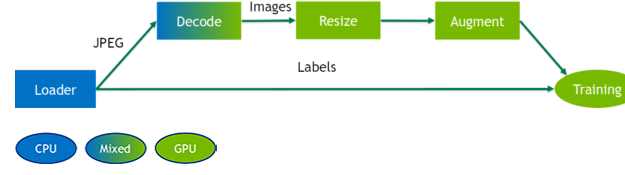
NVIDIA Data Loading Library (DALI) is a result of our efforts?find a scalable and portable solution to the data pipeline issues mentioned above. DALI is a set of highly optimized building blocks plus an execution engine to accelerate input data pre-processing?for deep learning applications, as diagrammed in figure 1. DALI provides performance and flexibility for accelerating different data pipelines.
DALI currently supports computer vision tasks such as image classification, recognition and object detection. It also supports H.264 and HVEC decoding for video data. Additional features, such as medical volumetric data and inference pre and post processing may be supported in future versions.
Since new networks and augmentations appear every day, DALI’s plugin manager provides an easy way to extend existing functionality. Custom operators?can be implemented, compiled, and loaded separately into the DALI.
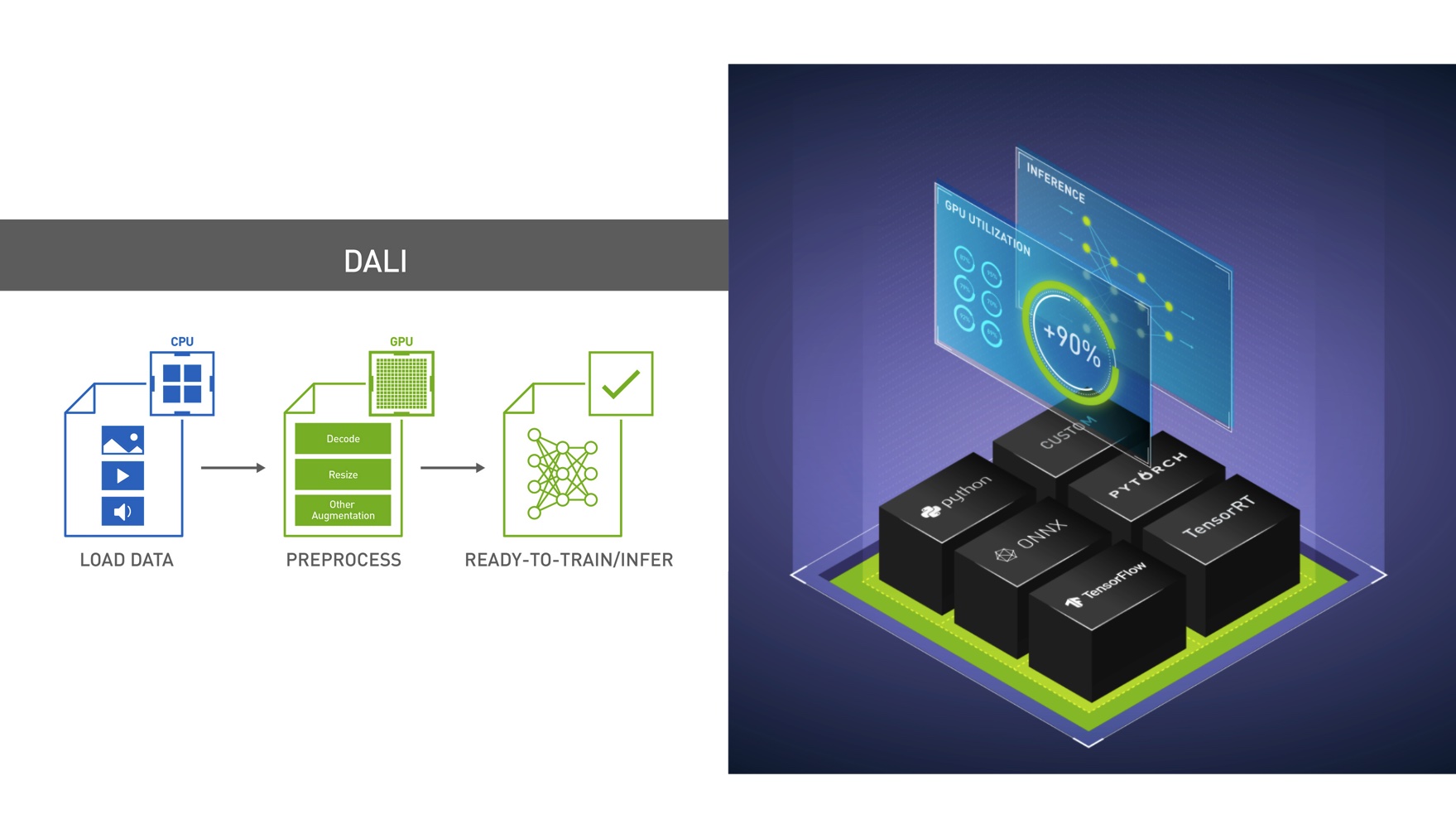
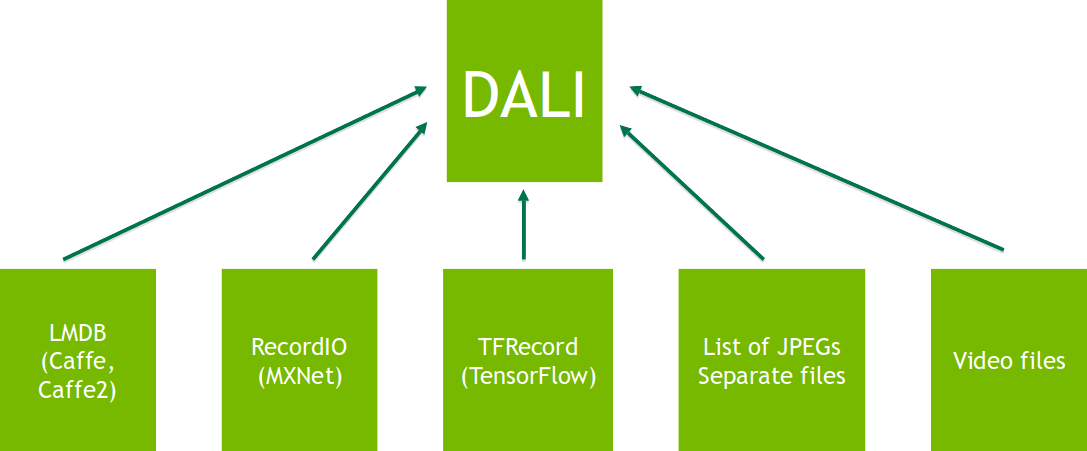
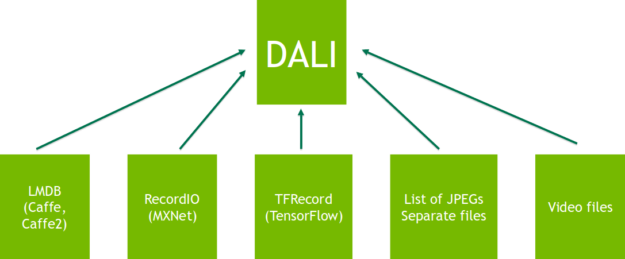
DALI provides portability of entire pipelines between different DL frameworks, as shown in figure 2. Range of reader operators allow using data containers unsupported natively by chosen DL framework. For example, you can use the LMDB data set in the MXNet or TensorFlow based networks.
DALI offers drop-in integration of your data pipeline into different Deep Learning frameworks – simple one-liner plugins wrapping DALI pipeline are available (TensorFlow, MXNet and PyTorch). In addition, you will be able to reuse pre-processing implementations between these deep learning frameworks
Lastly, since DALI is open-source, you will be able to readily customize and adapt it to suit the data pre-processing needs for a variety of training pipelines.
DALI Key features
DALI offers a simple Python interface where you can implement a data processing pipeline in a few steps:
- Select Operators from this extensive list of supported operators?
- Define the operation flow as a symbolic graph in an imperative way (as in most of the current deep learning frameworks)
- Build an operation pipeline
- Run graph on demand
- Integrate with your target deep learning framework by dedicated plugin
Let us now deep dive into the inner working of DALI, followed by how to use it.
