PyTorch と NVIDIA TensorRT を新たに統合し、1 行のコードで推論を高速化する Torch-TensorRT に期待しています。PyTorch は、今では代表的なディープラーニング フレームワークであり、世界中に數百萬人のユーザーを抱えています。TensorRT はデータ センター、組み込み、および車載機器で稼働する GPU アクセラレーションプラットフォーム全體で、高性能なディープラーニングの推論を行うための SDK です。この統合により、PyTorch ユーザーは TensorRT を使用する際、簡素化されたワークフローを通じて非常に高い推論性能を得ることができます。
Torch-TensorRT とは
Torch-TensorRT は、TensorRT の推論最適化を NVIDIA GPU で利用するための PyTorch の統合ソフトウェアです。たった 1 行のコードで、NVIDIA GPU 上で最大 6 倍の性能向上を実現するシンプルな API を提供します。
この統合は、FP16 や INT8 精度といった TensorRT の最適化を利用する一方で、TensorRT がモデルのサブグラフをサポートしない場合には、ネイティブの PyTorch にフォールバックする機能を提供します。簡単な概要については、Getting Started with NVIDIA Torch-TensorRT ビデオをご覧ください。
Torch-TensorRT の仕組み
Torch-TensorRT は、TorchScript の拡張として動作する。互換性のある部分グラフを最適化して実行し、殘りのグラフは PyTorch に実行させます。PyTorch の包括的で柔軟な機能セットは、モデルを解析し、グラフの TensorRT 互換の部分に最適化を適用する Torch-TensorRT とともに使用されます。
コンパイル後、最適化されたグラフを使用すると、TorchScript モジュールを実行しているように、ユーザーは TensorRT のパフォーマンス向上の恩恵を受けることができます。Torch-TensorRT コンパイラのアーキテクチャは、互換性のあるサブグラフに対して 3 つのフェーズから成ります。
- TorchScript モジュールの単純化
- 転換
- 実行
Torchscript モジュールの単純化
第 1 段階では、Torch-TensorRT は TensorRT に直接マップする表現にするため一般的な操作の実裝を単純化します。この処理がグラフ自體の機能に影響しないことに注意することは重要です。

転換
変換フェーズでは、Torch-TensorRT は TensorRT 互換部分グラフを自動的に識別し、 TensorRT オペレーションに変換します。
- 靜的な値を持つノードを評価し、定數にマップします。
- テンソル計算を記述するノードは 1 つ以上の TensorRT 層に変換されます。
- 殘っているノードは TorchScripting にとどまります。そして、標準的な TorchScript モジュールとして返されるハイブリッド グラフをつくります。
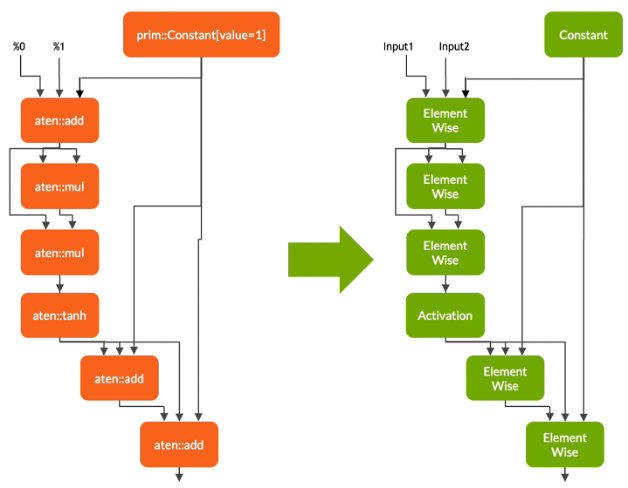
修正されたモジュールは TensorRT エンジン組込んで返されます。そして、それは、全モデル、 PyTorch コード、モデル ウェイト、および TensorRT エンジンが単一のパッケージでポータビリティがあることを意味します。
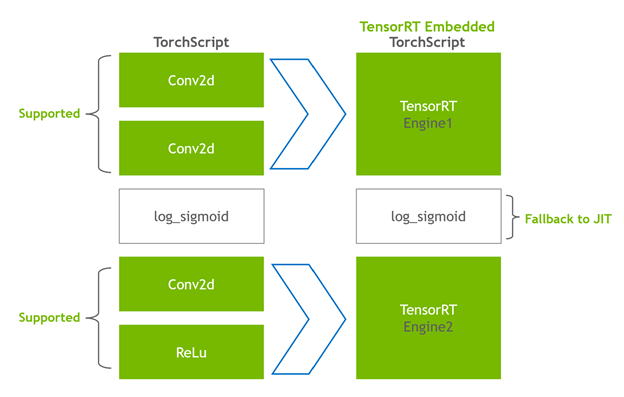
実行
コンパイルされたモジュールを実行すると、Torch – TensorRT はエンジンを有効にして実行可能にします。この修正された TorchScript モジュールを実行すると、TorchScript インタプリターは TensorRT エンジンを呼び出し、すべての入力を渡します。エンジンは実行し、結果を通常の TorchScript モジュールのようにインタプリターに戻します。
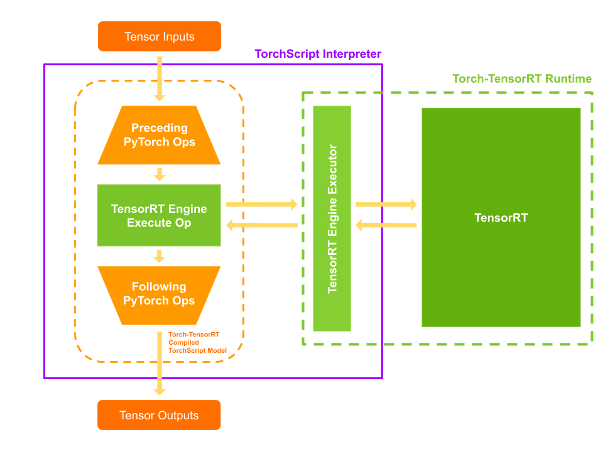
Torch-TensorRT 機能
Torch-TensorRT は次の機能を導入します。INT8 と Sparsity のサポート。
INT8 のサポート
Torch-TensorRT は 2 つの手法で低精度推論のサポートを拡張します。
- トレーニング後の量子化 (PTQ)
- 量子化を考慮したトレーニング (QAT)
PTQ に関して、 TensorRT は目標ドメインからサンプル データでモデルを実行するキャリブレーションステップを使用します。INT8 へ適切にマッピングするために、FP32 の活性化関數をキャリブレーションで調整します。この処理は、FP32 と INT8 推論の情報損失を最小にします。TensorRT アプリケーションでは、 TensorRT Calibrator にサンプル データを提供する Calibrator クラスを記述する必要があります。
Torch-TensorRT は、Calibrator を簡単に実裝するために PyTorch の既存のインフラストラクチャを使用します。LibTorch は、データ処理とデータ入力 API を提供します。これらの API は、あなたが PTQ を使用するのをより簡単にして、C+ と Python インターフェイスを通して提供されます。詳細は トレーニング後の量子化 (PTQ) を參照してください。
