
As AI capabilities advance, understanding the impact of hardware and software infrastructure choices on workload performance is crucial for both technical validation and business planning. Organizations need a better way to assess real-world, end-to-end AI workload performance and the total cost of ownership rather than just comparing raw FLOPs or hourly cost per GPU. Achieving optimal AI performance requires more than just powerful GPUs. It demands a well-optimized platform, including infrastructure, software frameworks, and application-level enhancements.
When assessing AI performance, ask these key questions: Is your implementation correct, or are there errors slowing you down compared to reference architectures? What size cluster is optimal? What software framework choices will optimize your time to market? Traditional chip-level metrics are insufficient for this task, leading to underutilization of investments and missed efficiency gains. Measuring the performance of your AI workload and infrastructure is critical.
This post introduces NVIDIA DGX Cloud Benchmarking, a suite of tools that assesses training and inference performance across AI workloads and platforms, accounting for infrastructure software, cloud platforms, and application configurations, not just GPUs. This post details the capabilities and applications of DGX Cloud Benchmarking, showing results with improvements in both time to train and cost to train.
With DGX Cloud Benchmarking, NVIDIA aims to provide a standardized and objective means of gauging platform performance, similar to NVIDIA’s approach to providing objective and relevant perf on its own hardware and infrastructure.
Benchmarking requirements for TCO optimization
After extensive testing, the data our team has collected indicates consistent patterns regarding time and cost in relation to GPU count, data precision, and framework. Organizations can leverage this data to explore trade-offs and accelerate their decisions and AI development time.
GPU count
Scaling GPU count in AI training clusters can significantly reduce total training time without necessarily increasing costs. While adding more GPUs can get AI work done faster, teams should explore the relationship between scaling and project cost and associated trade-offs.
For example, when training Llama 3 70B, you can get up to a 97% reduction in the time to train 1 trillion tokens (115.4 days → 3.8 days) for a cost increase of only 2.6%.
