NVIDIA announced world-record DeepSeek-R1 inference performance at NVIDIA GTC 2025. A single NVIDIA DGX system with eight NVIDIA Blackwell GPUs can achieve over 250 tokens per second per user or a maximum throughput of over 30,000 tokens per second on the massive, state-of-the-art 671 billion parameter DeepSeek-R1 model. These rapid advancements in performance at both ends of the performance spectrum were made possible by improvements to the NVIDIA open ecosystem of inference developer tools, now optimized for the NVIDIA Blackwell architecture.
These performance records will improve as the NVIDIA platform continues to push the limits of inference on the latest NVIDIA Blackwell Ultra GPUs and NVIDIA Blackwell GPUs.
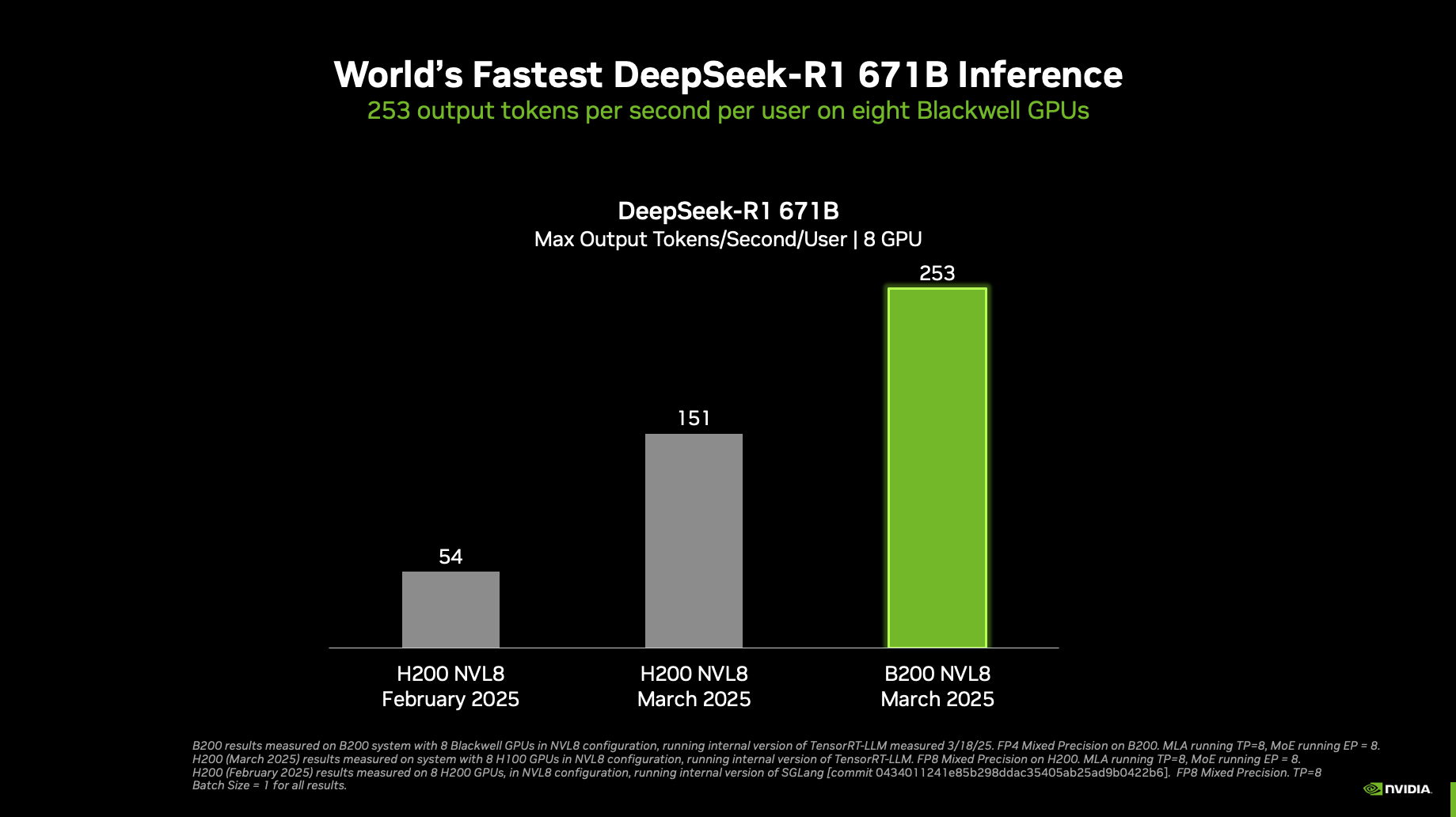
Single DGX B200 8-GPU system, and single DGX H200 8 GPU system | B200 and H200 March and February numbers running on an internal version of TensorRT-LLM | March, Input 1,024 tokens, output 2,048 tokens, February and January 1,024 input tokens, 1,024 output tokens | Concurrency 1 | B200 FP4, H100 and H200 FP8 precision.
