The growing volume and complexity of medical data—and the pressing need for early disease diagnosis and improved healthcare efficiency—are driving unprecedented advancements in medical AI. Among the most transformative innovations in this field are multimodal AI models that simultaneously process text, images, and video. These models offer a more comprehensive understanding of patient data than traditional, single-modality systems.
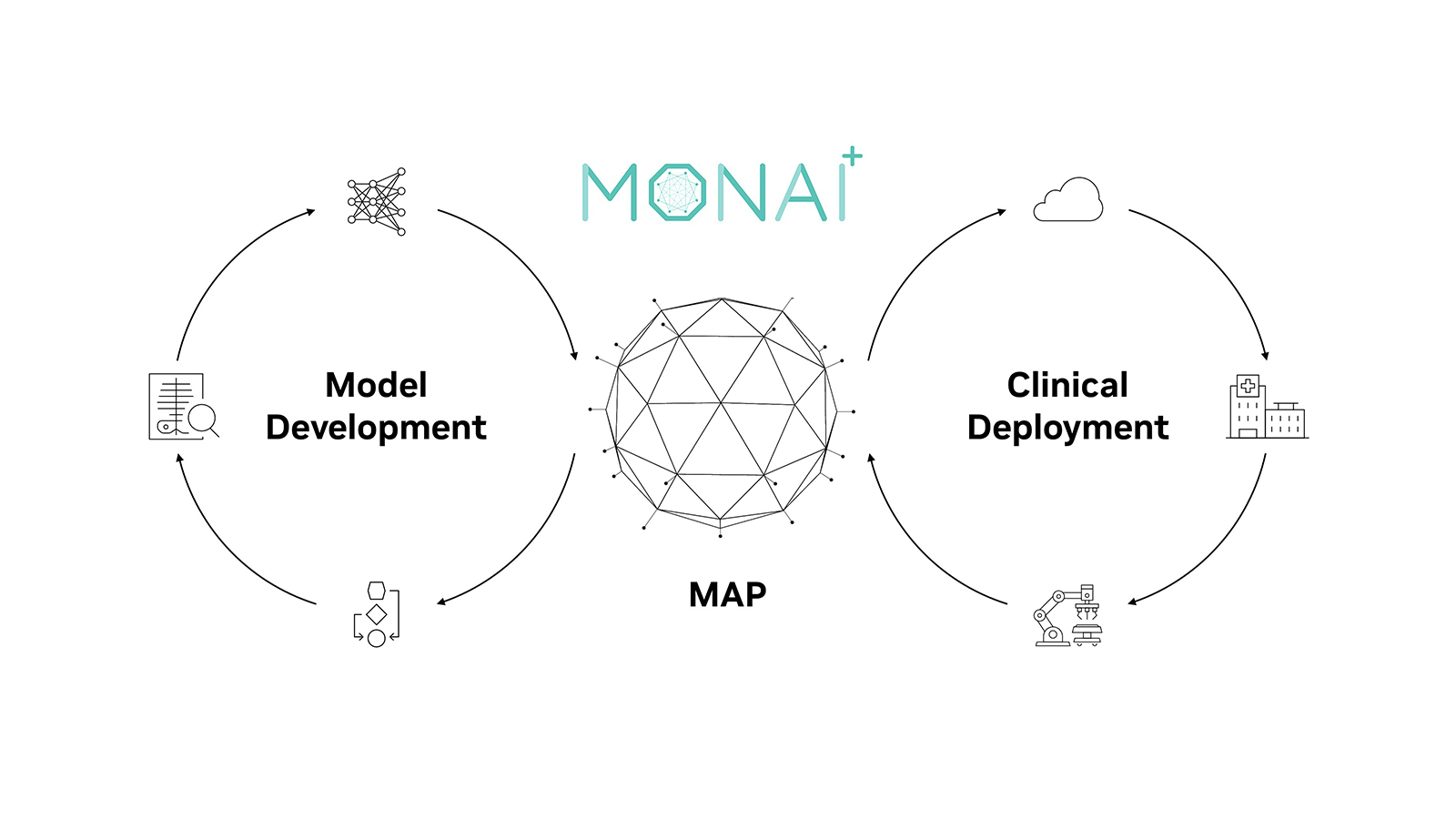
