
As agentic AI systems evolve and become essential for optimizing business processes, it is crucial for developers to update them regularly to stay aligned with ever-changing business and user needs. Continuously refining these agents with AI and human feedback ensures that they remain effective and relevant.
NVIDIA NeMo microservices is a fully accelerated, enterprise-grade solution designed to simplify the creation and maintenance of a robust data flywheel, helping AI agents stay adaptive, efficient, and up-to-date.
In this post, I dive into a comprehensive introduction to NVIDIA NeMo microservices, offering you insights into its key capabilities to keep AI agents running at peak performance.
Need for an AI data flywheel
AI agents, unlike traditional systems, operate autonomously, reason through complex scenarios, and make decisions in dynamic environments. As these systems evolve and enterprises begin to build multi-agent systems, where AI agents integrate across platforms and collaborate with human teams to enhance operations, it becomes increasingly challenging to keep the entire system up-to-date to remain relevant and effective.
The solution lies in adopting a data flywheel strategy, where each model powering every agent is continuously adapted by learning from feedback on its interactions. A data flywheel is a self-reinforcing loop in which data from human feedback, real-world, and AI interactions continuously enhances the system, enabling it to adapt and refine decision-making (Figure 1).
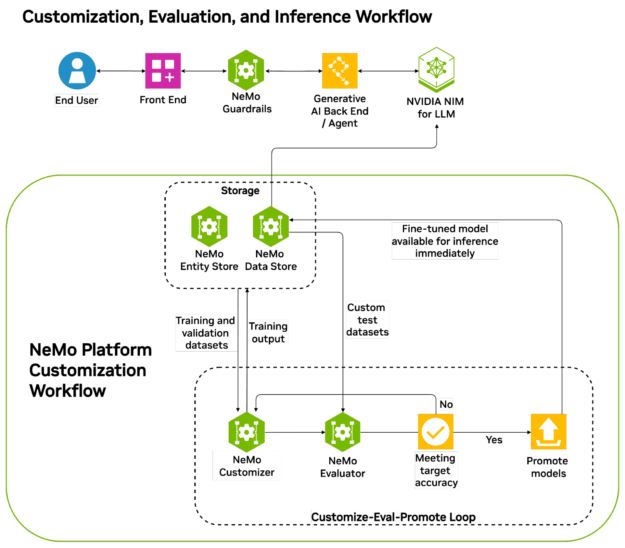
To maintain an effective AI data flywheel, it is crucial to manage the data lifecycle, establish centralized feedback systems to assess agent performance, and ensure timely updates to prevent outdated responses while reducing reliance on time-consuming human interventions.
Develop and deploy AI agents with NVIDIA NeMo microservices
NVIDIA NeMo microservices are an end-to-end, fully-accelerated platform for building data flywheels. You can simplify the development and deployment of agentic systems using industry-standard APIs and Helm charts. You can also set up data flywheels that continuously update your AI agents with the latest information, all while retaining full control over proprietary data.
In addition, you can build secure, flexible workflows that run on any GPU-accelerated environment, including on-premises, and develop high-performance, agentic systems with enterprise-grade security and support.
Simplify AI data flywheels with NeMo microservices
NeMo microservices offers the following set of powerful tools to manage the entire lifecycle of an AI agent and build efficient data flywheels to constantly improve the underlying models with fresh, relevant data to enable continuous improvement, adaptability, and compounding value in AI-driven systems:
- NeMo Curator: GPU-accelerated modules for curating high-quality, multi-modal training data.
- NeMo Customizer: High-performance, scalable microservice that simplifies the fine-tuning of large language models (LLMs) for downstream tasks.
- NeMo Evaluator: Automated evaluation of custom AI models using academic and custom benchmarks.
- NeMo Retriever: Fine-tuned microservices to build AI query engines with scalable document extraction and advanced retrieval-augmented generation (RAG) for multimodal datasets.
- NeMo Guardrails: Seamless orchestrator for building robust safety layers to ensure accurate, appropriate, and secure agentic interactions.
