
The NVIDIA CUDA-Q platform is designed to streamline software and hardware development for hybrid, accelerated quantum supercomputers. Users can write code once, test it on any QPU or simulator, and accelerate all parts of the workflow. This liberates time for achieving scientific breakthroughs rather than waiting for results.
CUDA-Q v0.10 has more features and increased performance, making it more indispensable and flexible than ever. For example, users can now run jobs on Pasqal’s neutral atom QPU, totaling eight QPU backends of four different qubit modalities. CUDA-Q v0.10 also now supports state-of-the-art NVIDIA Blackwell GPUs.
Achieving performance and scale with CUDA-Q support for NVIDIA GB200 NVL72
CUDA-Q performance can now be pushed further than ever with v0.10 support for the NVIDIA GB200 NVL72 and its fifth-generation multinode NVLink capabilities. This is demonstrated with performance data based on a number of standardized Quantum Economic Development Consortium (QED-C) benchmark applications. This is part of a broader collaboration between NVIDIA and the QED-C to improve industry metrics for assessing quantum computers.
Founding chair of the QED-C Standards and Performance Metrics Technical Advisory Committee Tom Lubinski said, “It is critical for quantum benchmarking efforts to move towards transparent and unbiased metrics and we are glad to work with NVIDIA towards better industry standardization.” The QED-C benchmarking GitHub repo now includes CUDA-Q so users can test its simulation performance on a prepared set of standard applications by running a single notebook.
The power of the full platform, from CUDA-Q to Blackwell, is demonstrated with QED-C benchmarks for simulating Hamiltonians from the HamLib dataset. HamLib consists of Hamiltonians for a diverse array of problems ranging from chemistry to optimization problems.
A 33-qubit state vector simulation of a Hamiltonian simulation problem is 34x faster on a single NVIDIA GB200 (two Blackwell GPUs per chip) compared to a 192-core 2-socket EPYC CPU and 2x faster than the previous generation NVIDIA GH200 Grace Hopper Superchip. This means a week’s worth of simulations can be run in a few hours on a GB200 chip, significantly boosting productivity.

The greatest benefits of GB200 come from its all-to-all connectivity between GPUs which allow the NVIDIA GB200 NVL72 platform to accelerate and scale CUDA-Q simulations with up to all 72 GPUs.
Based on benchmarks run up to 32 GPUs, users can further boost the rate of running the 33-qubit simulations by 10x, reducing the wait from hours on a single Blackwell GPU to minutes. A second option is to pool the memory of the 32 GPUs to perform more impactful large-scale simulations of up to 38 qubits. In this case, the benefits of the high-bandwidth NVLink connections also shine as the GB200 NVL72 system is over 6x faster than the previous InfiniBand connected GH200 chips.
The newly announced NVIDIA Accelerated Quantum Research Center (NVAQC) will connect eight GB200 NVL72 systems to form a powerful supercomputer totaling 576 GPUs to help facilitate needle moving quantum computing breakthroughs with CUDA-Q.
Quantum researchers and developers from across industry and academia are realizing the power of CUDA-Q and using it to develop some of the most cutting edge quantum applications to date. This post explores how NVIDIA partners are accelerating their work with CUDA-Q for applications ranging from chemical simulation to image processing.
Seamless end-to-end workflows with CUDA-Q
NVIDIA, IonQ, Amazon, and AstraZeneca have built an end-to-end accelerated quantum chemistry workflow leveraging CUDA-Q within Amazon Braket with the goal of modeling the nickel-catalyzed Suzuki–Miyaura Cross-Coupling reaction. This is of interest to AstraZeneca as it is a key reaction in the synthesis of drug molecules.
Using a technique known as Quantum-Classical Auxiliary Field Quantum Monte Carlo (QC-AFQMC), this problem can be addressed by combining the strengths of quantum hardware and AI supercomputers. The capability of CUDA-Q to enable studies like these also provides an important exploratory springboard for AstraZeneca to investigate much broader questions around chemical reactivity and quantum computing.
The workflow runs on CUDA-Q, an IonQ Forte quantum computer, and NVIDIA H200 Tensor Core GPUs through Amazon Braket and AWS ParallelCluster. It is divided into a quantum part and a classical part. First, a 32-qubit variational quantum eigensolver (VQE) is used to prepare an approximate ground state. The classical representation of this state is extracted with a tomography technique called Matchgate Shadows. This output is then classically postprocessed and used in an AFQMC procedure to further refine the ground state energy (Figure 2).