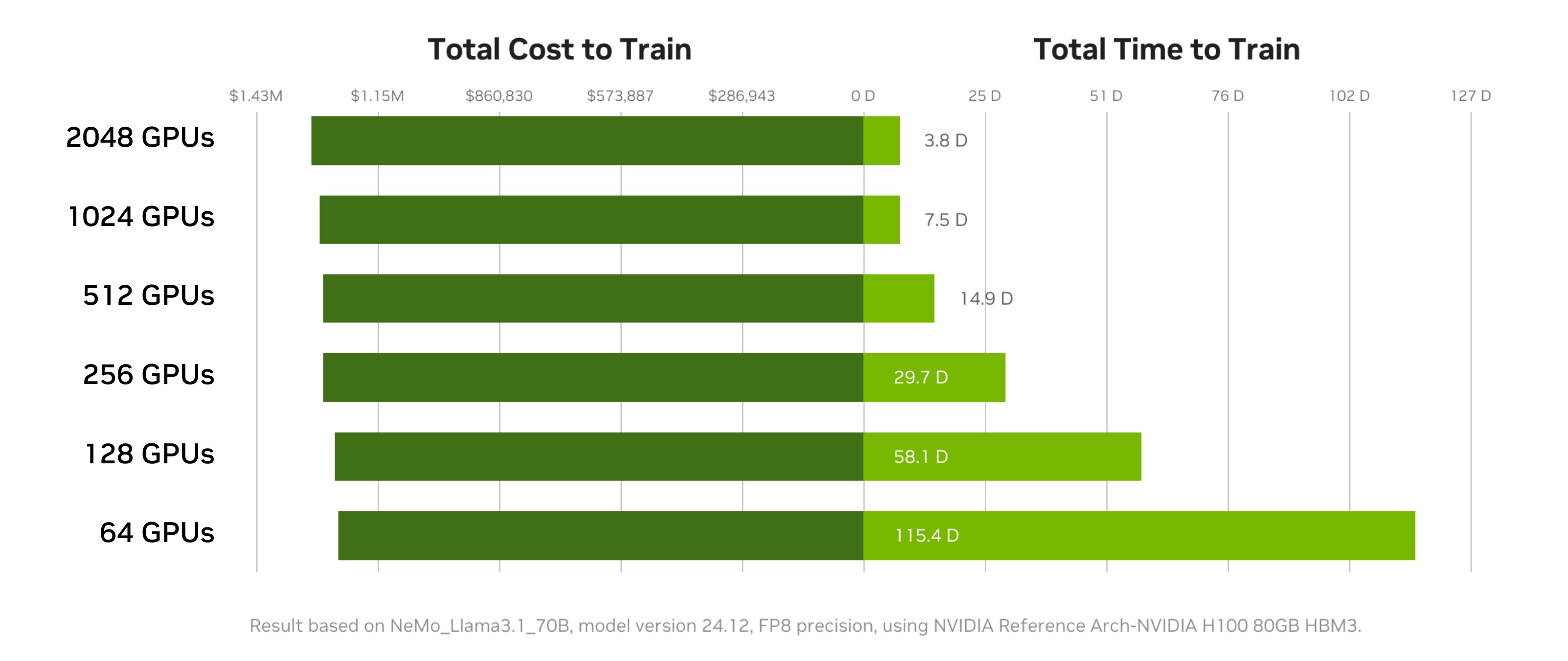
Increasing GPU count offers flexibility in workload parallelization, enabling faster iteration cycles and more rapid hypothesis validation. Training at larger scale can accelerate overall AI development timelines and developer velocity. When an organization can secure additional GPUs, they can potentially complete training jobs in less time without a proportional increase in total cost. And completing training work sooner also means faster time to market where the trained model can be deployed to generate value for your organization.
While perfect linear scaling is rarely achieved in practice, well-optimized AI workloads can come very close. The slight deviation from perfect linearity at higher GPU counts is typically due to increased communication overhead. By scaling GPU counts strategically, teams can optimize based on project goals, available resources, and priorities.
Using the NVIDIA DGX Cloud Benchmarking Performance Explorer, users can identify the ideal GPU count that minimizes both total training time and costs. The objective is to identify the right number of GPUs for a given workload that maximizes throughput and minimizes expenses—across projects and teams.
Precision
Using FP8 precision instead of BF16 can significantly increase throughput and cost-efficiency of AI model training. Using FP8 precision in training can accelerate model time to solution. This lowers the total cost to train the model due to higher math or communication throughput and lower memory bandwidth requirements. FP8 precision can also enable larger models to be trained on fewer GPUs.
Migrating AI workloads to the lowest precision type supported by your platform can lead to significant savings. Figure 2 shows that FP8 enables greater throughput (tokens/second) than BF16 on NVIDIA Hopper architecture GPUs.
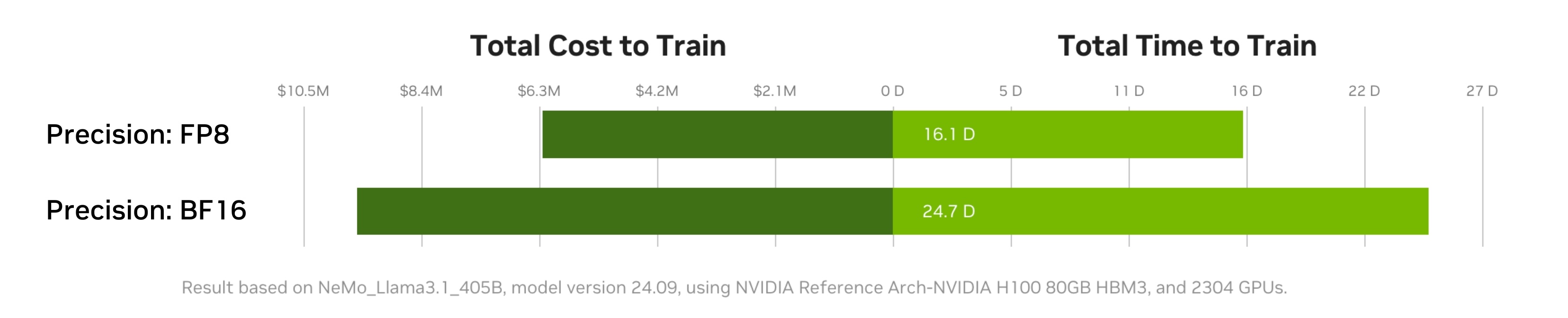
Training in FP8 introduces challenges, however, such as a narrower dynamic range. These can cause instability or divergence. To mitigate these challenges, specialized techniques to identify operations that can be executed with FP8—to provide per-tensor or sub-block scaling for conversions between BF16 and FP8—are required to maintain numerical stability. In addition, features like Transformer Engine in the Hopper and Blackwell architectures can help developers use FP8 selectively on a per-layer basis, using reduced precision only where it will not adversely affect accuracy.
