Scikit-learn, the most widely used ML library, is popular for processing tabular data because of its simple API, diversity of algorithms, and compatibility with popular Python libraries such as pandas and NumPy. NVIDIA cuML now enables you to continue using familiar scikit-learn APIs and Python libraries while enabling data scientists and machine learning engineers to harness the power of CUDA on NVIDIA GPUs without changing any application code.
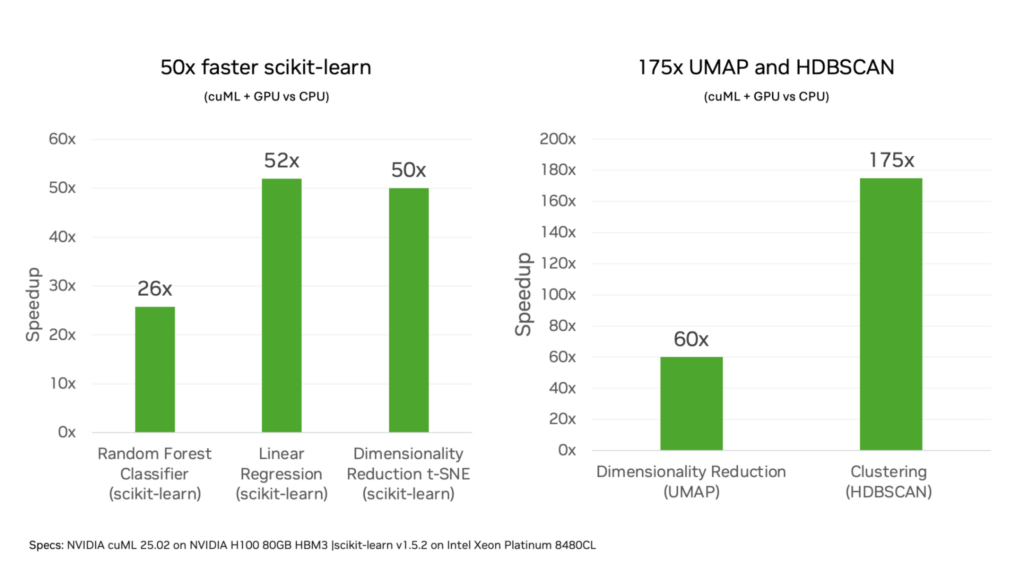
In NVIDIA cuML 25.02, we’re releasing the capability to accelerate scikit-learn algorithms with zero code change in open beta. NVIDIA cuML, first introduced in 2019, has been rapidly adding CUDA-based GPU algorithms for Python machine learning. The latest release enables data scientists and machine learning engineers to keep scikit-learn applications unchanged and achieve 50x faster performance on NVIDIA GPUs compared to CPUs.
This new version of cuML also accelerates UMAP and HDBSCAN, leading algorithms for dimensionality reduction and clustering, up to 60x and 175x on NVIDIA GPUs vs CPUs with zero code change.
In this post, we discuss how the new zero-code-change capability in cuML works and show examples of how to adopt it for scikit-learn applications.
Overview
Training ML models on CPUs can take several minutes for a single run. The slowdowns accumulate over multiple iterations and hyperparameter sweeps, resulting in lower developer productivity, fewer iterations, and lower-quality models.
This cuML release extends the zero-code-change acceleration paradigm established by cuDF-pandas for DataFrame operations to machine learning, reducing iterations to seconds with zero changes to the code.
In the past, data scientists had to customize the application to speed up applications using NVIDIA GPUs. This made it harder to develop, train, and inference on different platforms.
With the new zero-code-change capabilities in cuML, existing scikit-learn scripts can run unchanged. cuML automatically accelerates compatible components on NVIDIA GPUs and falls back to CPU execution for unsupported operations. This makes it possible to develop on CPUs and deploy on GPUs and the reverse, based on your application needs.