- NIM Operator: Kubernetes Operator that is designed to facilitate the deployment, management, and scaling of NeMo and NIM microservices on Kubernetes clusters.
Real-world example of building a data flywheel with NeMo
At NVIDIA, we use NeMo microservices to create a data flywheel that continually enhances the performance of our internal AI-powered system, the NVInfo bot. This intelligent system assists employees with tasks, information retrieval, and system navigation, boosting employee productivity.
The NVInfo bot features a router agent that directs queries to the appropriate expert agent, supported by a retrieval system using NeMo Curator, NeMo Retriever, and NVIDIA NIM, enhancing the relevance and effectiveness of the expert agents through RAG pipelines (Figure 2).
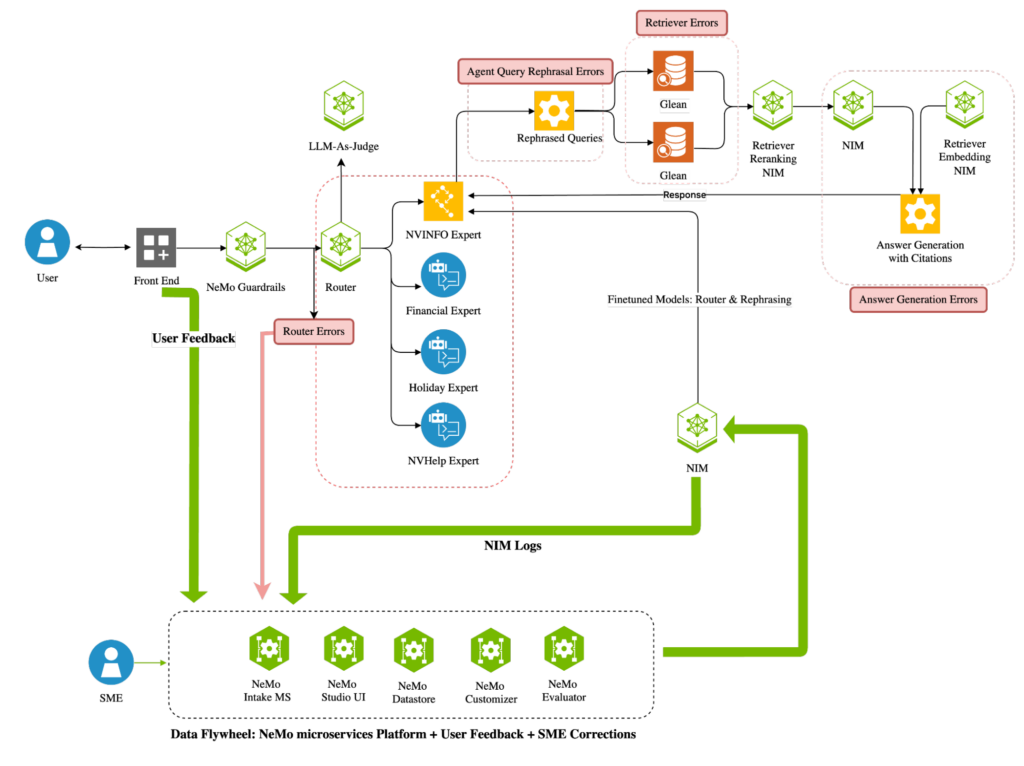
By setting up a data flywheel, powered by NVIDIA NeMo microservices, the NVInfo bot’s routing agent achieves over 96% accuracy by continuously adapting and aligning a smaller Llama-3.1-8B model with accelerated human-in-the-loop (HITL) evaluation workflows while matching the performance of a larger 70B model. This optimization enables the workload to run on a single GPU instead of two, reducing total cost of ownership (TCO) and improving latency by more than 70%.
This approach enables you to start with smaller models while achieving superior performance through continuous optimization, reaping the benefits of lower latency and lower TCO. Use NeMo Guardrails to ensure that the bot’s interactions remain focused on-topic while moderating language, relevance, and toxicity.