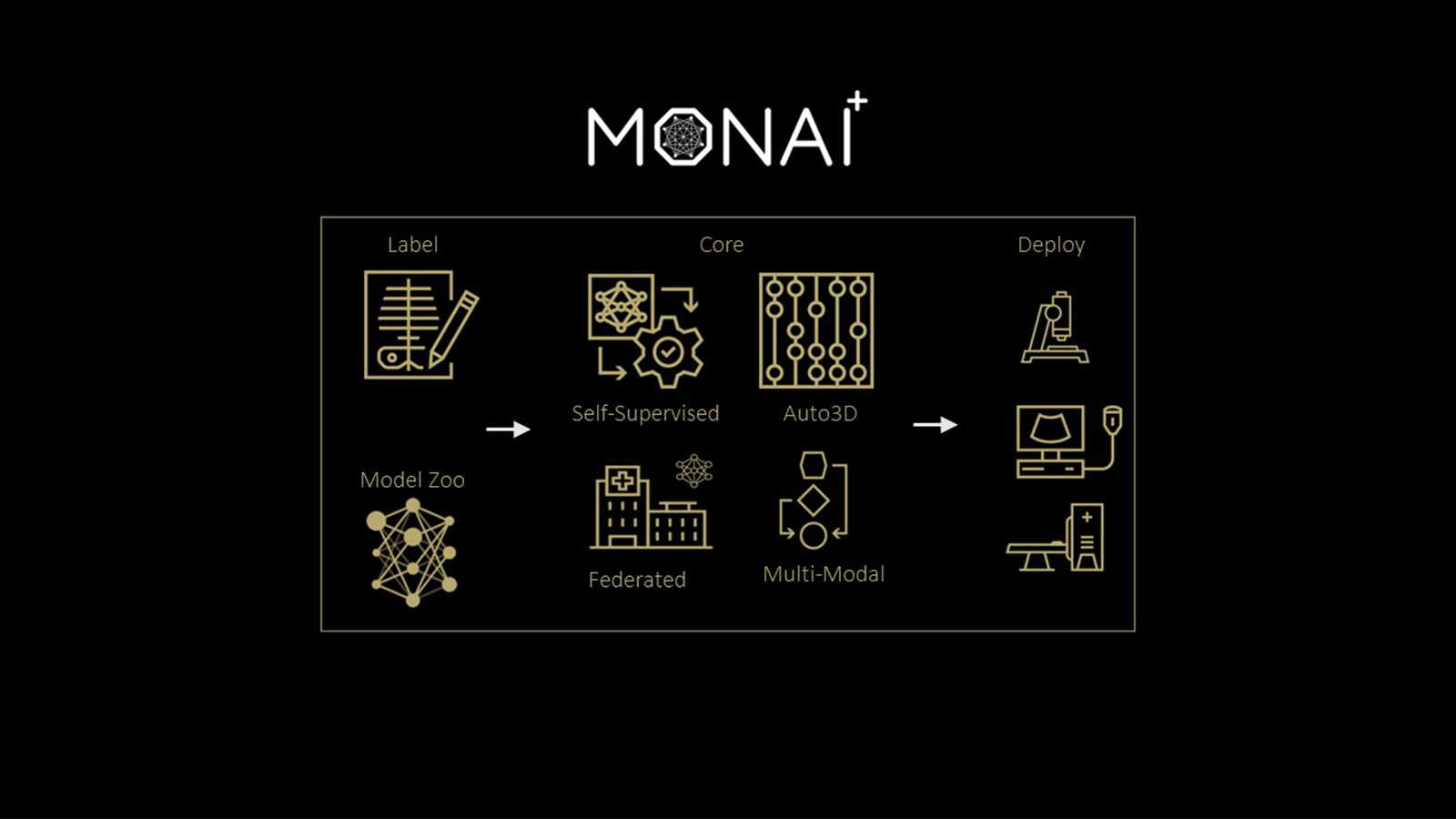
MONAI, the fastest growing open-source framework for medical imaging, is evolving to integrate robust multimodal models that are set to revolutionize clinical workflows and diagnostic precision. Over the past five years, MONAI has become a leading medical AI platform and the de facto framework for imaging AI research. It has more than 4.5 million downloads and appears in more than 3,000 published papers.