The beta release currently accelerates the most popular scikit-learn algorithms with zero-code-change including random forest, k-Nearest Neighbors, principal component analysis (PCA), and k-means clustering. For more information about the full list of supported methods, see What Does cuML-accel Accelerate? Ongoing development will prioritize additional algorithm coverage based on user feedback.
To get the highest performance for your ML pipeline on NVIDIA GPUs, minimize data transfers between the CPUs and GPUs as part of your pipeline. This can be done by loading the data once onto the GPU and then performing preprocessing, ML training, and inference before sending back results to the host memory.
To transition a CPU pipeline with NumPy pandas, and scikit-learn, use cuPy, cuDF-pandas, and cuML before sending back results. The capability to use cuDF-pandas and cuML zero code change is experimental in this release and we encourage you to try it on your pipeline.
To get the highest performance during inference for ML models, you can use libraries and modules in the CUDA-X ecosystem to run on GPUs.
For example, to perform inference on random forest models use the Forest Inference Library (FIL) module in the cuML library. This can be used with the NVIDIA Triton inference server to deploy and scale AI models in production.
Behind the scenes with cuML zero code change for scikit-learn
The cuML zero code change capability is implemented with the cuml.accel module. When it is enabled, importing scikit-learn or its algorithm classes activates a compatibility layer that proxies model types and functions.
Operations on these proxy objects execute on NVIDIA GPUs through cuML where supported, falling back to CPU-based scikit-learn implementations otherwise. Synchronization between device and host memory occurs automatically, even when integrating with third-party libraries that use scikit-learn internally.
When a scikit-learn estimator is called, the proxy object generates a GPU-accelerated (cuML) model instance if the estimator is supported in cuML or creates a CPU-native (scikit-learn) model instance if not.
For supported estimators, the method calls first to attempt GPU execution, copying input data to device memory if needed. For unsupported operations, the system transparently shifts computation to the CPU by reconstructing the model on CPU and copying data to it if needed.
cuML transparently translates between the scikit-learn object on CPU and cuML object on GPU in the back end when needed, enabling truly zero code change capabilities.
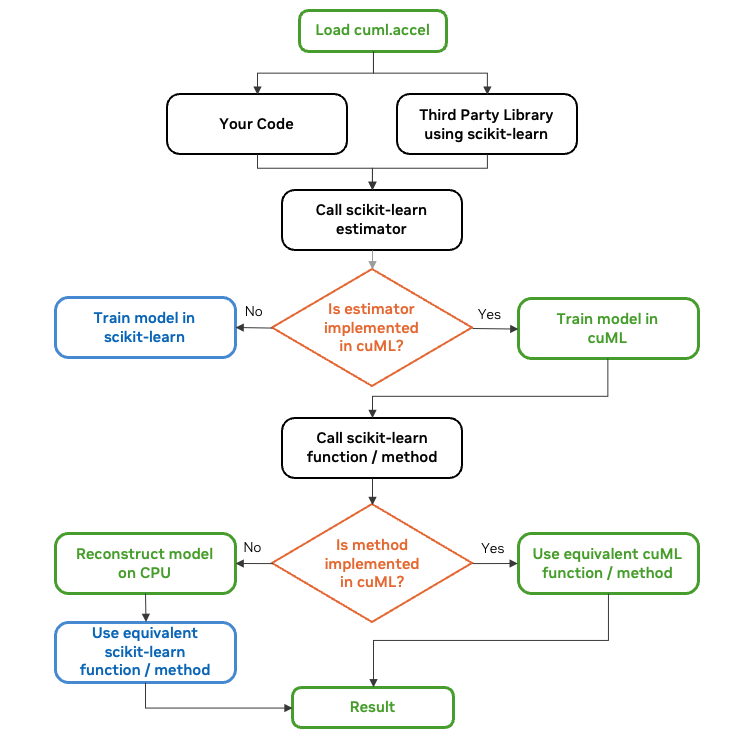
With cuml.accel, cuML automatically translates hyperparameters and aligns outputs with scikit-learn’s conventions to ensure compatibility with other libraries in the Python ecosystem This ensures parity with CPU-based workflows while accelerating supported algorithms.
