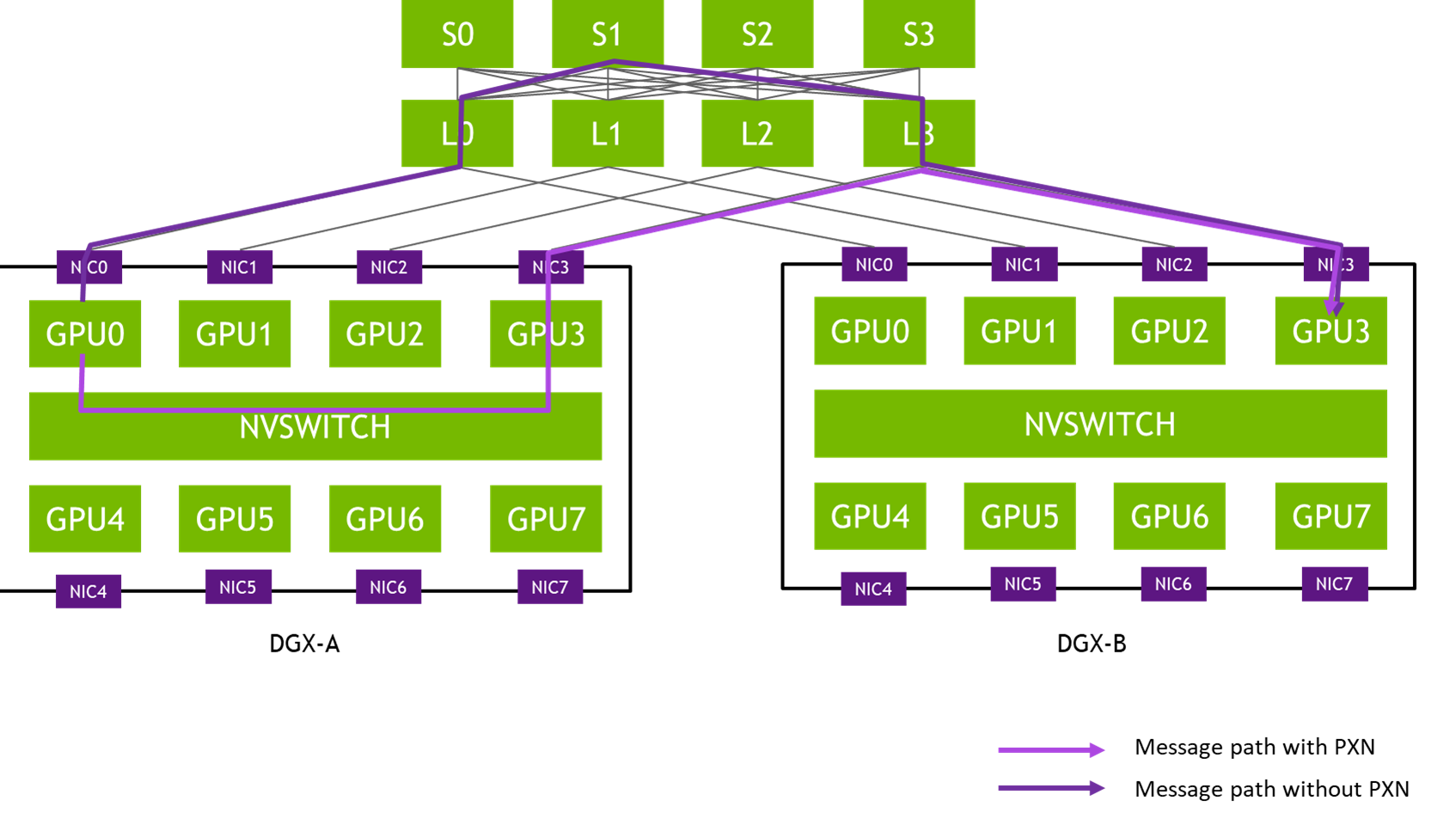
The NVIDIA Collective Communications Library (NCCL) implements multi-GPU and multinode (MGMN) communication primitives optimized for NVIDIA GPUs and networking. NCCL is a central piece of software for multi-GPU deep learning training. It handles any kind of inter-GPU communication, be it over PCI, NVLink, or networking. It uses advanced topology detection, optimized communication graphs, and tuning models to get the best performance straight out of the box on NVIDIA GPU platforms. To learn more about NCCL, visit the NVIDIA/nccl GitHub repo.
In this post, we discuss the new features and fixes released in NCCL 2.24.
NCCL 2.24 new features
We’ll explain the following new features in particular:
- Reliability, availability, and serviceability (RAS) subsystem
- User buffer (UB) registration for multinode collectives
- NIC Fusion
- Optional receive completions
- FP8 support
- Strict enforcement of
NCCL_ALGOandNCCL_PROTO
The RAS subsystem
The RAS subsystem has been added to NCCL 2.24 to help users diagnose app crashes and hangs. At large scale, identifying the root cause of an application’s lack of progress can be challenging to users not intimately familiar with NCCL.