This post explains how MONAI is leveraging advanced agentic AI (autonomous, workflow-driven reasoning) to expand beyond imaging to a multimodal ecosystem. This ecosystem integrates diverse healthcare data—from CT and MRI to EHRs and clinical documentation—to drive research development and innovation in radiology, surgery, and pathology domains.
MONAI Multimodal: Bridging healthcare data silos
As medical data becomes more varied and complex, the need for comprehensive solutions that unify disparate data sources has never been greater. MONAI Multimodal represents a focused effort to expand beyond traditional imaging analysis into an integrated research ecosystem. It combines diverse healthcare data—including CT, MRI, X-ray, ultrasound, EHRs, clinical documentation, DICOM standards, video streams, and whole slide imaging—to enable multimodal analysis for researchers and developers.
Key enhancements include:
- Agentic AI Framework: Uses autonomous agents for multi-step reasoning across images and text
- Specialized LLMs and VLMs: Tailored models designed for medical applications that support cross-modal data integration
- Data IO components: Integrates diverse data IO readers including:
- DICOM for medical imaging (CT and MRI, for example)
- EHR for structured and unstructured clinical data
- Video for surgical recordings and dynamic imaging
- WSI for large, high-resolution pathology images
- Text for clinical notes and other textual data
- Images (PNG, JPEG, BMP) for pathology slides or static images
Monai Multimodal platform features advanced agentic AI, which leverages autonomous agents for multistep reasoning across images and text as well as specialized LLMs and VLMs, which are tailored models designed for medical applications that simplify cross-modal data integration. The collaborative ecosystem involves NVIDIA, premier research institutions, healthcare organizations, and academic centers. This unified approach accelerates research and enhances clinical collaboration by providing a consistent, reproducible framework for medical AI innovation.
“By integrating diverse data streams through advanced multimodal models, we’re not just improving diagnostic accuracy—we’re fundamentally transforming how clinicians interact with patient data,” said Tim Deyer MD, radiologist and managing partner at RadImageNet. “This innovation paves the way for faster, more reliable decision-making in healthcare.”
MONAI Multimodal building blocks for a unified medical AI research platform?
As part of the broader initiative, the MONAI Multimodal Framework comprises several core components designed to support cross-modal reasoning and integration.
