以前のブログ記事では、key-value (KV) キャッシュを CPU メモリにオフロードして再利用することで、最初のトークンが出力されるまでの時間 (TTFT: Time To First Token) を x86 ベースの NVIDIA H100 Tensor コア GPU で最大 14 倍、NVIDIA GH200 Superchip で最大 28 倍に高速化できる方法をご紹介しました。本記事では、KV キャッシュの再利用技術と、TTFT のさらなる高速化を実現するベストプラクティスについて解説します。
KV キャッシュの概要
LLM モデルは、質問回答やコード生成など、多くのタスクで急速に採用されています。応答を生成するにあたり、これらのモデルはまず、ユーザーのプロンプトをトークンへ変換し、その後これらのトークンを密ベクトルへと変換します。膨大なドット積演算がその後に続き、その後トークン間の関係性を數學的にモデル化し、ユーザー入力に対する文脈理解を構築します。この文脈理解を生成するためにかかる計算コストは、入力シーケンスの長さの二乗に比例して増加します。
このリソースを大量に消費するプロセスから key とvalue が生成され、後続のトークンを生成するときに再度計算されないようにキャッシュされます。KV キャッシュを再利用することで、追加のトークンを生成する際に必要となる計算負荷と時間が軽減され、より高速で効率的なユーザー體験を実現します。
KV キャッシュを再利用するときには、キャッシュがメモリに殘る期間、メモリが一杯になったときに最初に削除するコンポーネント、および新しい入力プロンプトに再利用できるタイミングなどの點に細心の注意を払う必要があります。これらの要因を最適化することで、KV キャッシュの再利用におけるパフォーマンスの段階的な増加へとつなげることができます。NVIDIA TensorRT-LLM は、これらの分野に特化した 3 つの主要な機能を提供します。
Early KV cache reuse