RAS is a low-overhead infrastructure that can be used in production to query the health of NCCL jobs during their execution. It provides a global view of the state of the running application and can aid in the detection of outliers such as unresponsive nodes or individual application processes lagging behind their peers.
RAS consists of a set of threads (one per NCCL process) that establish TCP/IP connections with each other, forming a network that the threads then use to monitor each other’s health by regularly exchanging keep-alive messages. Should an NCCL process crash or hang, its RAS network connections to other NCCL processes get shut down or become unresponsive, thereby informing the RAS threads on those processes of the problem.
RAS is lightweight. In its idle state, it uses minimal system resources and should not interfere with the application. It is enabled by default but can be disabled if needed by providing the NCCL_RAS_ENABLE=0 environment variable.
The newly provided ncclras binary client can be invoked on any of the nodes where the NCCL job is running, and it generates a status report about the job (alternatively, standard tools such as telnet or netcat can be used by connecting to the localhost on port 28028).
An example output from a normally progressing job is shown below.
Job summary=========== Nodes Processes GPUs Processes GPUs(total) per node per process (total) (total) 4 8 1 32 32Communicators... (0.00s)=============Group Comms Nodes Ranks Ranks Ranks Status Errors # in group per comm per node per comm in group 0 8 4 1 4 32 RUNNING OK |
RAS attempts to keep its status reports short by avoiding repetitions. In this example, all 32 NCCL processes are listed on a single line, as are all eight NCCL communicators, as they share the same major attributes.
When generating the report, RAS collects information about every rank of every communicator and flags any encountered error conditions or discrepancies.
Group Comms Nodes Ranks Ranks Ranks Status Errors # in group per comm per node per comm in group 0 1 4 8 32 32 RUNNING MISMATCHWarnings========#0-0 (27a079b828ff1a75) MISMATCH Communicator ranks have different collective operation counts 26 ranks have launched up to operation 6650 6 ranks have launched up to operation 6649 Rank 0 -- GPU 0 managed by process 483072 on node 172.16.64.210 Rank 2 -- GPU 2 managed by process 483074 on node 172.16.64.210 Rank 3 -- GPU 3 managed by process 483075 on node 172.16.64.210 Rank 4 -- GPU 4 managed by process 483076 on node 172.16.64.210 Rank 5 -- GPU 5 managed by process 483077 on node 172.16.64.210 Rank 7 -- GPU 7 managed by process 483079 on node 172.16.64.210 |
When a potential problem is identified, additional details are provided below the summary table. In this example, 6 of the 32 ranks are lagging behind the others in terms of the number of issued collective operations. This should not be a cause for concern during periods of intense communication.
However, if the counters do not increase on repeated invocations of the RAS client, an investigation may be warranted. With the information provided by RAS, drill-down techniques such as interactive debugging can be used to determine the root cause.
If one of the job processes crashes, the following output can be expected:
Group Comms Nodes Ranks Ranks Ranks Status Errors # in group per comm per node per comm in group 0 1 4 7-8 32 32 RUNNING INCOMPLETEErrors======DEAD 1 job process is considered dead (unreachable via the RAS network) Process 3487984 on node 172.16.64.213 managing GPU 5#0-0 (cf264af53edbe986) INCOMPLETE Missing communicator data from 1 rank The missing rank: 21 |
NCCL 2.24 includes the initial implementation of RAS. Significantly expanded functionality is planned for future NCCL releases.
UB registration for multinode collectives
NCCL does not require the user to register and maintain any persistent buffers to function. Though this feature is great for ease of usability, it does come with performance tradeoffs. Without direct access, more control flow and buffering must occur when NCCL transfers data. This consumes more GPU resources, resulting in higher overheads for moving the same amount of data compared to explicitly registered and mapped buffers.
Whenever possible, NCCL developers are advised to register their buffers using ncclCommRegister to enable NCCL to use all available optimizations. This includes optimizations from special hardware like NvSwitch or IB Sharp as well as better optimizations for peer-to-peer transfers. The NCCL team is always working to add more use cases for registered user buffers. NCCL 2.24 adds UB registration support for:
- Multiple ranks-per-node collective networking, most notably IB SHARP. AllReduce, AllGather, and ReduceScatter are supported. This means applications running with one process-per-GPU and FSDP communication backends can take greater advantage of IB SHARP technology.
- NCCL now makes use of registered user buffers in standard peer-to-peer networks (like the default IB plugin) for the Ring algorithm.
ncclAllReduce,ncclAllGather, andncclBroadcastare supported.
