
AI、ML、HPC アプリケーションで CPU からより高速な GPU に計算処理が移行する中、GPU の IO (入出力) がアプリケーションの全體的パフォーマンスにおいて大きなボトルネックになりえます。
NVIDIA は Magnum IO GPUDirect Storage (GDS) を開発してストレージと GPU メモリの間のデータ移動を合理化し、CPU メモリのバッファーを経由してデータが格納され、転送されるといった、このプラットフォームのパフォーマンス ボトルネックを除去しました。
GDS は帯域幅を増やし、遅延を削減し、CPU の負荷を下げます。それを可能にするのが、ローカル NVMe ストレージまたは NIC の背後にあるリモート ストレージと GPU メモリ間の DMA (直接メモリ アクセス) です。DGX プラットフォームでは GDS によってディープラーニング推論、データ解析視覚化、ビデオ解析でそれぞれ、2.5 倍、8 倍、9 倍のパフォーマンス アップが観測されています。

幅広いプラットフォームに展開された、數多くのアプリケーションやフレームワークを高速化するには、多くのパートナーシップが必要です。NVIDIA の目的は、約 180 のソフトウェア/ハードウェア ベンダーと 2500 を超える貢獻者で構成される豊富なデータ ストレージ エコシステム全體を活性化することです。詳しくは、SNIA Web サイトをご覧ください。
この投稿では、パートナーシップからなる GDS エコシステムについて概説し、NVIDIA パートナーから寄せられた最近の成果を紹介します。
GDS エコシステム
NVIDIA は、ベンダー、フレームワーク開発者、エンド カスタマーとのパートナーシップが増え続けるオープン エコシステムを目指しています。GPUDirect Storage の 1.0 製品発売以降、パートナー ベンダーのエコシステムが表 1 に示すように成長しています。
各カテゴリ內の項目は時系列に並んでいます。まだリリースされていない項目と開発中のアイテムは斜體になっています。黃色で強調表示されている項目には、このシリーズで公開された前回の GDS 投稿以降の新しいデータが含まれています。
| ベンダー パートナー | フレームワークとアプリケーション | システム ソフトウェア |
| ファイル システム – DDN EXAScaler – Weka FS – VAST NFSoRDMA – MLNX_OFED の NVMe または NVMoF ドライバー経由の EXT4 – IBM Spectrum Scale (GPFS) – DELL Technologies PowerScale – NetApp/SFW/BeeGFS – NetApp/NFS – HPE Cray ClusterStor Lustre ブロック システム – Excelero – ScaleFlux スマート ストレージ | ストレージ – HDF5 – ADIOS – OMPIO ディープラーニング – PyTorch – MXNet データ分析 – cuDF – DALI – Spark – cuSIM/Clara – NVTabular データベース – PostgreSQL 高速化のための HeteroDB ビジュアライゼーション – IndeX | – Ubuntu 18.04 – Ubuntu 20.04 – RHEL 8.3 – RHEL 8.4 – DGX BaseOS 互換モードのみ: – Debian 10 – RHEL7.9 – CentOS 7.9 – Ubuntu 18.04 (デスクトップ) – Ubuntu 20.04 (デスクトップ) – SLES 15.2 – OpenSUSE 15.2 |
| リポジトリへの貢獻 | システム ベンダー | メディア ベンダー |
| リーダー – シリアル HDF5 – IOR コンテナー – PyTorch/DALI サンプル – トランスペアレント スレッディング – バッファー非依存 | – Dell – Hitachi – HPE – IBM – Liqid – Pavilion | – Kioxia – Micron – Samsung – Western Digital |
ベンダー パートナー
様々なベンダー パートナーが GDS エコシステムに參畫しており、それらのサービスには一般提供済みのものと、開発中のものがあります。ベンダー パートナーは 2 つのカテゴリに分類されます。GDS ソフトウェア イネーブルメントに直接関わるパートナーと、システム ソリューションとコンポーネント ソリューションを提供するパートナーです。
GDS イネーブルメント パートナー (一般提供中)
このセクションでは、所有するソフトウェア スタックに NVIDIA GPUDirect Storage を積極的に組み込み、機能性とパフォーマンスの NVIDIA 基本條件を満たし、一般提供されている運用ソリューションに統合しているパートナーを取り上げます。