QAT のために、 TensorRT は新しい API: QuantizeLayer と DequantizeLayer を導入しました。aten::fake_quantize_per_*_affine のような操作は、內部で Torch-TensorRT によって QuantizeLayer + DequantizeLayer に変換されます。Torch-TensorRT を使用している Pytorch の QAT テクニックで訓練されたモデルを最適化することに関する詳細については、 Torch-TensorRT を用いた INT8 における量子化意識訓練モデルの展開 を見てください。
スパース性
NVIDIA Ampere アーキテクチャは、 NVIDIA A100 GPU に、ネットワーク重みのスパース性を利用した第 3 世代の Tensor コアを採用しています。これらは、ディープラーニングの中心である行列乗算積算の精度を犠牲にすることなく、密な層の計算の最大スループットを提供します。
- TensorRT はこれらの Tensor コア上にディープラーニング モデルのいくつかの疎な層の登録と実行をサポートする。
- Torch-TensorRT は畳み込み層と全結合層に対してこのサポートを拡張します。
スパース性に関する詳細については、NVIDIA Ampere アーキテクチャと NVIDIA TensorRT を使用したスパース性による推論の高速化 を見てください。
畫像分類のためのスループット比較
この記事では、EfficientNet という畫像分類モデルで推論を行い、そのモデルを PyTorch、TorchScript JIT、Torch-TensorRT でエクスポートして最適化した場合のスループットを計算します。詳細については、 Torch-TensorRT Github リポジトリのエンドツーエンドのサンプル ノートを參照してください。
インストールと前提條件
これらの手順に従うには、次のリソースが必要です。
- NVIDIA GPU を搭載した Linux マシン (コンピュート アーキテクチャ 7 以前)
- Docker のインストール (19.03 以降)
- PyTorch、Torch TensorRT、およびすべての依存関係するライブラリがインストールされた Docker コンテナーを NGC カタログから pull できます。
サイトに記載の內容に従って、nvcr.io/nvidia/pytorch:21.11-py3 としてタグ付けされた Docker コンテナーを実行してください。
bash 端末から Docker コンテナー起動し、JupyterLab のインスタンスを起動して Python コードを実行します。ポート 8888 で JupyterLab を起動し、トークンに TensorRT を設定します。ブラウザーの JupyterLab のグラフィカル ユーザー インターフェイスにアクセスするには、システムの IP アドレスを下記のように設定してください。
Jupyter lab --allow-root --IP=0.0.0.0 --NotebookApp.token=’TensorRT’ --port 8888
ポート 8888 でこの IP アドレスをブラウザーに移動します。ローカル システムのこの例を実行している場合は Localhost:8888 に移動します。
ブラウザーで JupyterLab のグラフィカル ユーザー インターフェイスに接続した後、新しい Jupyter ノートブックを作成することができます。timm をインストールすることによってスタートし、 PyTorch ライブラリを事前に訓練されたコンピューター ビジョン モデル、重み、およびスクリプトを含む。このライブラリから EfficientNet-b0 モデルを引き出します。
pip install timm
関連するライブラリをインポートし、EfficientNet-b0 用の PyTorch nn.Module オブジェクトを作成します。
import torch
import torch_tensorrt import timm import time import numpy as np import torch.backends.cudnn as cudnn
torch.hub._validate_not_a_forked_repo=lambda a,b,c: True
efficientnet_b0 = timm.create_model('efficientnet_b0',pretrained=True)
このモデルから予測するために、この efficientnet_b0 オブジェクトの forwardメソッドにランダムな浮動小數點のテンソルを渡します。
model = efficientnet_b0.eval().to("cuda")
detections_batch = model(torch.randn(128, 3, 224, 224).to("cuda"))
detections_batch.shape
これは 128 サンプルと 1000 クラスに対応する [128, 1000] のテンソルを返します。
このモデルを PyTorch JIT と Torch – TensorRT AOT のコンパイル メソッドを通してベンチマークするには、簡単なベンチマーク ユーティリティ関數を書きます:
cudnn.benchmark = True
def benchmark(model, input_shape=(1024, 3, 512, 512), dtype='fp32', nwarmup=50, nruns=1000):
input_data = torch.randn(input_shape)
input_data = input_data.to("cuda")
# if dtype=='fp16':
# input_data = input_data.half()
print("Warm up ...")
with torch.no_grad():
for _ in range(nwarmup):
features = model(input_data)
torch.cuda.synchronize()
print("Start timing ...")
timings = []
with torch.no_grad():
for i in range(1, nruns+1):
start_time = time.time()
pred_loc = model(input_data)
torch.cuda.synchronize()
end_time = time.time()
timings.append(end_time - start_time)
if i%10==0:
print('Iteration %d/%d, avg batch time %.2f ms'%(i, nruns, np.mean(timings)*1000))
print("Input shape:", input_data.size())
このモデルで推論を実行する準備が整いました。
PyTorch と Torchscript を用いた推論
まず、 PyTorch モデルをそのまま取り、バッチ サイズ 1 の平均スループットを計算します。
model = efficientnet_b0.eval().to("cuda")
benchmark(model, input_shape=(1, 3, 224, 224), nruns=100)
同様の手順を Torchscript JIT モジュールで繰り返します。
traced_model = torch.jit.trace(model, torch.randn((1,3,224,224)).to("cuda"))
torch.jit.save(traced_model, "efficientnet_b0_traced.jit.pt")
benchmark(traced_model, input_shape=(1, 3, 224, 224), nruns=100)
PyTorch と Torchscript JIT が計測された平均スループットは著者の環境では Torchscript JIT の方が高い値でした。
Torch-TensorRT を用いた推論
Torch – TensorRT を使用してモデルをコンパイルし、混合精度で次のコマンドを実行します。
trt_model = torch_tensorrt.compile(model,
inputs= [torch_tensorrt.Input((1, 3, 224, 224))],
enabled_precisions= {torch_tensorrt.dtype.half} # Run with FP16
)
最後に、この Torch-TensorRT 最適化モデルのベンチマーク関數を実行します。
benchmark(trt_model, input_shape=(1, 3, 224, 224), nruns=100, dtype="fp16")
ベンチマーク結果
以下は、私が NVIDIA A 100 GPU でバッチ サイズ 1 で達成した結果です。
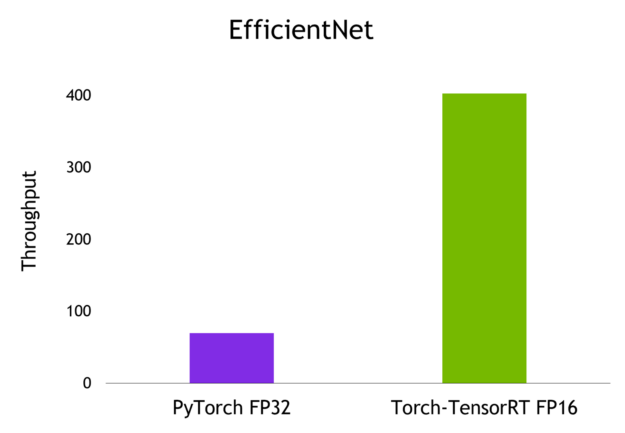
概要
最適化のための 1 行のコードで、Torch-TensorRT は最高 6 倍までのモデル性能を加速します。それは、PyTorch の容易さと柔軟性を維持したまま、NVIDIA GPU で最高のパフォーマンスを保証します。
あなたのモデルで試してみたいですか? PyTorch NGC コンテナーから Torch-TensorRT をダウンロードして、 TensorRT の最適化で PyTorch 推論を加速でき、コードの変更もほとんど必要ありません。
翻訳に関する免責事項
この記事は、「Accelerating Inference Up to 6x Faster in PyTorch with Torch-TensorRT」の抄訳で、お客様の利便性のために機械翻訳によって翻訳されたものです。NVIDIA では、翻訳の正確さを期すために注意を払っておりますが、翻訳の正確性については保証いたしません。翻訳された記事の內容の正確性に関して疑問が生じた場合は、原典である英語の記事を參照してください。