Beyond throughput during training work, training a model in FP8 can additionally reduce inference costs since the model can be deployed directly for FP8 inference. Still, models trained in BF16 can later be quantized to FP8/INT8 using quantization-aware training (QAT) or post-training quantization (PTQ), enabling similar inference performance benefits.
The DGX Cloud Benchmarking Recipes provide tuning best practices for maximizing delivered platform performance with FP8 precision and example baseline results for comparison.
Framework
Selecting the right AI framework can significantly improve training speed and drive down cost, even with identical models and hardware configurations. The choice of framework affects performance due to differences in:
- Workload infrastructure fingerprint: How the framework interacts with the underlying infrastructure
- Communication patterns: The efficiency of data exchange between nodes
- Continuous optimization efforts: Framework developers continually improve performance through updates
To maximize performance, it’s crucial to choose a framework that aligns with the evolving AI ecosystem and benefits from ongoing optimizations. Framework optimization over time can significantly enhance overall platform performance and improve overall TCO.?
As shown in Figure 3, adopting the latest versions of the NVIDIA NeMo Framework can significantly increase training throughput. For example, in 2024, NeMo software optimization resulted in a 25% increase in overall platform performance–and a proportional cost savings to users–due to deep hardware and software co-engineering.

NVIDIA offers expert guidance for optimizing framework configurations. NVIDIA Performance Architects can work directly with teams to benchmark workloads on DGX Cloud infrastructure, analyze results, and recommend adjustments tailored to specific workloads. Reach out to start a collaboration.
Ecosystem collaboration and future outlook
By leveraging DGX Cloud Benchmarking Recipes, NVIDIA characterizes real user workloads to ensure optimizations are grounded in practical scenarios. Continuous performance assessment, beyond initial infrastructure validation, ensures that delivered throughput closely matches theoretical specifications. Early adopters of these performance recipes include leading cloud providers AWS, Google Cloud, Microsoft Azure, and Oracle Cloud and NVIDIA cloud partners CoreWeave, Crusoe, and Nebius.
DGX Cloud Benchmarking is designed to evolve alongside the rapidly advancing AI industry. Regular updates incorporate new models, emerging hardware platforms, and innovative software optimizations.This continuous evolution ensures that users always have access to the most relevant and up-to-date performance insights, which is crucial in an industry where technological advancements occur at an unprecedented pace.
Get started
With DGX Cloud Benchmarking, organizations can rely on standardized, objective metrics to assess AI platform efficiency. Whether you’re an AI development team scoping your next project or an IT team seeking to validate infrastructure performance, DGX Cloud Benchmarking provides the tools you need to unlock peak AI performance.
Explore DGX Cloud Benchmarking to characterize your platforms. Get started with the LLM Benchmarking Collection to quantify trade-offs across precision, cluster scale, and more. Join us at NVIDIA GTC 2025 to talk benchmarking and explore DGX Cloud Benchmarking.?