Agentic framework
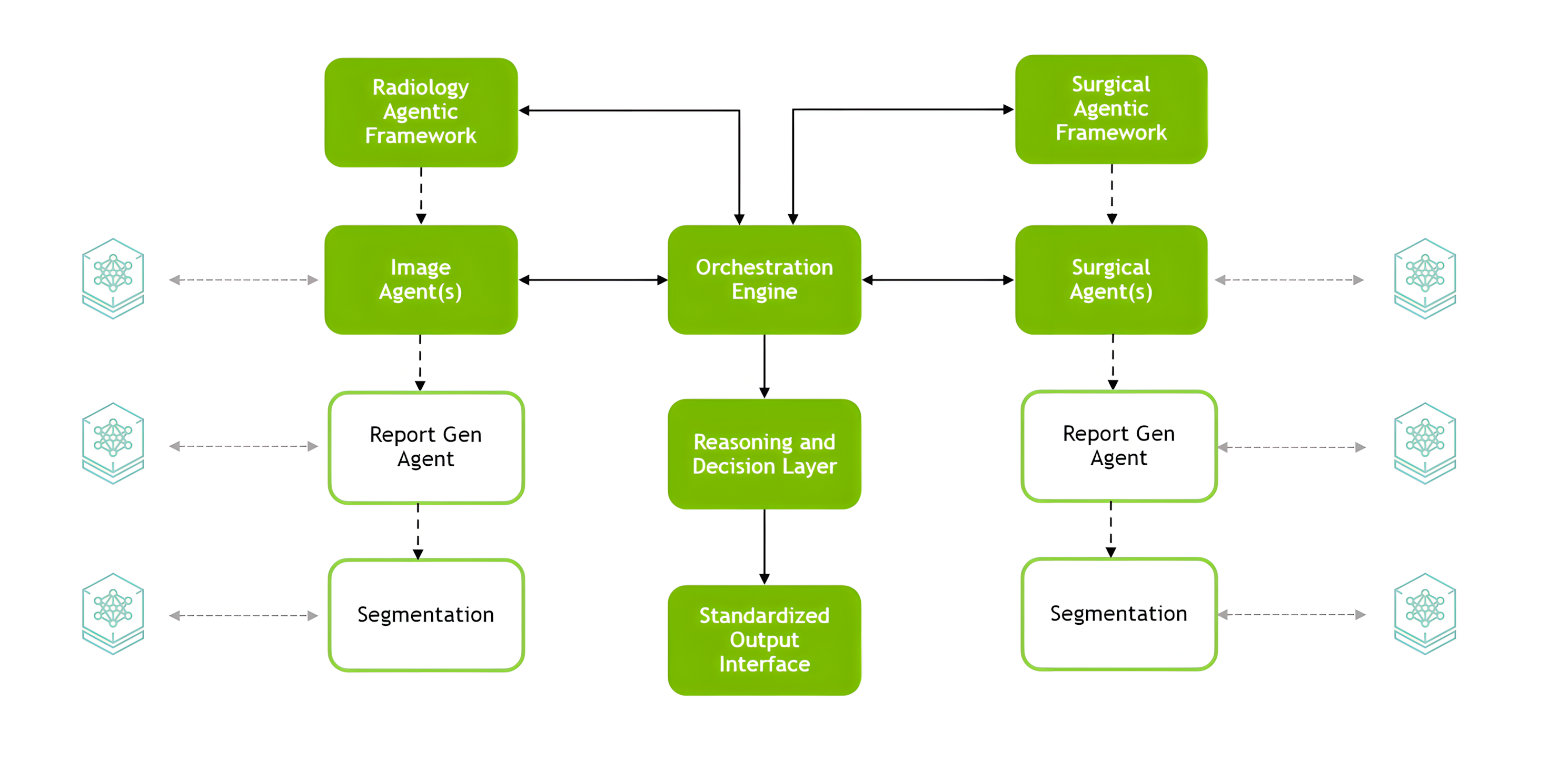
The agentic framework is a reference architecture for deploying and orchestrating multimodal AI agents that enable multistep reasoning by integrating image and text data with human-like logic. It supports custom workflows through customizable, agent-based processing and reduces integration complexity by bridging vision and language components effortlessly.
The MONAI agentic architecture enables cross-modal reasoning for medical AI using a modular design. It features a central orchestration engine that coordinates specialized agents (the Radiology Agent Framework and Surgical Agent Framework, for example), interfaces for consistent deployment, and a reasoning and decision layer that delivers standardized outputs (Figure 1).
Foundation models and community contributions
The MONAI Multimodal platform is powered by a suite of state-of-the-art models, combining NVIDIA-led frameworks with community partner innovations, as detailed below.
NVIDIA-led frameworks
NVIDIA-led frameworks include the following.