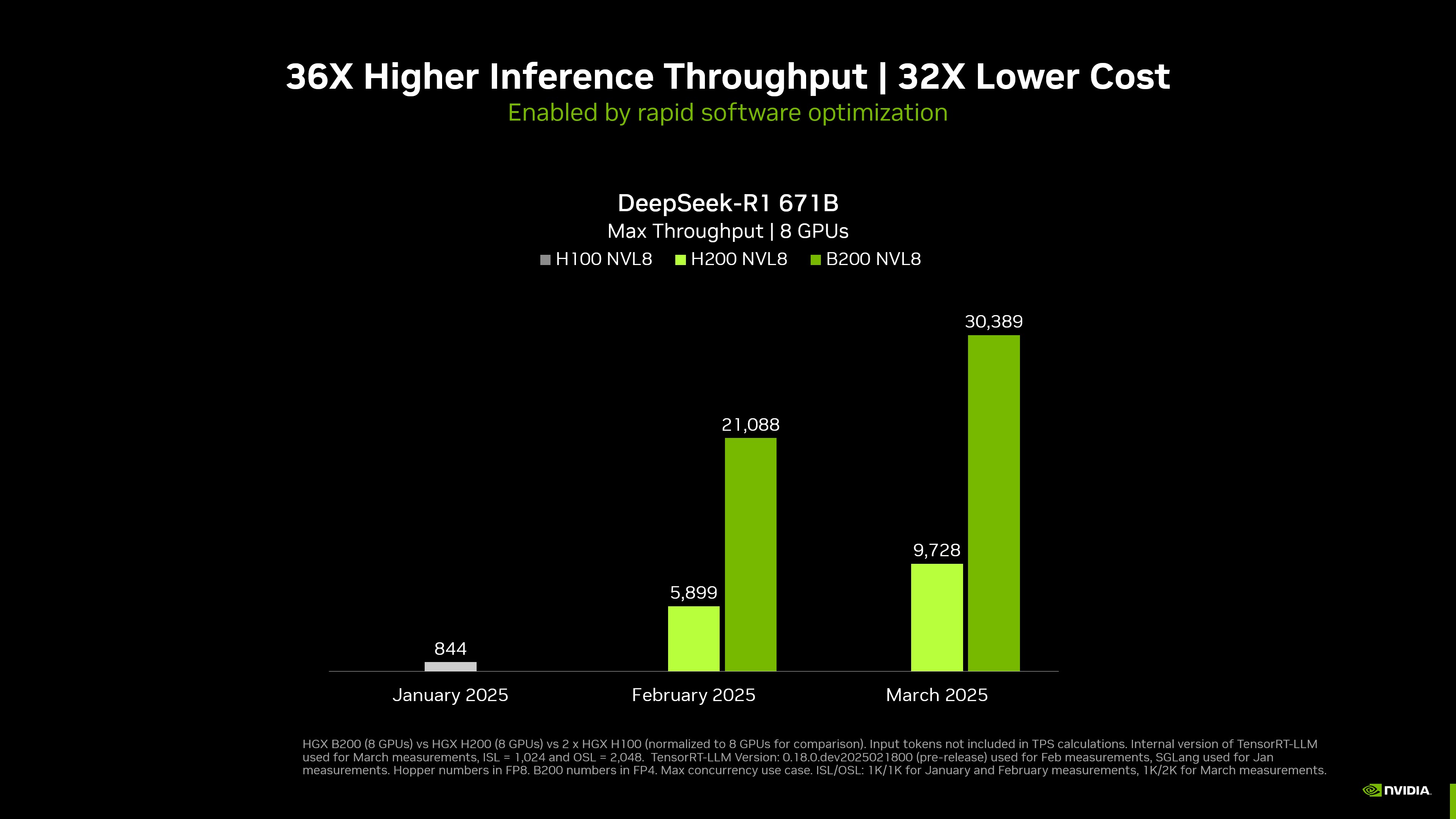
Maximum throughput normalized to 8-GPU system | single DGX B200 8 GPU system, single DGX H200 8 GPU system, two DGX H100 8 GPU systems normalized | Internal version of TensorRT-LLM | March, Input 1,024 tokens, output 2,048 tokens, February and January 1,024 input tokens, 1,024 output tokens | Concurrency MAX | B200 FP4, H200/H100 FP8 precision.