Fast forward data flywheel setup with NVIDIA Blueprints
NVIDIA Blueprints are predefined, customizable AI reference workflows tailored to specific use cases, designed to assist you in creating and deploying generative AI applications. They include sample applications built with NVIDIA NIM and partner microservices, reference code, customization documentation, and a Helm chart for deployment.
Soon, NVIDIA will offer the Data Flywheel Blueprint, providing a head start in building AI data flywheels with applications that link models with proprietary data and leverage it for continuous improvement. NVIDIA NeMo facilitates this process, while NVIDIA AI Foundry serves as the production environment for running the flywheel.
NeMo on LlamaStack
NVIDIA NeMo microservices will also soon be available as part of the existing NVIDIA distribution on LlamaStack, alongside NIM microservices. With LlamaStack’s unified APIs, you can seamlessly use NeMo for building generative AI applications and setting up data flywheels.
Modular approach on a unified platform
While NeMo microservices serve as an end-to-end platform for building data flywheels, you also have the flexibility to deploy the microservices individually to enhance your application.
NeMo Curator
Curating high-quality data through efficient data pipelines is crucial for developing agentic AI, as it ensures that models are trained on accurate, relevant, and diverse datasets, thereby enhancing performance and reliability.
NeMo Curator provides a collection of scalable data curation modules for curating high-quality, multi-modal datasets capable of scaling up to 100+ PB of data. The tool uses NVIDIA RAPIDS libraries such as cuDF and cuML for GPU-accelerated processing, enabling up to 16x faster text processing and 89x faster video processing compared to alternative methods (Figure 3).
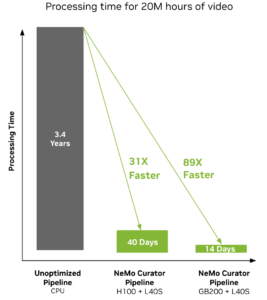
*Performance compared with ISO power consumption on 2K CPUs and 128 DGX nodes
Apart from data extraction, processing and quality assessment, NeMo Curator also supports synthetic data generation, providing prebuilt pipelines for various use cases such as prompt generation and dialogue creation. This feature enables you to augment existing datasets or create entirely new ones when real-world data is scarce.
By producing high-quality, curated datasets, NeMo Curator significantly enhances LLM training efficiency, leading to improved model accuracy and faster convergence.
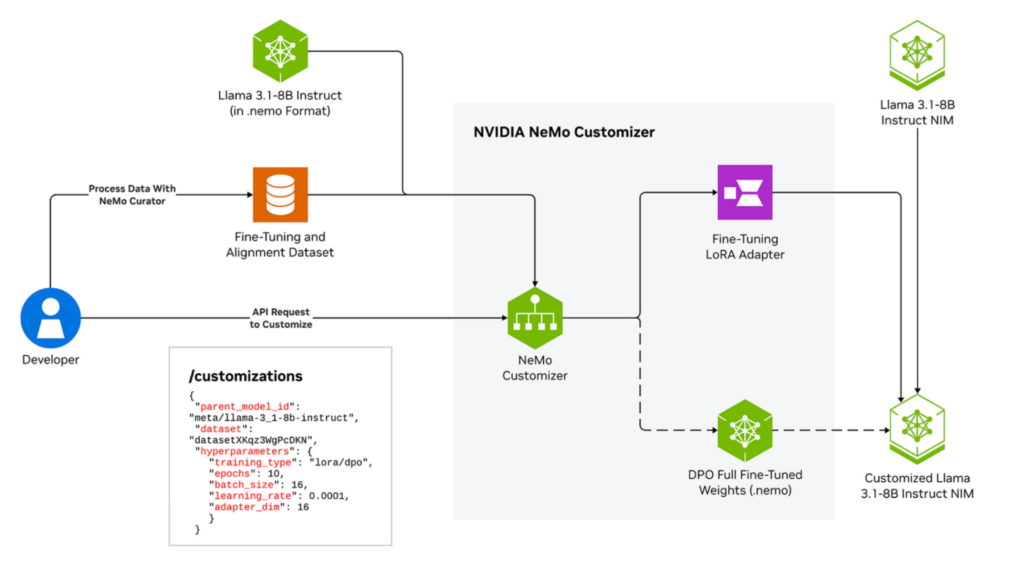
NeMo Customizer
NeMo Customizer is a scalable microservice that offers advanced, high-performance fine-tuning capabilities, including supervised fine-tuning and LoRA. It supports accelerated customizations of a wide array of LLMs with model parallelism techniques, including tensor parallelism. It supports both single-node multi-GPU as well as multi-node configurations, with the flexibility to optimize training time and throughput—resulting in 1.8x performance improvement (Figure 4).