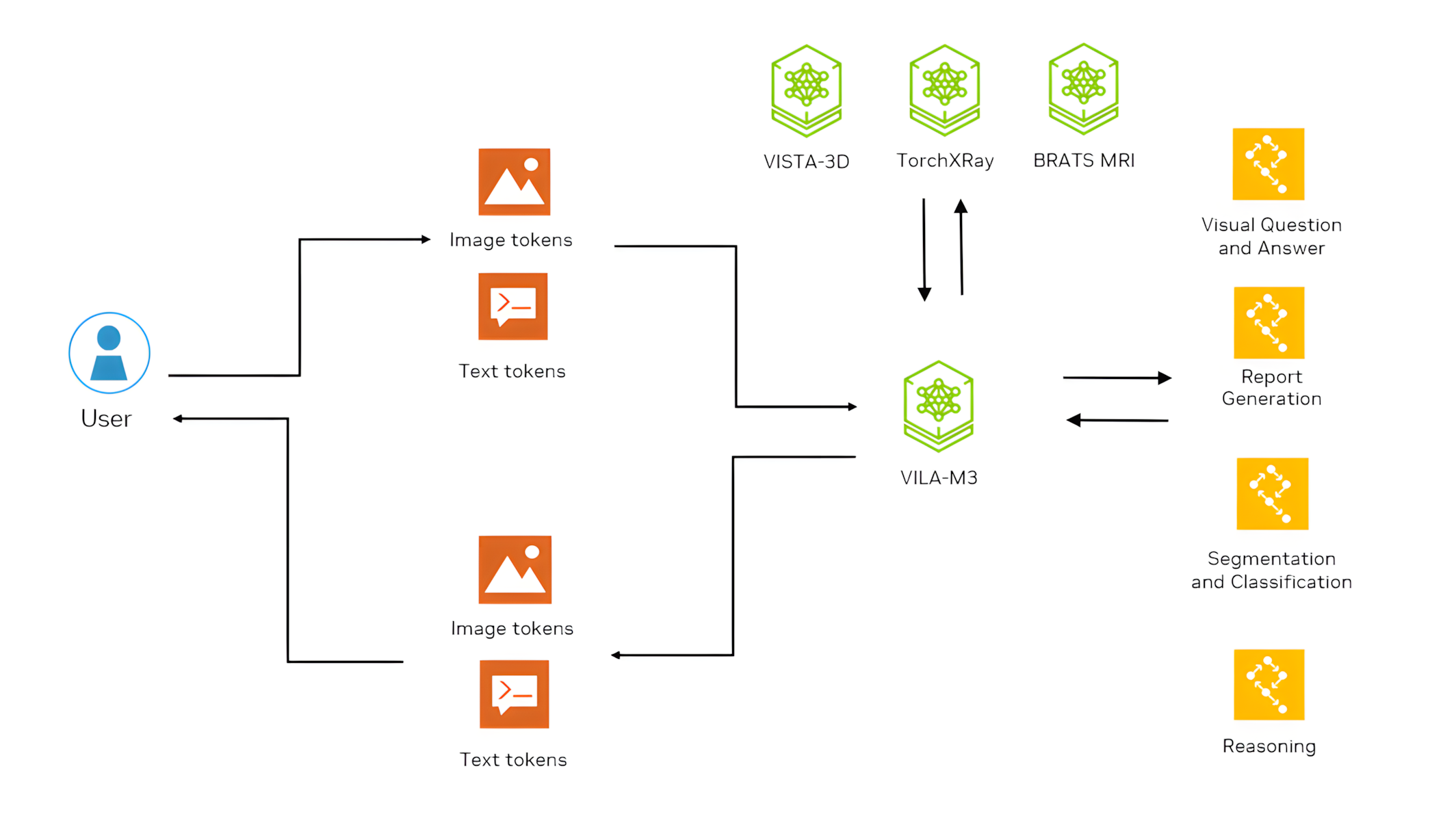
Radiology Agent Framework (Multimodal Radiology Agentic Framework): A radiology-focused agentic framework that combines medical images with text data to assist radiologists in diagnosis and interpretation.