従來の再利用アルゴリズムでは、KV キャッシュをその一部であっても新しいユーザー プロンプトで再利用するためには、事前にすべての KV キャッシュの計算を完了させておく必要がありました。この方法は、LLM のレスポンスを企業のガイドラインに沿ったものにするために、システム プロンプト (ユーザーの問い合わせに追加される事前定義の指示) が不可欠となる企業向けチャットボットなどのシナリオでは、非効率的である可能性があります。
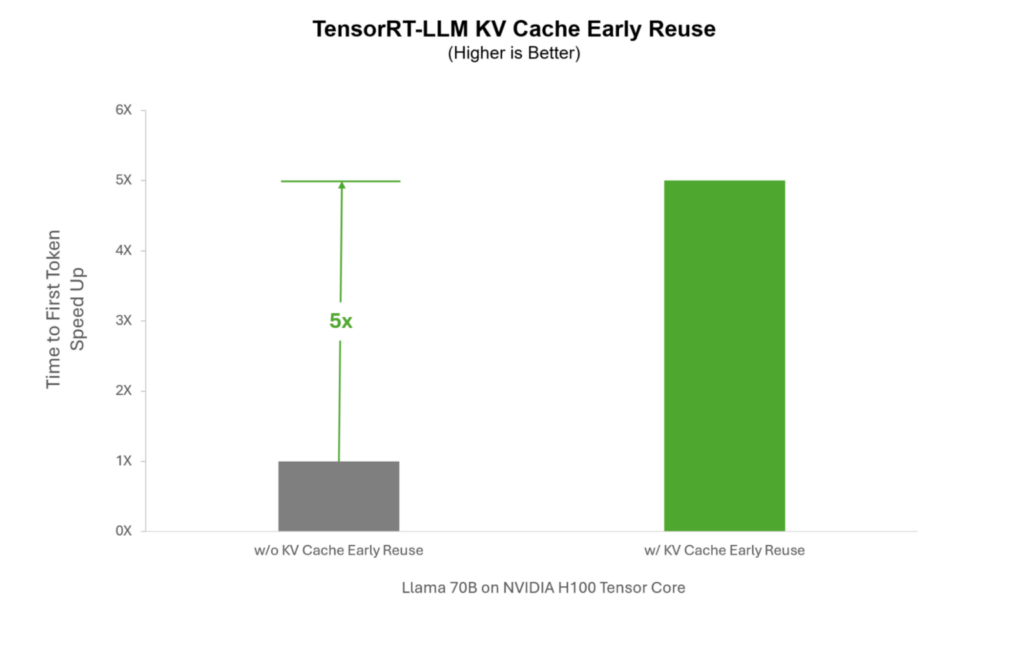
チャットボットと同時にやり取りするユーザーが急増した場合、各ユーザーに対してシステム プロンプト KV キャッシュを個別に計算する必要があります。TensorRT-LLM では、リアルタイムで生成されるシステム プロンプトを再利用することができるため、急増時にはすべてのユーザーと共有することができ、ユーザーごとに再計算する必要がありません。これにより、システム プロンプトを必要とするユース ケースの推論を最大 5 倍にまで高速化することができます。
柔軟な KV キャッシュ ブロック サイズ
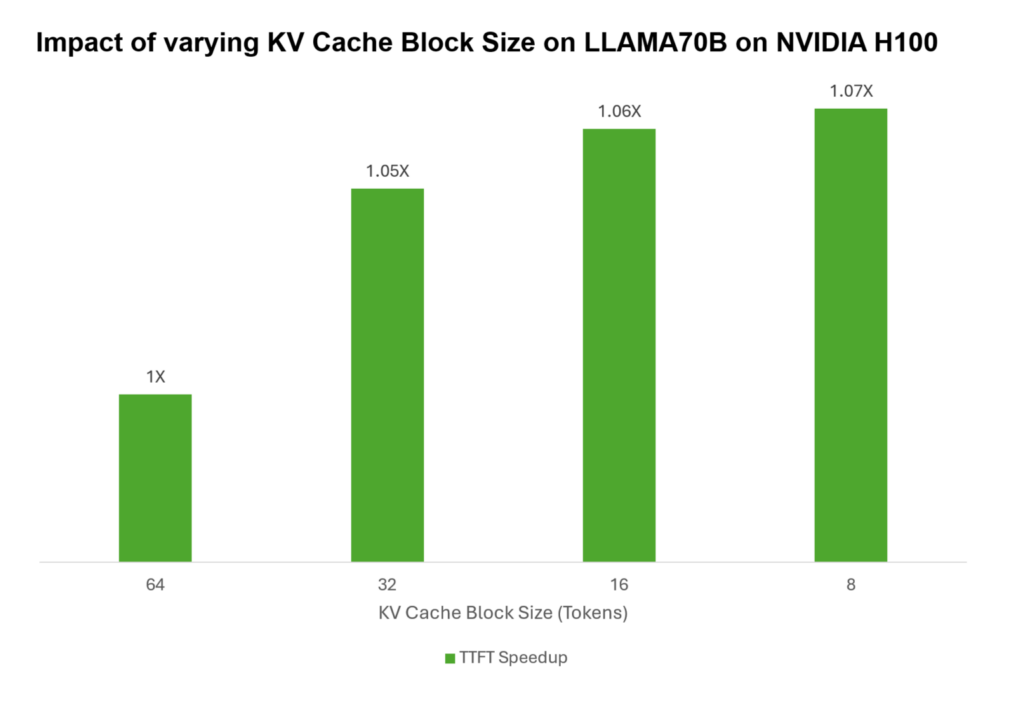
再利用を実裝する際には、キャッシュ メモリ ブロック全體のみを再利用に割り當てることができます。例えば、キャッシュ メモリ ブロック サイズが 64 トークンで、KV キャッシュが 80 トークンである場合、再利用のために保存できるのは 64 トークンのみであり、殘りの 16 トークンは再計算する必要があります。しかしながら、メモリ ブロック サイズを 16 トークンに減らすと、64 トークンすべてを 5 つのメモリ ブロックに格納することができ、再計算の必要性がなくなります。
この効果は、入力シーケンスが短いときに最も顕著に現れます。長い入力シーケンスの場合は、より大きなブロックの方がより有益です。明らかに、KV キャッシュをより細かく制御できればできるほど、特定のユース ケースに合わせた最適化も向上します。