The NVIDIA inference ecosystem is the largest in the world. It enables developers to build solutions tailored for their deployment requirements, whether they are targeting maximum user experience or maximum efficiency. It includes open source tools directly from NVIDIA, as well as the community, which take advantage of the latest Blackwell architecture and software advancements.
These Blackwell advancements include up to 5x more AI compute with fifth-generation Tensor Cores with FP4 acceleration, 2x the NVIDIA NVLink bandwidth compared to the prior generation with fifth-generation NVLink and NVLink Switch, and scalability to much larger NVLink domains. These performance improvements, both on a per-chip basis and at data center scale, are critical enablers of high throughput, low latency inference for cutting-edge LLMs, like DeepSeek-R1.
Accelerated computing requires more than a powerful hardware infrastructure. An optimized and rapidly evolving software stack is required to deliver optimal workload performance both on today’s most demanding workloads and to be ready to serve new, even more challenging workloads as they emerge. NVIDIA continues to optimize every layer of the technology stack—chips, systems, libraries, algorithms, and more—to deliver exceptional workload performance.
This post provides an overview of the many updates to the NVIDIA inference ecosystem to get the most out of the NVIDIA Blackwell platform, including NVIDIA TensorRT-LLM, NVIDIA TensorRT, TensorRT Model Optimizer, CUTLASS, NVIDIA cuDNN, and popular AI frameworks including PyTorch, JAX, and TensorFlow. Additionally, we share new performance and accuracy data measured on an NVIDIA DGX B200 system, featuring eight Blackwell GPUs connected using two NVLink Switch chips.
The TensorRT ecosystem: A full inference stack optimized for NVIDIA Blackwell
The NVIDIA TensorRT ecosystem is designed to enable developers to optimize their production inference deployments on NVIDIA GPUs. It contains multiple libraries that enable the preparation, acceleration, and deployment of AI models—all of which are now ready to run on the latest NVIDIA Blackwell architecture. This shows the continuously large performance improvements compared to the prior-generation NVIDIA Hopper architecture.
TensorRT Model Optimizer is the first step for optimizing inference speed. It offers state-of-the-art model optimization techniques, including quantization, distillation, pruning, sparsity and speculation decoding, to make models more efficient during inference. The latest TensorRT Model Optimizer 0.25 release supports Blackwell FP4 for both post-training quantization (PTQ) and quantization-aware training (QAT), optimizing the overall inference compute throughput and reducing memory usage for down-stream inference frameworks.
After a model is optimized, a high-performance inference framework is essential to run the model efficiently. TensorRT-LLM provides developers with a toolbox to enable real-time and cost and energy efficient LLM inference. The latest TensorRT-LLM 0.17 release adds support for Blackwell and provides tailored optimizations to Blackwell instructions, memory hierarchy, and FP4.
TensorRT-LLM, architected with PyTorch, delivers peak performance through powerful and flexible kernels for common LLM inference operations and advanced runtime features like in-flight batching, KV cache memory management, and speculative decoding.
Popular deep learning frameworks PyTorch, JAX, and TensorFlow have also been updated to support both inference and training on Blackwell. Other LLM-serving frameworks like vLLM and Ollama can now be used on Blackwell GPUs. Others will also be supported in the near future.
Blackwell with TensorRT inference performance
The Blackwell architecture coupled with TensorRT software enables significant inference performance improvements compared to the Hopper architecture. This performance increase comes from the significantly greater compute performance, memory bandwidth, and optimized software stack to achieve excellent delivered performance.