Key features:
- Integrates 3D CT/MR imaging with patient EHR data
- Leverages large language models (LLMs) and vision-language models (VLMs) for comprehensive analysis
- Accesses specialized expert models on demand (VISTA-3D, MONAI BraTS, TorchXRayVision)
- Built with Meta Llama 3
- Processes multiple data streams for detailed outputs
- Performs complex reasoning tasks by breaking down problems into manageable steps
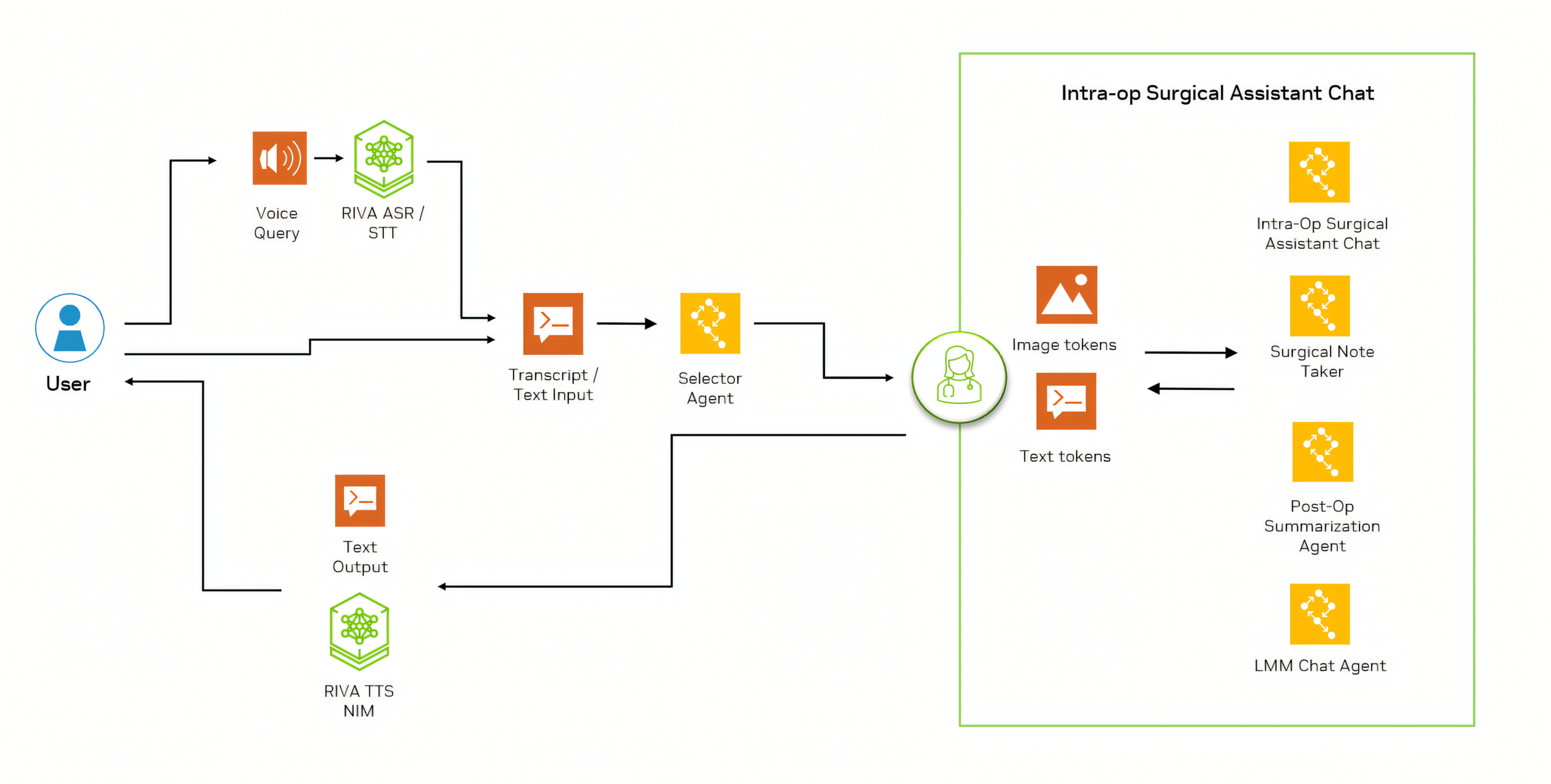
Surgical Agent Framework (Multimodal Surgical Agentic Framework): A tailored mix of VLMs and retrieval-augmented generation (RAG) designed for surgical applications. It provides end-to-end support for surgical workflows through a multi-agent system.