TensorRT-LLM では、KV キャッシュ メモリ ブロックをきめ細かく制御できるため、開発者は KV キャッシュ メモリ ブロックを 64 から 2 トークンまで、より小さなブロックに分割することができます。これにより、割り當てられたメモリの使用が最適化され、再利用率が上昇し、TTFT が改善されます。NVIDIA H100 Tensor コア GPU で LLAMA70B を実行する場合、KV キャッシュ ブロックサイズを 64 トークンから 8 トークンへと減らすことで、マルチユーザー環境で TTFT を最大 7% 高速化できます。
効率的な KV キャッシュの除外 (Eviction) プロトコル
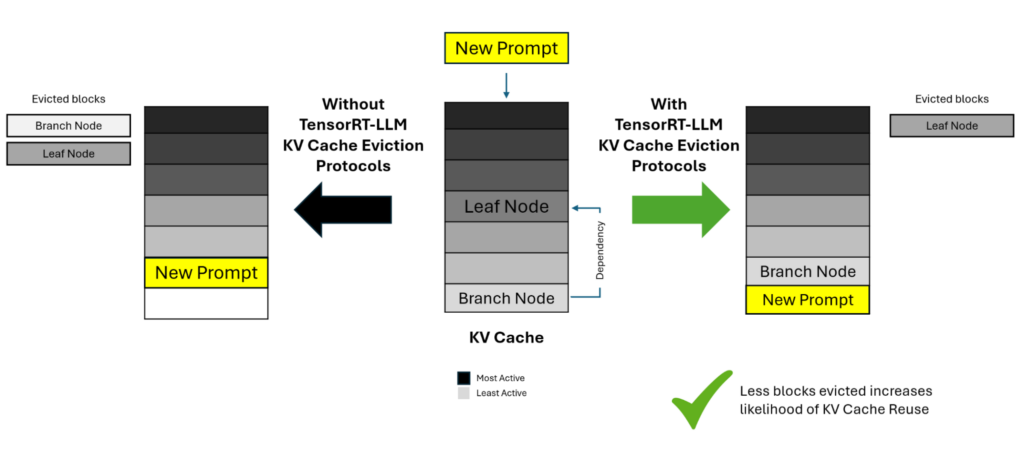
KV キャッシュをより小さなブロックに分割し、未使用のブロックを除外することは、メモリの最適化に効果的ですが、依存関係に複雑さが生まれます。特定のブロックがレスポンスの生成に使用され、その結果が新しいブロックとして保存されると、依存関係のツリー構造が形成される可能性があります。
時間の経過とともに、ソース ブロック (ブランチ) の使用を追跡するカウンターは、従屬ノード (リーフ) が再利用されるにつれて古くなる可能性があります。ソース ブロックを除外するには、従屬するすべてのブロックを除外する必要があり、新しいユーザ プロンプトの KV キャッシュを再計算する必要が生じて TTFT が増加します。
この課題に対処するために、TensorRT-LLM には、従屬ノードをソース ノードから追跡し、従屬ノードがより最近の再利用カウンターを持っている場合でも、最初に従屬ノードを除外することができるインテリジェントな除外アルゴリズムが含まれています。これにより、より効率的にメモリを管理できるようになると共に、従屬ブロックの不要な除外を回避できます。
TensorRT-LLM KV cache reuse を使い始める
推論中に KV キャッシュを生成するには、多くの計算とメモリ ソースが必要になります。効率的に使用することが、モデル応答の改善、推論の高速化、システム スループットの向上には不可欠です。TensorRT-LLM は、ピーク性能のために TTFT 応答時間をさらに最適化しようとする開発者に高度な再利用機能を提供します。?
TensorRT-LLM KV cache reuse を使い始めるには、GitHub のドキュメントを參照してください。