In some cases such as random forest, cuML has approached the implementation differently than scikit-learn to take advantage of the enormous parallelism of NVIDIA GPUs.
Algorithms in cuML are designed to process many rows of input at the same time before combining outputs, manage GPU memory to avoid costly allocations and use parallel-friendly versions of algorithms. This is expected to generate numerically equivalent results that are not always identical due to the different order of operations or accumulation of errors with the algorithms.
Machine learning datasets can exceed GPU memory capacity in some cases. The cuml.accel module automatically uses CUDA unified memory. With unified memory, host memory can be used along with GPU memory and data migrations between both are performed automatically as needed. This expands the effective memory available for ML processing to the sum of GPU and host memory.
How to use cuML to accelerate scikit-learn code
The new version of NVIDIA cuML with zero code changes for scikit-learn is preinstalled in Google Colab.
In Jupyter notebooks, use the following command at the beginning of the notebook before other imports:
%load_ext cuml.accelimport sklearn |
To install cuML on various local and cloud environments, see the RAPIDS Installation Guide. Use the Python script with a python module flag to accelerate your unchanged scikit-learn script:
python -m cuml.accel unchanged_script.py |
Here’s a simple scikit-learn application that trains a random-forest model on a dataset with 500K samples and 100 features.
%load_ext cuml.accelfrom sklearn.datasets import make_classificationfrom sklearn.model_selection import train_test_splitfrom sklearn.ensemble import RandomForestClassifierX, y = make_classification(n_samples=500000, n_features=100, random_state=0)X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)rf = RandomForestClassifier(n_estimators=100, random_state=0, n_jobs=-1)rf.fit(X_train, y_train) |
For more information about what components of the model were run on GPU compared to the components needed to fall back, add the logger object to the function. This code example sets the logging level to DEBUG:
%load_ext cuml.accelfrom cuml.common import logger; logger.set_level(logger.level_enum.debug)from sklearn.datasets import make_classification… |
When executed, the logger object emits messages capturing where each command was executed. In the example from earlier, the fit function is executed on the GPU:
cuML: Installed accelerator for sklearn.cuML: Installed accelerator for umap.cuML: Installed accelerator for hdbscan.cuML: Successfully initialized accelerator.cuML: Performing fit in GPU. |
Benchmarks
We compared the performance of training scikit-learn algorithms on Intel Xeon Platinum 8480CL CPU to the H100 80GB GPU across representative workloads such as classification and regression. We observed that common algorithms such as random forest can speed up by 25x during training, bringing down the time from minutes on CPUs to seconds on GPUs.
Clustering and dimensionality reduction algorithms are much more computationally complex and typically used with larger dataset sizes. In these cases, GPUs can reduce training time from hours on CPUs to minutes. For more information about a wider set of results, see Zero Code Change Benchmarks.
Speedup from GPU acceleration is influenced by the following factors:
- The higher the computational complexity of the algorithm, the larger the speedup from GPU acceleration. More computationally complex algorithms can shadow overheads from data transfer and initialization.
- Higher feature counts increase GPU utilization efficiency, as parallel compute resources process more operations concurrently leading to higher speedups.
Get started with cuML
NVIDIA cuML introduces a simple way to accelerate scikit-learn, UMAP, and HDBSCAN applications on NVIDIA GPUs using zero code change capabilities as a beta release. cuML can now access the power of NVIDIA GPUs and CUDA algorithms where possible and fall back to scikit-learn on CPU transparently when a function is not yet supported. We have observed 50x faster training for scikit-learn, 60x for UMAP and 250x for HDBSCAN.
For more information about this capability, see NVIDIA cuML. For more examples of this capability, see the Google Colab notebook. The latest version of cuML, with zero code change capabilities, is preinstalled in Google Colab.?
We encourage you to download the latest version and try on your application. You can always share your feedback with us on Slack at #RAPIDS-GoAi.
For self-paced and instructor-led courses, see the DLI Learning Path for Data Science.