Key features:
- Real-time speech transcription through Whisper
- Specialized agents for query routing, Q&A, documentation, annotation, and reporting
- Computer vision integration for image analysis
- Optional voice response capabilities
- Integrates patient-specific pre-op data, clinician preferences, and medical device knowledge
- Processes intra-operative data in real time
- Functions as a digital assistant across all phases of surgery—training, planning, guidance, and analytics
Community-led partner models
Community-led partner models include the following.
RadViLLA: Developed by Rad Image Net, The BioMedical Engineering and Imaging Institute at Mount Sinai’s Icahn School of Medicine, and NVIDIA, RadViLLA is a 3D VLM for radiology that excels in responding to clinical queries for the chest, abdomen, and pelvis. RadViLLA is trained on 75,000 3D CT scans and over 1 million visual question-answer pairs.
It focuses on frequently imaged anatomies such as the chest, abdomen, and pelvis, and employs a novel two-stage training strategy that integrates 3D CT scans with textual data. RadviLLA autonomously responds to clinical queries and demonstrates superior performance in F1 score and balanced accuracy across multiple datasets.
CT-CHAT: CT-CHAT, developed by the University of Zurich, is a cutting-edge vision-language foundational chat model specifically designed to enhance the interpretation and diagnostic capabilities of 3D chest CT imaging. It leverages the CT-CLIP framework and a Visual Question Answering (VQA) dataset adapted from CT-RATE.
Trained on over 2.7 million question-answer pairs from CT-RATE, it leverages 3D spatial information, making it superior to 2D-based models. CT-CHAT excels in reducing interpretation time and providing accurate diagnostic insights by combining CT-CLIP’s vision encoder with a pretrained large language model, making it a powerful tool for medical imaging.