In addition, for pure network-based AllGather and Broadcast Ring operations, NCCL will use only a single SM, saving GPU resources for computation. No application changes are needed to use this feature, as long as ncclCommRegister has been called on the user buffers or NCCL is used inside a CUDA graph.
Preliminary performance testing shows strong performance gains for one GPU per node AllGather and Broadcast operations, while reducing SM usage from four to one. For eight GPU per node AllReduce and AllGather, a 5% increase in peak bandwidth is achieved with user buffer registration. You can expect to see the largest performance benefits to your application from improved compute overlapping.
NIC Fusion
As the taxonomy of systems supported by NCCL expands, NCCL must adapt itself to work well out of the box on all of them. Namely, with many-NIC (more than one NIC per GPU) systems, the following issues have been seen:
- NCCL algorithms are designed to work with one NIC per GPU, so on systems with two NICs to one GPU, or four to one, those algorithms could crash.
- NCCL core tuning code is also designed for one NIC per GPU. If there are many NICs, NCCL might overtune itself, taking too many SMs for communication, or choose not to use some of these NICs at all.
To solve this problem, NCCL 2.21 implemented a feature called Port Fusion. In this initial solution, the default IB plugin automatically merged dual-port devices into a single logical device before returning to the NCCL core. This was fine for dual-port NIC systems, but didn’t address any other many-NIC use cases. Since then, the NCCL team extended this functionality to address some of the following scenarios:
- NICs that aren’t detected to be dual-port (either because they simply aren’t, or the hypervisor doesn’t display them as dual-port)
- Quad-port systems
- Arbitrary merging of devices
- Automatic merging by topology distance
In addition, Port Fusion had some limitations to overcome:
- It expected each port to present as a separate VF of the same PCI device.
- It overwrote the physical properties of each NIC in the plugin, presenting a false topology if the user wanted to dump it to a file.
- It did not respect the user-provided topology when making a decision to merge NICs. Instead, it used only the PCI address the OS provided it with. This is a problem in virtualization scenarios when PCI addresses can present differently.
NIC Fusion was created to address these limitations. It is a flexible system where the NCCL core distinguishes between physical and virtual devices and explicitly selects which to fuse depending on the criteria specified by the user. In addition, NIC Fusion ensures that any topology files dumped by NCCL include only the physical devices on the system. Virtual devices are created at a later point in initialization.
NIC Fusion works as a multistep process. First, NCCL enumerates all the network devices returned by the network plugin, same as before. It stores these as physical devices in its topology. It then checks if the plugin is compatible with NIC Fusion. If it is, then NCCL will initiate a merging process. If the user has defined an explicit set of NICs to be merged (using the NCCL_NET_FORCE_MERGE variable), NCCL does a first pass of arbitrary merges before moving on to automatic merging.
Automatic merging is a fairly involved process, beginning with a search of the distance between every pair of physical NICs. NCCL loops through each physical NIC, placing each into a new virtual device with up to three others which are within the automatic merge distance level (specified by NCCL_NET_MERGE_LEVEL). This process results in all physical devices being placed into virtual.
Finally, NCCL will strip away all physical devices from its topology if NIC Fusion occurred, and replace them with virtual devices before moving on to graph formation and search (unchanged from before).
Work can be load-balanced any way the network plugin chooses on a given fused NIC. This has been implemented in the default IB plugin with a simple even split of traffic across all fused devices for a given send or receive operation.
To elaborate on exactly what needs to be done to make use of NIC Fusion in a network plugin, first look at the new API:
#define NCCL_NET_MAX_DEVS_PER_NIC_V9 4typedef struct { int ndevs; int devs[NCCL_NET_MAX_DEVS_PER_NIC_V9];} ncclNetVDeviceProps_v9_t;typedef ncclNetVDeviceProps_v9_t ncclNetVDeviceProps_t;... // Create a virtual NIC given the specified properties, which can be accessed at device index d ncclResult_t (*makeVDevice)(int* d, ncclNetVDeviceProps_t* props); |
NCCL uses makeVDevice to instruct a plugin to fuse devices together, and it must be implemented for NIC Fusion to occur. NCCL will compile a list of devices and send it to the plugin. The plugin should allocate a new device index referring to this new virtual device and populated with that value before returning success. NCCL will use this new value to refer to the new device.
After this, the user controls how merging happens. The user can specify NCCL_NET_FORCE_MERGE to force NCCL to merge an arbitrary set of devices. NCCL expects it to be a semicolon-delimited array of fused NICs, each consisting of a comma-delimited list of physical NIC names. For example:
NCCL_NET_FORCE_MERGE=mlx5_0,mlx5_1;mlx5_2,mlx5_3;mlx5_4,mlx5_5,mlx5_6;mlx5_7 |
This will result in NCCL creating virtual devices mlx5_0+mlx5_1, mlx5_2+mlx5_3,mlx5_4+mlx5_5+mlx5_6, and mlx5_7. Note that any unspecified devices will still be used, but they will not be merged together unless they meet automerging criteria.