On popular community models, including DeepSeek-R1, Llama 3.1 405B, and Llama 3.3 70B, the DGX B200 platform running TensorRT software and using FP4 precision is already delivering over 3x more inference throughput compared to the DGX H200 platform.
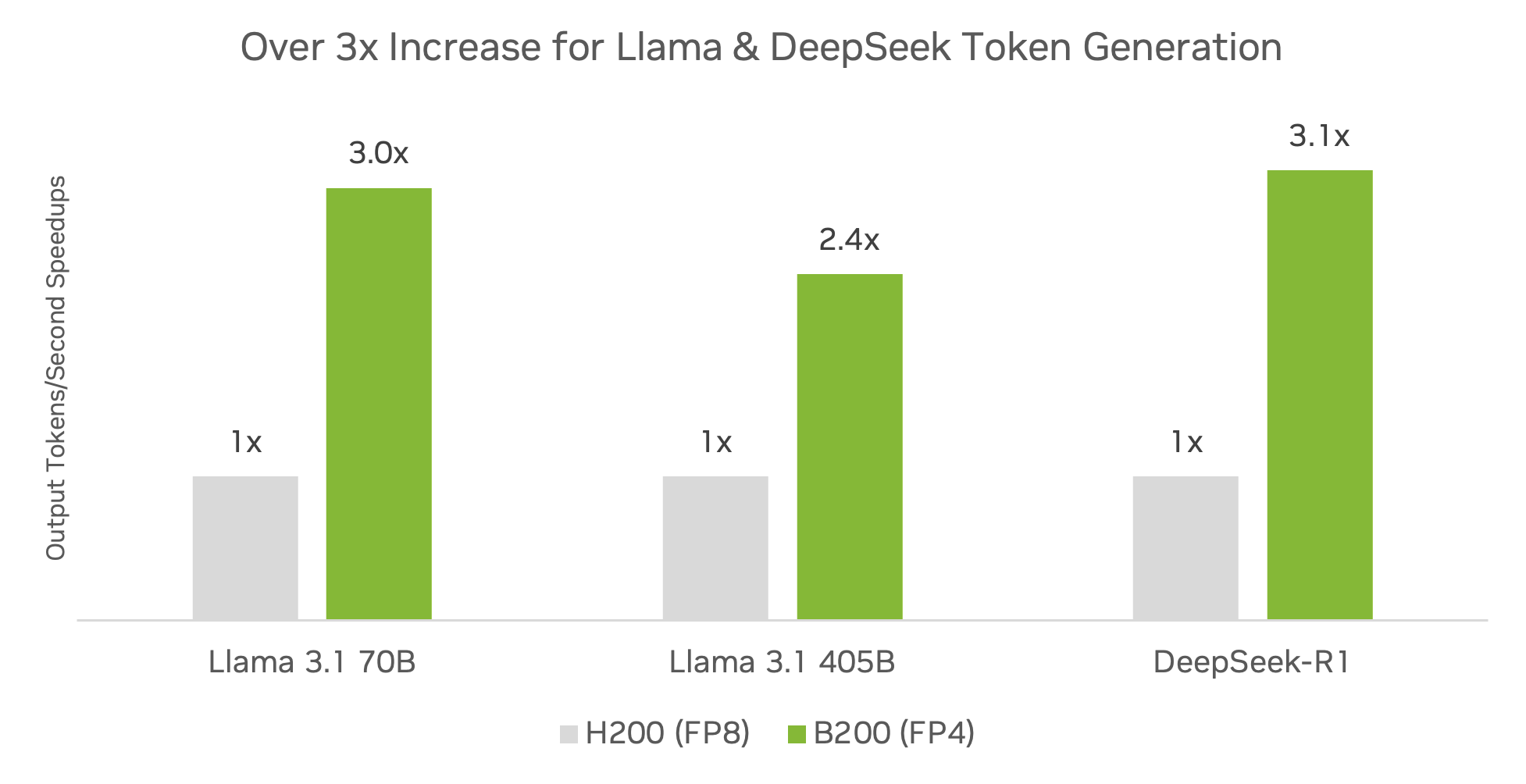
Preliminary specifications. May be subject to change.