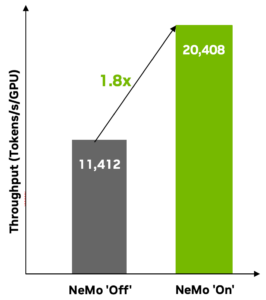
Customizing Llama-3-8B on an 8x H100 80G SXM with sequence packing (4096 pack size, 0.9958 packing efficiency).
On: customized with NeMo Customizer; Off: customized with leading market alternatives.
NeMo Customizer produces models that can be seamlessly deployed with NVIDIA NIM for efficient inference (Figure 5). With simple configuration through Helm charts, you can fine-tune with a single API call, ensuring easy development and deployment across both on-premises and cloud environments using Kubernetes, Slurm, as well as a standalone Docker-only setup.
NeMo Evaluator
Continuous and consistent evaluation is crucial to keep agents performing at their best. This not only requires model and pipeline evaluations at development but also in production as evaluation benchmarks get stale.
NeMo Evaluator addresses this need by providing a flexible, scalable solution for evaluating LLMs, retrieval models, RAG, and agent pipelines. It supports automated evaluations of custom and 20+ industry-standard benchmarks including MMLU, GPQA, AIME, and BBH (Hard).
NeMo Evaluator ensures efficient and consistent evaluations across teams, for repeated tasks by using sharable config files (Figure 6). It enables you to run evaluations at scale, anywhere, with complete data control—streamlining multi-step evaluation processes into a single API call using the Evaluator microservice, replacing OSS alternatives.

By streamlining the evaluation process, NeMo Evaluator empowers organizations to optimize model performance and establish efficient data flywheels.
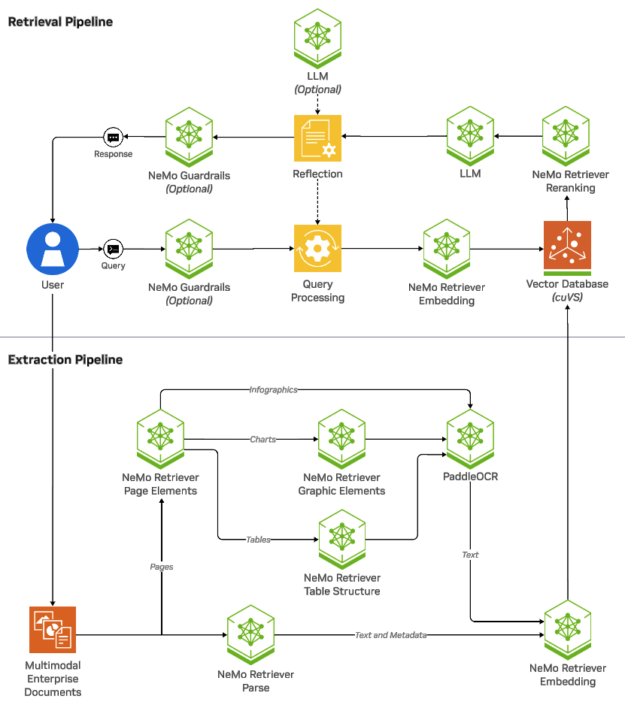
NeMo Retriever
Efficient data retrieval is a cornerstone of maintaining an effective data flywheel, ensuring AI agents continuously learn and improve by accessing the most relevant and up-to-date information. NeMo Retriever offers accelerated AI-powered systems for efficient multi-modal data extraction and retrieval to deliver precise, contextually relevant responses.