DALI inner workings
DALI defines data pre-processing pipeline as a dataflow graph, with each node representing a data processing Operator.?DALI has 3 types of Operators as follows:
- CPU: accepts and produces data on CPU
- Mixed: accepts data from CPU and produces the output at the GPU side
- GPU: accepts and produces data on the GPU
Although DALI is developed mostly with GPUs in mind, it also provides a variety of CPU-operator variants. This enables utilizing available CPU cycles for use cases where the CPU/GPU ratio is high or network traffic completely consumes available GPU cycles. You should experiment with CPU/GPU operator placement to find the sweet spot.
For the performance reasons, DALI only transfers data from CPU->Mixed->GPU as shown in figure 3.
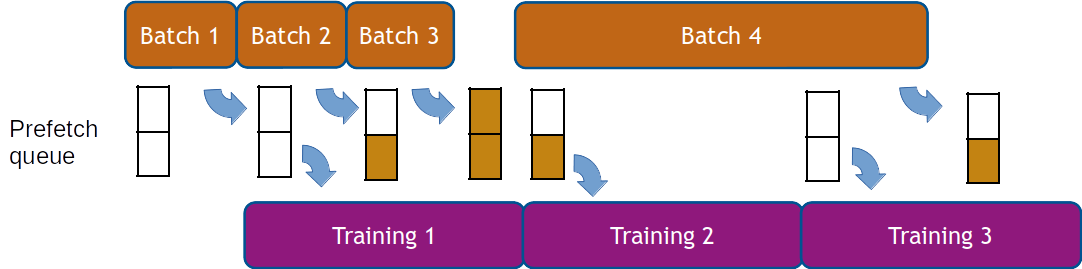
Existing frameworks offer prefetching, which calculates necessary data fetches before they’re needed. DALI prefetches?transparently,?providing?the ability to define prefetch queue length flexibly during pipeline construction, as shown in ?figure 4. This makes it?straightforward to hide high variation in the batch-to-batch processing time.
How to use DALI
As mentioned above, DALI follows a graph-based execution model. The following example shows?you how to define, build,?and run simple pipeline using?the?Python API.?
DALI Python API
The central feature?of the DALI Python API is the Pipeline?class. You need to create your own subclass of Pipeline?by instantiating?desired operators and define the connections between them.
class SimplePipeline(Pipeline): def __init__(self, batch_size, num_threads, device_id): super(SimplePipeline, self).__init__(batch_size, num_threads, device_id) self.input = ops.FileReader(file_root = image_dir) self.decode = ops.HostDecoder(output_type = types.RGB) def define_graph(self): jpegs, labels = self.input() images = self.decode(jpegs) return (images, labels)
You only need to write two methods:
__init__: Choose the operators (you can find them innvidia.dali.opsmodule). This simple pipeline uses only two operators,FileReaderto read files from the drive andHostDecoderto decode images to RGB format. You also need to pass the following parameters tosuper: batch size (Pipelinehandles batching data for you), number of worker threads you wish to use, and ID of the GPU device employed for the job.define_graph: Define computation execution by connecting operators together. Obtain images as jpegs with corresponding labels fromFileReader, pass to decoder, and return decoded data with labels as output from the pipeline.?
The next step is to create the SimplePipeline?object and build?it to actually construct?a?graph of operations.
pipe = SimplePipeline(batch_size, 1, 0) pipe.build()
By this point, the pipeline is ready to use. You can obtain batch of data by calling?the?run?method.
images, labels = pipe.run()
Randomly shuffling?the dataset?is required to make it usable for neural network training.?You?set the seed?parameter of the super?method and set random_shuffle?to true?in FileReader?to do the job:
def __init__(self, batch_size, num_threads, device_id): ? ? ? ?super(SimplePipeline, self).__init__(batch_size, num_threads, device_id, seed = 12) ? ? ? ?self.input = ops.FileReader(file_root = image_dir, random_shuffle = True) ? ? ? ?self.decode = ops.HostDecoder(output_type = types.RGB)
Now ?let’s add some actual data augmentation. We will rotate each image by random angle. For random angle generation, you can use?the?Uniform?operator, and?the?rotate?operator for the rotation:
class SimplePipeline(Pipeline): ? ?def __init__(self, batch_size, num_threads, device_id): ? ? ? ?super(SimplePipeline, self).__init__(batch_size, num_threads, device_id, seed = 12) ? ? ? ?self.input = ops.FileReader(file_root = image_dir, random_shuffle = True) ? ? ? ?self.decode = ops.HostDecoder(output_type = types.RGB) ? ? ? ?self.rotate = ops.Rotate() ? ? ? ?self.rng = ops.Uniform(range = (-10.0, 10.0)) ? ?def define_graph(self): ? ? ? ?jpegs, labels = self.input() ? ? ? ?images = self.decode(jpegs) ? ? ? ?angle = self.rng() ? ? ? ?rotated_images = self.rotate(images, angle = angle) ? ? ? ?return (rotated_images, labels)
Figure 5 shows some examples of what occurs when applying these operations.