TensorRT Model Optimizer v0.23.0. TensorRT-LLM v0.17.0. Max batch size 2048, actual batch size dynamic using TensorRT-LLM Inflight Batching. H200 FP16/BF16 GEMM + FP8 KV cache. B200 FP4 GEMM + FP8 KV cache. Throughput speedup.
Llama 3.3 70B: ISL 2048, OSL 128
Llama 3.1 405B: ISL 2048, OSL 128
DeepSeek-R1: ISL 1024, OSL 1024
When quantizing models to make use of the benefits of lower precision compute, ensuring minimal accuracy loss is critical for production deployments. For DeepSeek-R1, the TensorRT Model Optimizer FP4 post-training quantization (PTQ) leads to minimal accuracy loss compared to the FP8 baseline across a variety of datasets, as shown in Table 1.
| MMLU | GSM8K | AIME 2024 | GPQA Diamond | MATH-500 | |
| DeepSeek R1-FP8 | 90.8% | 96.3% | 80.0% | 69.7% | 95.4% |
| DeepSeek R1-FP4 | 90.7% | 96.1% | 80.0% | 69.2% | 94.2% |
Accuracy results using the baseline BF16 precision and with FP4 quantization on the popular Llama 3.1 405B and Llama 3.3 70B are provided in Table 2.
| MMLU Baseline | GSM8K Baseline | |
| Llama 3.1 405B-BF16 | 86.5% | 96.3% |
| Llama 3.1 405B-FP4 | 86.1% | 96.1% |
| Llama 3.3 70B-BF16 | 82.5% | 95.3% |
| Llama 3.3 70B-FP4 | 80.5% | 92.6% |
When deploying in low precisions, such as FP4, QAT can be applied to recover accuracy, provided that fine-tuning datasets are available. To illustrate the value of QAT, NVIDIA Nemotron 4 15B and Nemotron 4 340B models quantized with QAT to FP4 using TensorRT Model Optimizer achieve lossless FP4 quantization compared to the BF16 baseline (Table 3).
| Nemotron 4 15B Base | Nemotron 4 340B Base | |
| BF16 (baseline) | 64.2% | 81.1% |
| FP4 with PTQ | 61.0% | 80.8% |
| FP4 with QAT | 64.5% | 81.4% |
Increasing image generation efficiency on Blackwell using TensorRT and TensorRT Model Optimizer with FP4
Previously, TensorRT and TensorRT Model Optimizer have enabled high-performance image generation using diffusion models quantized to 8-bit data formats, including both INT8 and FP8.
Now, NVIDIA Blackwell and FP4 precision deliver even better performance for AI image generation. These benefits also extend to users looking to generate images locally on AI PCs powered by the NVIDIA GeForce RTX 50 series GPUs.
The Flux.1 model family from Black Forest Labs are state-of-the-art text-to-image models that offer superior prompt adherence and the ability to generate complex scenes. Developers can now download FP4 Flux models from Black Forest Lab’s Hugging Face collections and directly deploy them with TensorRT.
These quantized models were generated by Black Forest Labs using TensorRT Model Optimizer FP4 workflows and recipes. To illustrate the benefit of FP4 image generation on Blackwell, a Flux.1-dev model in FP4 achieves speedups of up to 3x in throughput (images per second) compared to FP16, all while compressing VRAM usage by up to 5.2x and maintaining image quality (Table 4).

Only the transformer backbone in Flux.1-dev was quantized into FP4, other parts remain to be in BF16 format. The low-VRAM mode in TensorRT DemoDiffusion loads the T5, CLIP, VAE, and the FLUX transformer used in FLUX.1-dev as needed and unloads them when done. This enables the peak memory usage of FLUX to stay within the maximum of those four individual models’ sizes, at the cost of extra latency due to having to load and unload each model during inference.
| VRAM usage (GB) | VRAM usage compression | |
| FP16 (Baseline) | 51.4 | 1x |
| FP16 low-VRAM | 23.3 | 2.2x |
| FP8 | 26.3 | 1.9x |
| FP8 low-VRAM | 19.9 | 2.6x |
| FP4 | 19.5 | 2.6x |
| FP4 low-VRAM | 9.9 | 5.2x |
Figure 5 shows images generated by a Flux model quantized with FP4, highlighting how image quality and content remain consistent with the BF16 baseline for a given prompt. Additionally, Table 5 provides a quantitative evaluation of FP4 image quality, relevance, and appeal using 1,000 images.

Input prompt for top image: “Two colossal stars dance in the vastness of space, their intense gravitational forces pulling them closer together. As one star collapses into a black hole, it releases a brilliant burst of energy, creating a dazzling display of shimmering light against the cosmic backdrop. Swirling clouds of gas and dust encircle the spectacle, hinting at the unimaginable power contained within.”
Input prompt for bottom image: “A realistic sphere textured with the soft, fluffy fur of an animal sits in the center of the image on a plain colored background. The fur ripples with gentle, lifelike motion, and the shadows cast by the fur create an engaging visual effect. The render has a high-quality, octane appearance.”
| Image Reward | CLIP-IQA | CLIPScore | |
| BF16 | 1.118 | 0.927 | 30.15 |
| FP4 PTQ | 1.096 | 0.923 | 29.86 |
| FP4 QAT | 1.119 | 0.928 | 29.92 |
Flux.1-dev model, 30 steps, 1K images. TensorRT Model Optimizer v0.23.0 FP4 recipe. Simulated on NVIDIA H100 GPUs on 1/24/2025. The simulation is mathematically identical to the TensorRT kernel level as on RTX 5090. The actual score may differ slightly on an RTX 5090.
The TensorRT 10.8 update can now run Flux.1-Dev and Flux.1-Schnell models with peak FP4 performance on higher-end GeForce RTX 50 series GPUs. With –low-vram mode, you can even run these models on a limited memory config like GeForce RTX 5070. Moreover, TensorRT also supports running Depth and Canny Flux ControlNets provided by Black Forest Labs. You can try it now using TensorRT demo/Diffusion.
Blackwell-optimized deep learning primitives with cuDNN
Since its introduction in 2014, NVIDIA cuDNN has been fundamental to accelerating deep learning workloads on GPUs. By providing highly optimized implementations of core deep learning primitives, it has enabled frameworks like PyTorch, TensorFlow, and JAX to deliver state-of-the-art performance. Through seamless integration with these frameworks and optimized performance across different GPU architectures, cuDNN has established itself as the performance engine powering end-to-end deep learning workloads from training to inference.
With the release of cuDNN 9.7, we’re extending support to NVIDIA Blackwell architecture across both Data Center and GeForce product lines. Developers can expect significant performance improvements when migrating cuDNN operations to the latest Blackwell Tensor Cores. The library provides optimized general matrix multiply (GEMM) APIs that harness Blackwell advanced capabilities for block-scaling FP8 and FP4 operations, abstracting away the complexity of low-level optimization so developers can focus on innovation.
cuDNN delivers substantial performance improvements for FP8 Flash Attention operations, achieving up to 50% speedups on forward propagation and 84% speedups on backward propagation with FP8 kernels. The library also provides highly optimized GEMM operations with advanced fusion capabilities on Blackwell architecture. Looking ahead, cuDNN will continue to expand its fusion support to enable even greater performance gains for deep learning workloads.
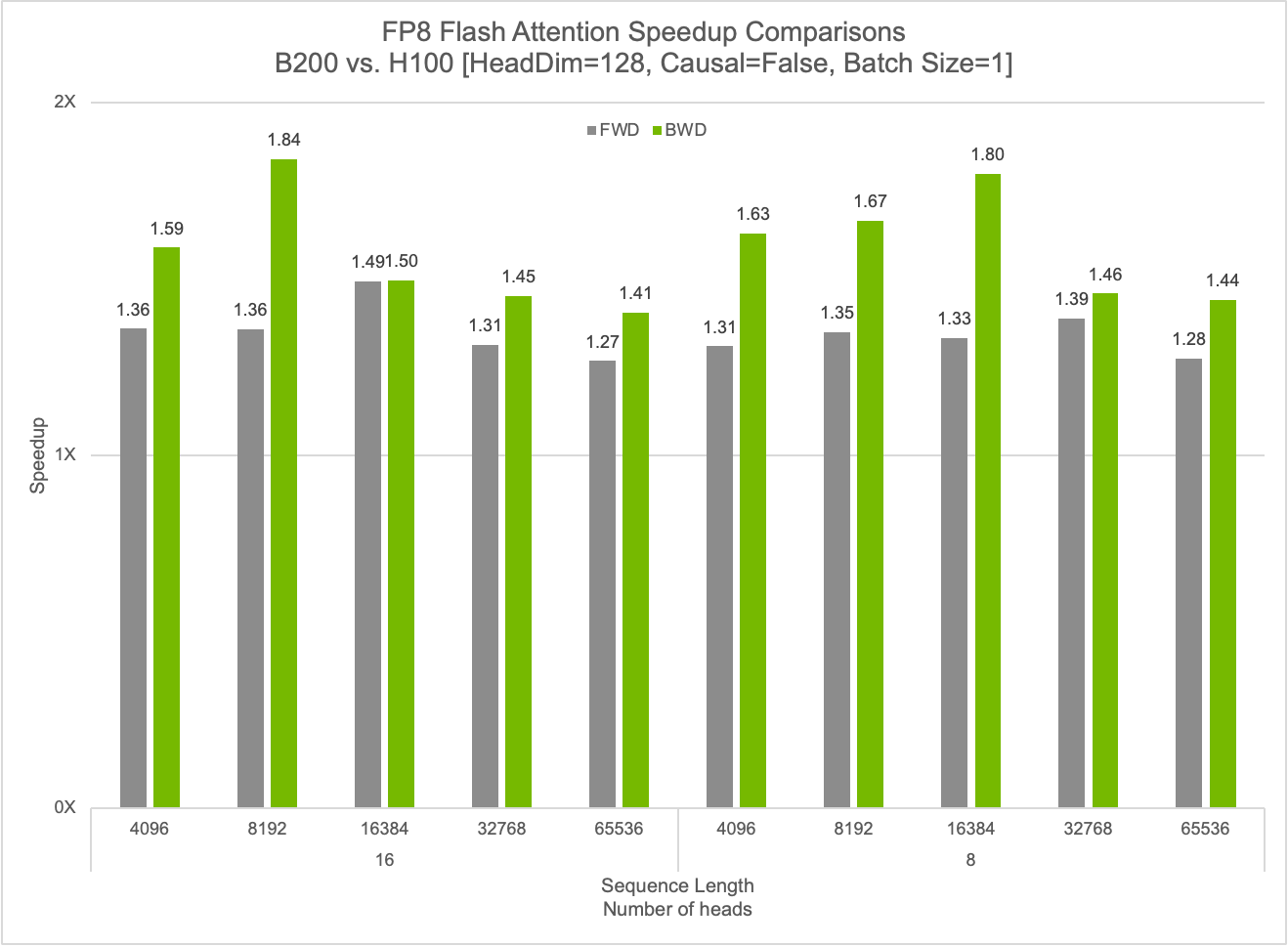
Crafting high-performance Blackwell kernels with CUTLASS
CUTLASS, since its 2017 debut, has been instrumental for researchers and developers implementing high-performance CUDA kernels on NVIDIA GPUs. By providing developers with comprehensive tools to design custom operations, such at GEMMs and Convolutions, targeting NVIDIA Tensor Cores, it has been critical for the development of hardware-aware algorithms, powering breakthroughs like FlashAttention and establishing itself as a cornerstone for GPU-accelerated computing.
With the release of CUTLASS 3.8, we’re extending support to NVIDIA Blackwell architecture, enabling developers to harness next-generation Tensor Cores with support for all new data types. This includes the new narrow precision MX formats and NVIDIA’s own FP4, empowering developers to optimize custom algorithms and production workloads with the latest innovations in accelerated computing. Figure 7 shows that we are able to achieve up to 98% relative peak performance for Tensor Core operations.
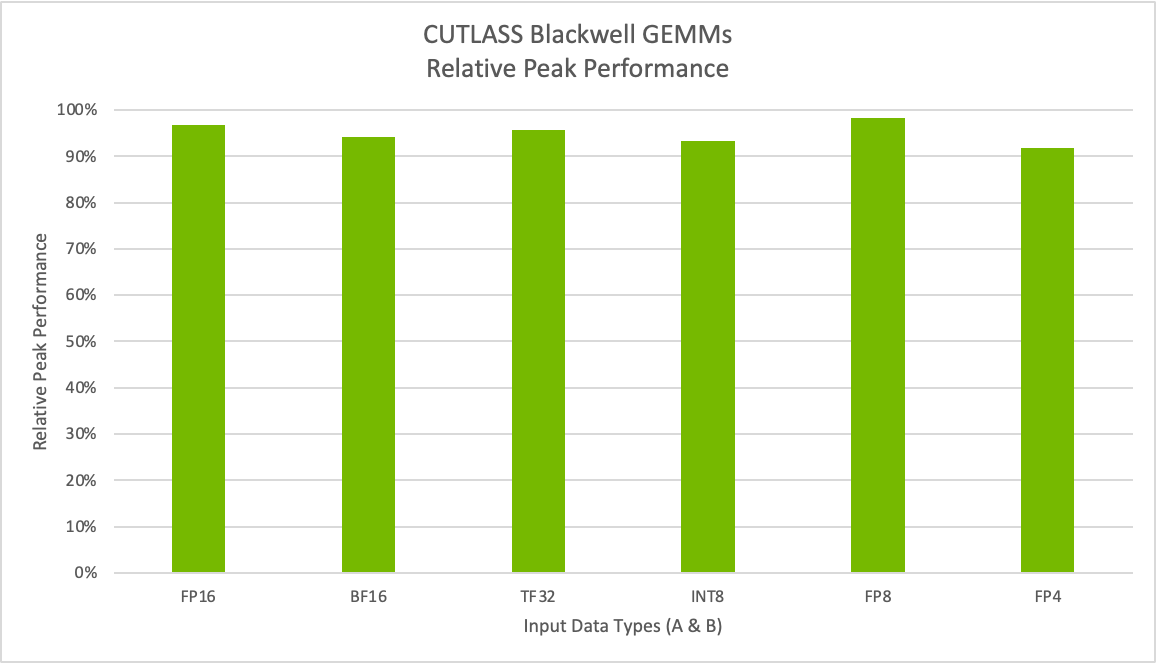
Benchmarks were performed on a B200 system. M=K=16384 and N=17290.
CUTLASS brings popular features like Grouped GEMM and Mixed Input GEMM operations to Blackwell. Grouped GEMM helps accelerate MoE models by offering a more efficient way to perform multiple expert computations in parallel. Mixed Input GEMMs power quantized kernels that can reduce GPU memory requirements for LLMs where model weights dominate GPU memory consumption.
OpenAI Triton support for Blackwell
OpenAI Triton compiler also now supports Blackwell, enabling developers and researchers to leverage the latest Blackwell architecture features with a Python-based compiler. OpenAI Triton can now take advantage of the latest architectural innovations in the Blackwell architecture and can achieve near-optimal performance on several critical use cases. To learn more, see OpenAI Triton on NVIDIA Blackwell Boosts AI Performance and Programmability, co-authored by NVIDIA and OpenAI.
Summary
NVIDIA Blackwell architecture incorporates many breakthrough capabilities that help accelerate generative AI inference, including second-generation Transformer Engine with FP4 Tensor Cores and fifth-generation NVLink with NVLink Switch. NVIDIA announced world-record DeepSeek-R1 inference performance at NVIDIA GTC 2025. A single NVIDIA DGX system with eight NVIDIA Blackwell GPUs can achieve over 250 tokens per second per user or a maximum throughput of over 30,000 tokens per second on the massive, state-of-the-art 671 billion parameter DeepSeek-R1 model.
A rich suite of libraries, now optimized for NVIDIA Blackwell, will enable developers to achieve significant increases in inference performance for both today’s AI models and tomorrow’s evolving landscape. Learn more about the NVIDIA AI Inference platform and stay informed about the latest AI inference performance updates.
Acknowledgements
This work would not have been possible without the exceptional contributions of many, including Matthew Nicely, Nick Comly, Gunjan Mehta, Rajeev Rao, Dave Michael, Yiheng Zhang, Brian Nguyen, Asfiya Baig, Akhil Goel, Paulius Micikevicius, June Yang, Alex Settle, Kai Xu, Zhiyu Cheng, and Chenjie Luo.