With state-of-the-art extraction, embedding, and reranking NIM microservices, NeMo Retriever improves retrieval accuracy and throughput, while offering faster, scalable, and optimized performance.
In addition to enabling multilingual and cross-lingual question-answering retrieval, NeMo Retriever enhances storage efficiency with its dynamic length– and long-context support, reducing storage requirements by 35%, and lowering TCO without affecting retrieval speed. By using GPUs to accelerate indexing, you can also increase indexing throughput enabling you to scale RAG operations quickly and cost-effectively.?
Try NeMo Retriever today from the NVIDIA API Catalog.
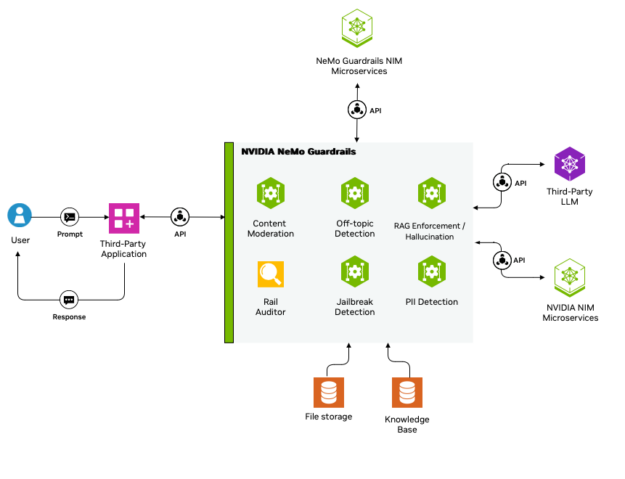
NeMo Guardrails
With AI agents driving critical business operations including decision making and customer interactions, ensuring that AI models remain safe and aligned with organizational policies is essential.
NeMo Guardrails lets you easily define, orchestrate and enforce AI guardrails in agentic AI applications, detecting up to 99% of policy violations with only a sub-second latency trade-off. It enforces various safety measures such as content moderation, off-topic dialogue moderation, hallucination reduction, jailbreak detection, and protection of personally identifiable information (PII).
NeMo Guardrails enables the addition of programmable safety layers throughout the AI interaction process, making it easy to integrate these controls into applications, including input, dialog, retrieval, execution, and output rails to ensure alignment with safety expectations and policies.
NeMo Guardrails scales seamlessly to support multiple applications with diverse guardrail configurations. It integrates with third-party and community safety models as well as the NemoGuard JailbreakDetect, Llama 3.1 NemoGuard 8B ContentSafety, and Llama 3.1 NemoGuard 8B TopicControl NVIDIA models for highly specialized, robust protections..
NIM Operator
NeMo and NIM microservices can be deployed individually using containerized Kubernetes distributions and Helm charts. However, when multiple NIM and NeMo microservices are combined to create sophisticated agentic systems, such as the NVInfo Bot, managing the end-to-end lifecycle of these microservices can present major challenges for cluster administrators and developers.
The NVIDIA NIM Operator streamlines AI inference workflow orchestration with Kubernetes-native Operators and Custom Resource Definitions (CRDs), enabling automated deployment, lifecycle management, intelligent model pre-caching for reduced latency, and simplified auto-scaling. By eliminating infrastructure complexities, it enables you to focus on innovation.
Get started with NeMo microservices
As AI continues to transform industries, the importance of keeping AI agents updated and effective will only increase. NVIDIA NeMo microservices enables your organization to set up a data flywheel to maximize the performance of your agentic AI systems by continuous adaptation while offering the flexibility to run anywhere with greater security, privacy, control, and integration.
Sign up to get notified when the NVIDIA NeMo microservices are available for download and watch the Building Scalable Data Flywheels for Continuously Improving AI Agents GTC session to learn more.