You can look at the?Getting started example?for more information.
Frameworks integration
Seamless interoperability with different deep learning frameworks represents one of the best features of DALI. For example, if you wish to use your pipeline with PyTorch model, you can easily do so by wrapping it with the DALIClassificationIterator.
train_loader = DALIClassificationIterator( ? ? ?pipe, ? ? ?size=int(pipe.epoch_size("Reader")))
During training, you can enumerate over train_loader?and feed your model with data.
for i, data in enumerate(train_loader): ? ? ? ?images = data[0]["data"] ? ? ? ?labels = data[0]["label"].squeeze().cuda().long() ? ? ? ?# model training
If you need something more generic (such as?more outputs), DALIGenericIterator?has you covered. For more information and examples with other frameworks (MXNet and Tensorflow), take a look at the Framework integration section?of DALI docs.
Offloading computation to GPU
The last thing we introduce to SimplePipeline?is using the GPU to perform?augmentations. DALI makes this transition as smooth as possible. The only thing that changes in __init__?method is creation of the rotate?op.
self.rotate = ops.Rotate(device = "gpu")
In define_graph, you need to make sure, that inputs to rotate?reside on the GPU rather than the CPU.
rotated_images = self.rotate(images.gpu(), angle = angle)
That’s it. With those changes, SimplePipeline?performs?the rotations on the GPU. Keep in mind that resulting images are also allocated in the GPU memory, which is generally not a ?problem since you probably end up copying them to GPU memory anyway. If not, after running pipeline, you can call asCPU?on the images?object to copy them back.
For more information on how to use DALI with GPU, take a look at our augmentation gallery example.
Other examples
We prepared numerous?examples and tutorials on using?DALI in different contexts. For instance, if you would like to know how it can be integrated into proper model training, the?ResNet50 training script?in DALI docs?shows this. The documentation?covers every step you need to take to use DALI in training ResNet50 on ImageNet. It also shows?you how to spread training among multiple GPUs when using DALI.
Another example shows you how to read data in a format unsupported by DALI by implementing a custom input?with ExternalSource?operator.
DALI performance numbers
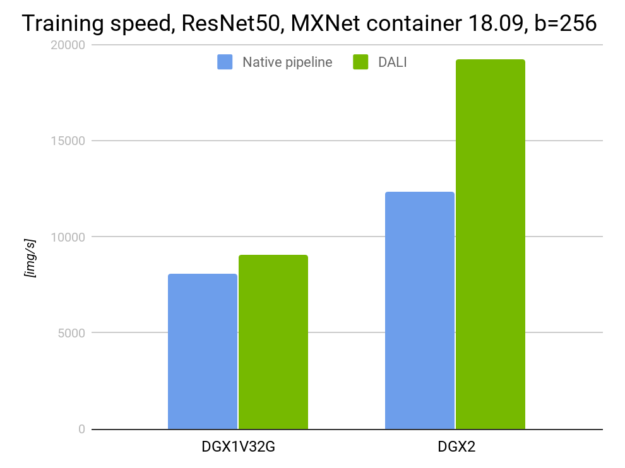
NVIDIA?showcases DALI in our?implementations of SSD and ResNet-50?since?it was one of the contributing factors in MLPerf?benchmark success.?
Figure 6 compares DALI with the RN50 network running with the different GPU configurations:
Get started with DALI today
You can download the latest version of prebuilt and tested DALI pip packages. The NVIDIA GPU Cloud (NGC) Containers for Tensorflow, Pytorch?and MXNet?have DALI?integrated. You can review the many examples?and read the latest release notes?for a detailed list of new features and enhancements.
See how DALI can help you accelerate data pre-processing for your deep learning applications. ?The source code is available on GitHub. We welcome your feedback and code contributions.
If you are interested in learning more about DALI, listen to our talk?from GTC 2018.