All remaining NICs will be merged through NCCL_NET_MERGE_LEVEL. This controls the topology distance at which NCCL will automatically fuse physical NICs. The default value is PORT. This makes the NIC Fusion default behavior identical to the behavior in NCCL 2.21 through 2.23, where dual-port NICs are merged together.
Other possible options are LOC (disable any fusion), PIX (same PCI switch), PXB (same PCI switch tree), PHB (same CPU), or SYS (same system). NIC Fusion will automatically use the PCI paths in the provided topology file (if specified) or simply use the values returned by the system (realpath).
NIC Fusion should make no difference to NCCL default behavior. Despite working quite differently under the hood, it will by default still merge only dual-port NICs, in the same way that Port Fusion would.
NIC Fusion notes:
- NIC Fusion doesn’t increase performance on systems that don’t need it. NIC Fusion settings are recommended to be left alone, unless you are running on a system with two or more NICs per GPU, and you see problems with your performance or SM usage.
- Fusing NICs of differing distances to a GPU can cause poor or unpredictable performance.
This is a foundational feature that can help plugins cleanly implement more advanced features, such as NIC failover and dynamic load balancing.
Optional receive completions
The team consistently analyzes the NCCL network plugin API to determine if new APIs or extensions of existing ones can bring more value and performance to NVIDIA customers. One possible optimization is thanks to the features of NCCL LL and LL128 protocols. Both have inherent synchronization that relax the requirements of the network plugin, and support for this was added in NCCL 2.24.
When using LL or LL128 protocols, NCCL may not need to poll on network receive completions due to inherent synchronizations to the protocols. LL and LL128 protocols rely on flags embedded within the data itself to signal to the receiving GPU that data has arrived. The GPU will poll on data in GPU memory, and as soon as it is received, it will start processing it without waiting for the network stack to issue a completion. Skipping this receive completion can allow the network plugin to skip extra signaling and synchronization, thereby lowering overhead and reducing congestion at scale.
Starting with the 2.24 release, NCCL core may set the request pointer object to NCCL_NET_OPTIONAL_RECV_COMPLETION (0x1) when invoking irecv. This is a hint to the plugin that this operation doesn’t require explicit synchronization. Note that test will still be called by NCCL on this request and should still tell NCCL that the request is done and clean up any tracking structures.
This is an opt-in feature that can be used for extra optimization. Existing network plugins will continue to perform exactly as before. Optional receive completions can be disabled by setting NCCL_NET_OPTIONAL_RECV_COMPLETION=0.
FP8 support
NCCL now supports native FP8 reductions, in both e4m3 and e5m2 formats. These data types are enabled only on NVIDIA Hopper and newer architectures.
Strict enforcement of NCCL_ALGO and NCCL_PROTO
Previously, NCCL would silently fall back to a supported algorithm and protocol when users specified invalid algorithms. Given the amount of confusion this causes when benchmarking or forcing custom tunings, the NCCL team has decided to end this practice and return an error when a specified NCCL_ALGO or NCCL_PROTO isn’t supported instead of silently falling back.
In addition to strict checking, NCCL 2.24 adds more powerful semantics, enabling users to flexibly force-tune with these variables. For details, see the NCCL_ALGO and NCCL_PROTO documentation.
Bug fixes and minor features
NCCL 2.24 provides the following additional updates:
- Adjust PAT tuning to improve transition of PAT and Ring at scale
- Use
cuMem*functions for host memory allocation by default - Return
ncclInvalidUsagewhenNCCL_SOCKET_IFNAMEis set to an incorrect value instead ofncclInternalError - Fix FD leak in UDS
- Fix crash when mixing buffer registration and graph buffer registration
- Fix user buffer registration with dmabuf
- Fix crash in IB code caused by uninitialized fields
- Fix non-blocking ncclSend/ncclRecv
- Various compiler tweaks and fixes
- Fix typo in
ncclTopoPrintGraph
Summary
NCCL 2.24 introduces several important new features and improvements, including reliability and observability at scale, the RAS subsystem, user buffer registration support for multinode collectives, and FP8 data type support. Key enhancements include the RAS subsystem, UBR for multinode collectives, NIC Fusion, and optional receive completions.
To learn more about previous NCCL releases, see the following posts:
- New Scaling Algorithm and Initialization with NVIDIA Collective Communications Library 2.23
- Memory Efficiency, Faster Initialization, and Cost Estimation with NVIDIA Collective Communications Library 2.22
Learn more about NCCL and NVIDIA Magnum IO. And check out the on-demand session Training Deep Learning Models at Scale: How NCCL Enables Best Performance on AI Data Center Networks.