Accelerating the classical portion greatly improved the rate at which the team could test improvements to the entire workflow.
This same sort of workflow is also advantageous for developing AI for quantum applications such as the generative quantum eigensolver (GQE) and recently published work, which extend GQE to generate circuits for combinatorial optimization problems.
CUDA-Q is the only platform that provides both the community hardware integrations and the performance necessary for such hybrid algorithms research. The continued expansion of CUDA-Q, with an ever-increasing number of software and hardware integrations, makes it increasingly accessible to accelerate new applications.
Scaling with multi-GPU acceleration
CUDA-Q is pushing the limits of hybrid application development. The CUDA-Q kernel-based programming model makes it easy to leverage multiple GPUs to both parallelize and scale experiments. This leads to faster development cycles and more impactful results, which is why industry and academic partners are transferring their workloads to CUDA-Q.
Aramco is using CUDA-Q to develop hybrid workflows for image processing applications. The objective is a quantum workflow capable of identifying object boundaries within three dimensional images, an important tool for many applications including the analysis of large geospatial images.
Classical edge detection scales exponentially as each pixel must be processed individually. Quantum approaches like quantum Hadamard edge detection (QHED) take advantage of the fact that a 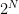 pixel image can be encoded efficiently on a quantum computer using only n+1 qubits (Figure 3). They potentially provide an exponential speedup for processing high-resolution images.
pixel image can be encoded efficiently on a quantum computer using only n+1 qubits (Figure 3). They potentially provide an exponential speedup for processing high-resolution images.

The CUDA-Q MQPU backend enables this algorithm to be parallelized using multiple GPU simulated QPUs, one virtual QPU for running QHED on each dimension of the image. This dramatically shortens development cycles for algorithm testing.
The CUDA-Q MQPU backend also enables users to develop applications inherently ready for tomorrow’s heterogenous accelerated quantum supercomputers which will contain multiple QPUs. This forward-thinking is a key motivation for other projects underway between NVIDIA and HPE.
At NVIDIA GTC 2025 Hewlett Packard Enterprise (HPE) announced results exploring methods for distributing large quantum circuits across accelerated quantum supercomputers, a central theme of the recently published position paper, How to Build a Quantum Supercomputer: Scaling from Hundreds to Millions of Qubits.
The HPE team is using CUDA-Q to develop methods for adaptive circuit knitting (ACK), an approach for dynamically partitioning large circuits across small QPUs by making optimal cuts at low-entanglement sites. This approach, which minimizes the cost associated with the circuit cutting, allows subcircuits to be run on multiple quantum processors or AI supercomputers (Figure 4).

Benchmarking the ACK algorithm at scale relies on large-scale statevector simulations, which are needed to ensure the results from subcircuits align with the originally intended circuit. This validation is supported by the CUDA-Q MGPU backend, which pools GPU memory, so HPE can run simulations of up to 40 qubits across 1024 GPUs on NERSC’s Perlmutter supercomputer. The simulations all complete in under 34 minutes with some as fast as 12 minutes and are not feasible to run on a CPU.
CUDA-Q can also accelerate ACK testing by facilitating the distribution of the many involved subcircuits across multiple GPU-simulated QPUs, through its MQPU backend.
Get started quickly with CUDA-Q
A hallmark of CUDA-Q design is its ease of use. Its performance, scalability, and flexibility is not gated to quantum experts, but open to anyone, even those learning quantum for the first time. The NVIDIA CUDA-Q Academic initiative makes getting started even easier.
CUDA-Q Academic is helping to foster a skilled quantum workforce through partnerships with over 25 leading universities. A recent collaboration with King Abdullah University of Science and Technology (KAUST) demonstrated its effectiveness with a hands-on workshop for faculty and students.
This workshop, based on the freely available NVIDIA Quick Start to Quantum Computing series, covered key topics such as quantum states and gates, kernel construction, and variational quantum algorithms. The workshop’s four interactive labs progressed from single-qubit programming, to more complex tasks, including coding a discrete time quantum walk, and accelerating hybrid programs with GPUs using CUDA-Q.

KAUST Professor of Applied Mathematics and Computational Science and director of the KAUST Extreme Computing Research Center David Keyes described the NVIDIA Quick Start to Quantum Computing series as “a gratifying experience, demonstrating how one can go from no knowledge of quantum computing to running applications on GPUs in a few short sessions. NVIDIA CUDA-Q is a pleasure to use and a great resource for understanding the practical aspects of accelerating hybrid applications.”
These educational resources, along with more advanced materials such as an introduction to circuit cutting through the divide-and-conquer approach to max cut with QAOA, are openly available in the CUDA-Q Academic GitHub repo. This repo provides valuable pathways for anyone looking to develop high performance computing and quantum computing skills necessary for accelerated quantum computing.
Learn more
The NVIDIA CUDA-Q platform is becoming the industry standard for developing hybrid applications with performance, flexibility, and ease. This is made clear by the many additional NVIDIA GTC 2025 announcements made by quantum community members producing fantastic and diverse results with CUDA-Q.
You can install CUDA-Q to start designing your own hybrid applications and try out the many example applications in the CUDA-Q documentation. To learn about all of the tools NVIDIA is working on to accelerate quantum computing development, visit NVIDIA Quantum.