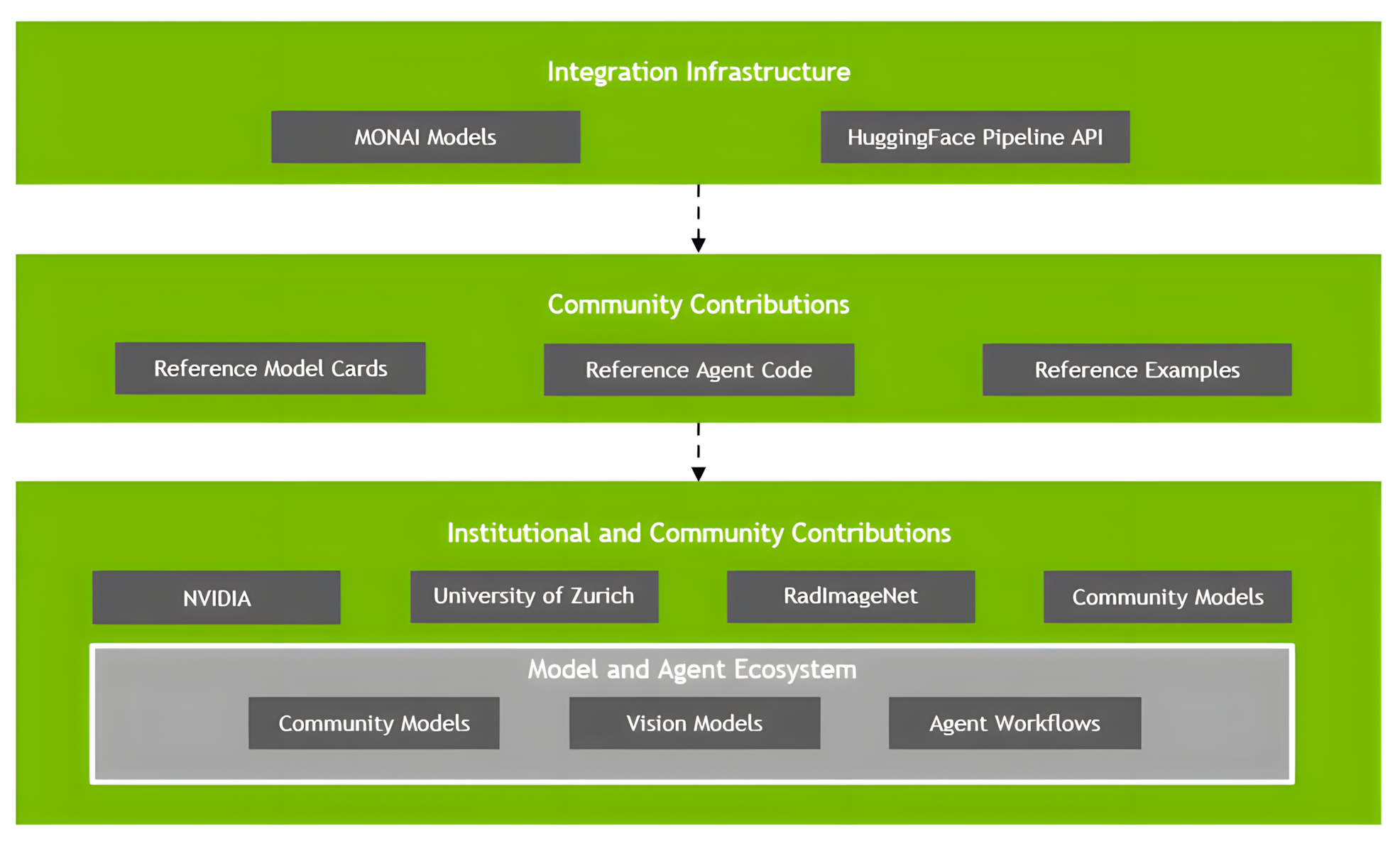
Hugging Face integration
Standardized pipeline support connecting MONAI Multimodal with Hugging Face research infrastructure:
- Model sharing for research purposes
- Integration of new models
- Broader participation in the research ecosystem
Community integration
Infrastructure for model sharing, validation, and collaborative development:
- Standardized model cards and agent workflows
- Knowledge exchange and shared best practices
- Foundation for collaborative research
Build the future of medical AI with MONAI Multimodal
MONAI Multimodal represents the next evolution of MONAI, the leading open-source platform for medical imaging AI. Building on this foundation, MONAI Multimodal extends beyond imaging to integrate diverse healthcare data types—from radiology and pathology to clinical notes and EHRs.
Through a collaborative ecosystem of NVIDIA-led frameworks and partner contributions, MONAI Multimodal delivers advanced reasoning capabilities through specialized agentic architectures. By breaking down data silos and enabling seamless cross-modal analysis, the initiative addresses critical healthcare challenges across specialties, accelerating both research innovation and clinical translation.
By unifying diverse data sources and leveraging state-of-the-art models, MONAI Multimodal is transforming healthcare—empowering clinicians, researchers, and innovators to achieve breakthrough results in medical imaging and diagnostic precision.
Together, we’re creating more than just software—we’re building an ecosystem where medical AI innovation thrives, benefiting researchers, clinicians, and patients worldwide. Get started with MONAI.
Join us at NVIDIA GTC 2025, and check out these related sessions: