With the rise of physical AI, video content generation has surged exponentially. A single camera-equipped autonomous vehicle can generate more than 1 TB of video daily, while a robotics-powered manufacturing facility may produce 1 PB of data daily.
To leverage this data for training and fine-tuning world foundation models (WFMs), you must first process it efficiently.
Traditional fixed-capacity batch processing pipelines struggle with this scale, often underusing GPUs and failing to match the required throughput. These inefficiencies slow down AI model development and drive up costs.
To address this challenge, the NVIDIA NeMo Curator team developed a flexible, GPU-accelerated streaming pipeline for large-scale video curation now available on NVIDIA DGX Cloud. In this post, we explore the optimizations made in the pipeline including auto-scaling and load-balancing techniques to ensure optimized throughput across pipeline stages while fully using available hardware.
The result? Higher throughput, lower total cost of ownership (TCO), and accelerated AI training cycles, speeding up end user outcomes.
Load balancing with auto-scaling
Traditional data processing often relies on batch processing, where large volumes of data are accumulated to process at one time, progressing through one stage at a time.

This introduces two primary problems:
- Efficiency: It’s difficult to efficiently use heterogeneous resources. When the batch is working on a CPU-heavy stage, the GPU resources will be underused, and the reverse is also true.
- Latency: The need to store and load intermediate data products to and from the cluster storage between processing stages introduces significant latency.
In contrast, streaming processing directly pipes intermediate data products between stages, and begins next-stage processing on individual data as soon as the previous stages are complete.
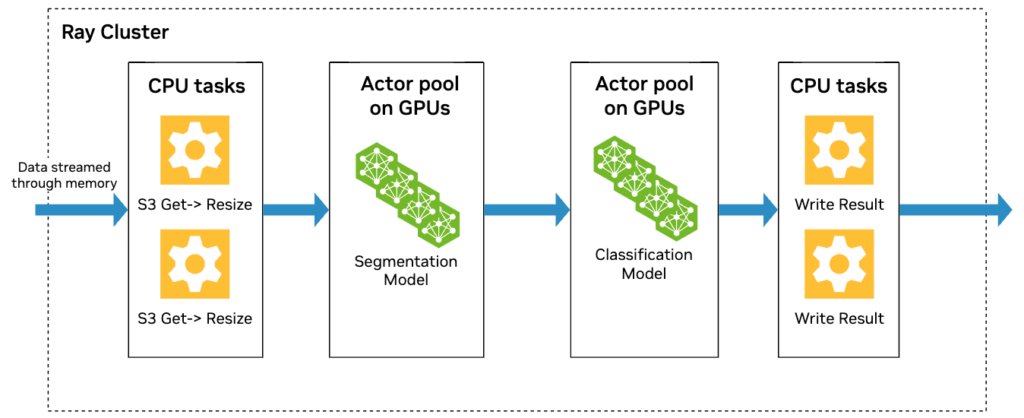
The challenge here is the need to balance throughput between stages, as well as the desire to separate CPU-primary and GPU-primary workloads.
Balanced throughput
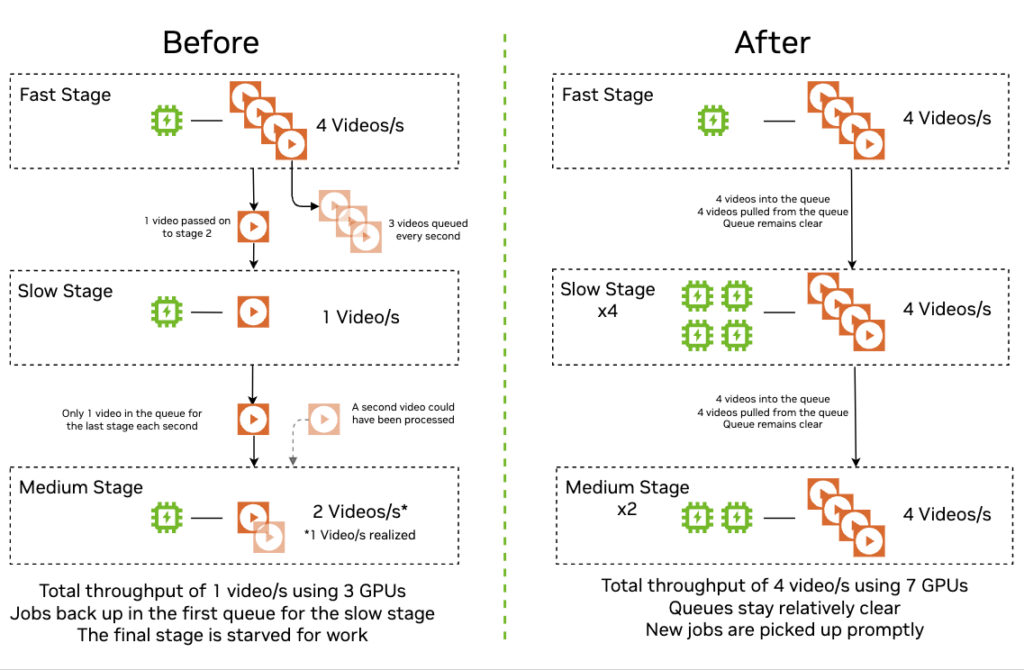
In the simplest case, if you have two stages, one running twice as fast as the next, then the slow stage acts like a bottleneck, and the overall throughput and performance of the pipeline is limited to that of the slow stage. You also risk in-memory build-up of intermediate work products, necessitating costly catch-up periods where compute resources may be idle. In this case, you can solve this problem by running twice as many copies of the slow stage, in a data-parallel manner.
Visually, a multi-stage video processing pipeline with heterogeneous throughput with and without auto-scaling and load balancing may have significant performance and hardware use differences:
Separating CPU-primary and GPU-primary workloads
Another key insight was the need to split out CPU-dominant tasks, such as video download or clip transcode, from GPU-dominant tasks, such as generating embeddings or running AI classifiers.
A helpful way to think about this is to imagine each pipeline stage as a vector in a two-dimensional resource space, where one axis represents CPU demand and the other represents GPU demand. If you combine all the heavy lifting into a single stage that demands, say, 70% CPU and 30% GPU, you can only scale that same ratio up or down which just multiplies that singular usage vector by different amounts. This often leaves resources underused when the cluster resources don’t match that ratio.
In contrast, you have more vectors to work with if you separate tasks into distinct CPU-dominant and GPU-dominant stages. This lets you mix, match, and overlap multiples of those vectors to more closely align with your infrastructure’s actual CPU and GPU capacity. As a result, you can use both CPU and GPU resources, avoiding situations where one type of resource sits idle while the other is overloaded.
Architecture and implementation details
Our overall pipeline divides the video curation task into several stages built on top of Ray:

The video curation pipeline involves several stages (Figure 4) starting from ingesting raw video files and splitting them into clips (Video Decode and Splitting), transcoding the clips to a consistent format, applying quality filters to generate metadata, producing text captions in the annotation stage, and finally computing embeddings—both for textual descriptions and video content.
For each stage, the main orchestration thread manages a pool of Ray actors, each of which is a worker instance for that stage. Multiple actors can process different input videos in parallel, so the stage’s throughput scales linearly with the actor pool size.
The orchestration thread also manages an input queue and an output queue for each stage. As it moves processed pipeline payloads (that is, video and its metadata) from one stage to the next, the orchestration thread can continuously measure the overall throughput of each stage.
Based on the relative throughput, the orchestration thread scales the actor pool size of each stage at three-minute intervals accordingly, so there are more actors for slower stages. The pure-CPU stages can then be over-provisioned so that GPU stages are kept busy even when there is fluctuation in the pipeline.
One thing worth mentioning is that the main orchestration thread does not move the actual data across stages. It’s the object reference, which can be understood as a pointer to the actual data in the global Ray object store, that is being moved from the output queue of stage N to the input queue of stage N+1. As a result, the load on the orchestration thread is low.
Results and impact
When comparing batch execution vs. the streaming data pipeline, you can achieve more optimal system resource usage with streaming data (Figure 5).

In this case, the streaming pipeline requires ~195 seconds to process one hour of video per GPU, while the batch pipeline requires ~352 seconds to do the same: resulting in a ~1.8x speedup.
Next steps
Our efforts with auto-scaling and load balancing are only part of the performance optimization work that has enabled us to achieve a 89x performance improvement to date above baseline, resulting in a pipeline capable of processing ~1M hours of 720p video data on 2k H100 GPUs in one day.

*Performance compared with ISO power consumption on 2K CPUs and 128 DGX nodes.
The efficient use of GPU resources can be further demonstrated by tracking the worker utilization of GPU stages of the NeMo Curator pipeline during execution.
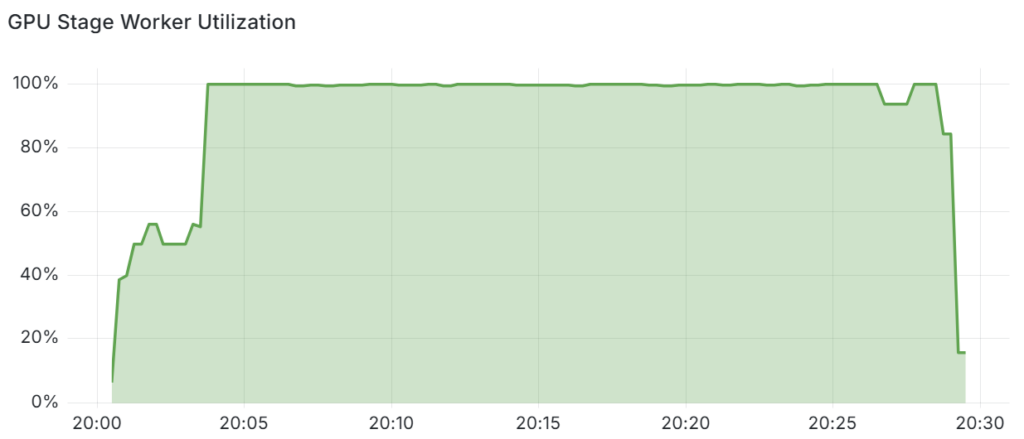
Figure 7 shows that, after an initial warm-up period, the auto-scaler can rearrange the resources such that GPU stage workers are kept busy over 99.5% of the time.
This experiment was done with 32 GPUs on four nodes. If you run with fewer GPUs, the GPU worker usage will be lower because the auto-scaler has a coarser granularity for GPU allocation. If you run with more GPUs, the GPU worker usage will be even closer to 100%.
To explain with an example, assume that GPU stage X is 20x faster than another GPU stage Y:
- In the current 32-GPU experiment, we allocated two GPUs to stage X and 30 GPUs to stage Y.
- With only eight GPUs, we still had to allocate one GPU to stage X and only seven GPUs to stage Y, resulting in the stage X GPU being idle more often.
- With 64 GPUs, we achieved a near-perfect breakdown with three GPUs for stage X and 61 GPUs for stage Y. Overall GPU stage worker utilization is virtually 100%.
This is exactly why we observed super-linear throughput scalability when we increased the number of GPUs in one job.
Request early access
We have been actively working with a variety of early access account partners to enable best-in-class TCO for video data curation, unlocking the next generation of multi-modal models for physical AI and beyond:
- Blackforest Labs
- Canva
- Deluxe Media
- Getty Images
- Linker Vision
- Milestone Systems
- Nexar
- Twelvelabs
- Uber
To get started without needing your own compute infrastructure, NeMo Video Curator is available through early access on NVIDIA DGX Cloud. Submit your interest in video data curation and model fine-tuning to the NVIDIA NeMo Curator Early Access Program and select “managed services” when submitting your interest.
NeMo Video Curator is also available through early access as a downloadable SDK, suitable for running on your own infrastructure, also through the Early Access Program.