- DDN は、Lustre ベースの EXAScaler 並列ファイル システムに GDS を統合しました。コミュニティと協力し、オープンソース ディストリビューションに GDS イネーブルメントをアップストリームしています。
- Dell Power Scale は NFS の最適化された実裝です。
- IBM Spectrum Scale (舊稱 GPFS) は、HPC、データ、AI で広く使用されている分散並列ファイル システムです。
- VAST 並列分散ファイル システムは、マルチパス処理を使用して NFS over RDMA (NFSoRDMA) を提供するシステムの先駆けとなりました。VAST は nconnect の NFSoRDMA の GDS も將來的にアップストリーム バージョンで利用できるようにしました。
- Weka は獨自の Weka FS 並列分散ファイル システムに GDS を統合しました。
ソリューションおよびコンポーネント プロバイダー (一般提供中)
GDS を一般提供レベルでサポートしているベンダーもあります。GDS を有効にするためにコードを変更するソフトウェア ソリューションを提供しているベンダーもあれば、GDS 導入の土臺となるコンポーネントまたはシステムを提供しているベンダーもあります。
ハードウェアまたは GDS の特性付けデータを提供するベンダー
NVIDIA、NPN、GPUDirect Storage パートナーは緊密に連攜し、GDS の全機能を評価しています。また、ハードウェア ソリューション、ソフトウェア ソリューション、NVIDIA の最高の GPU 高速化テクノロジを組み合わせ、測定されたパフォーマンス アップを數量化しています。これには次が含まれます。
MLNX_OFED で利用できるものなど、他の GDS 対応ソリューションを利用して完全なエンドツーエンド ソリューションを提供するシステム ベンダー パートナーには、次のパートナーが含まれています。

- DDN
- Dell Technologies
- Hewlett Packard Enterprise
- IBM
- Pavilion
- VAST
NVIDIA が最も緊密に連攜してきたコンポーネント ベンダーには、次のパートナーが含まれています。

- Kioxia
- Micron
- Samsun
- ScaleFlux
関心を示しているベンダー
GDS に強い関心を示しているその他のベンダーには、次のベンダーが含まれています。
- 日立製作所
- Liqid
- Western Digital
GDS イネーブルメント パートナー (開発中)
評価に利用できるサービスを提供しているが、一般提供向けには至っていないパートナー:

- BeeGFS 並列分散ファイル システムは HPC で一般的に使用されています。System Fabric Works は、NetApp と連攜して BeeGFS の GDS イネーブルメントに取り組んでいます。
- Excelero NVMesh は、あらゆるネットワークの NVMe ドライブを、あらゆるローカルまたは分散式のファイル システムをサポートする、エンタープライズ級の保護された共有ストレージに変換します。
- HPE は、Cray ClusterStor E1000 Storage System に使用されている、GDS 対応の Lustre 並列分散ファイル システム コードのアップストリームに貢獻しました。
- NetApp は現在、サーバー側の NFSoRDMA イネーブルメントに取り組んでいます。クライアント側での他の GDS の NFS イネーブルメントを活用できます。
GDS ベンダーパートナーによる検証データ
NVIDIA からの前回の GDS 投稿以降、新しいデータによる進展がいくつかありました。この投稿では、これらのサンプルを GPUDirect Storage の利點と一般性を実証するポイントとして紹介しています。
構成
GDS は、NVIDIA の DGX システムであれ、サードパーティの OEM プラットフォームであれ、さまざまなプラットフォームで CPU バウンス バッファーをスキップできるという點で優れています。「Accelerating IO in the Modern Data Center: Magnum IO Storage」という前回の投稿で指摘したように、NIC – PCIe スイッチ – GPU という経路が CPU を経由することなく利用できれば、GDS から利用できるピーク帯域幅は理論上、2 倍になります。ただし、実際の性能向上幅はもっと大きくなる可能性があります。
DGX 內では、一部の NIC スロットのデータ パスは CPU を通り越す必要があります。他のパスの場合、CPU をバイパスする NIC – PCIe スイッチ – GPU の直接パスが利用できます。図 2 は DGX A100 の背面のラベル付き畫像です。
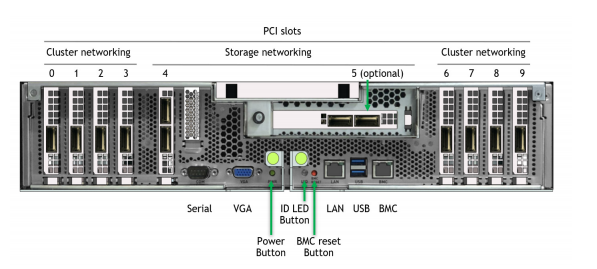
DGX A100 でストレージ パフォーマンスを評価できる構成が 2 つあります。承認されている標準構成では、NIC が「南北」に 2 つと「東西」に 8 つとなります。「南北」とは、「データ センターの端に向かう」という意味であり、ユーザー管理プレーンと外部ストレージ プレーンに接続されるスロット 4 と 5 に置かれます。「東西」とは「クラスター內」という意味であり、ノード間計算プレーンに接続されるスロット 0-3 と 6-9 に置かれます。
NVIDIA では、高帯域ストレージに 8 枚の「東西」 NIC を利用してアクセスできるようにすることを目指しており、それが可能になると、計算とストレージ プレーンが一點に集まります。QoS 評価の完了は保留になっています。現段階では、これを実験的構成と呼んでいます。
以前に公開されたパートナー データ
最初の GDS 投稿以降、NVIDIA は他のベンダー データを一般公開しています。これには、DDN EXAScaler、Pavilion NFSoRDMA、VAST NFSoRDMA、Weka FS の數値が含まれています。DGX A100 の実験的な 8-NIC 構成を使用することで、GDS で 152 から 178 GiB (186 GB/s) の範囲の帯域幅がベンダーから提供されることを確認しています。GDS がなければ、40-103 GiB/s の範囲の帯域幅が報告されています。
今後、NVIDIA は 8-NIC 構成を含む DGX システムのパフォーマンスデータを報告するパートナーには、南北の 2 NIC によるデータも含めるよう要請しています。このデータはまだすべて揃っていないため、今回は提示しません。NVIDIA の方針として、ベンダー パートナー間でパフォーマンスを直接比較することはありません。
イーサネットの VAST Data
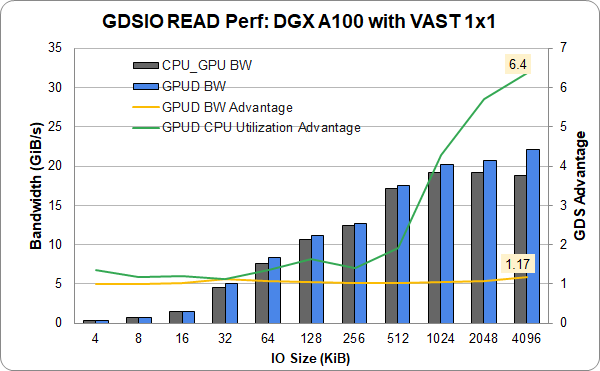
VAST Data Universal Storage は以前、InfiniBand で報告されていました。この會社は、InfiniBand の代わりに Ethernet を使用した VAST エントリレベル 1×1 構成の DGX A100 でシングル (スロット 4) NIC と 1 GPU による新しい結果を提供しました。イーサネットは、完全な機能性と同等のパフォーマンスを示しています。1 つのリンクで 22 GiB/s を超え、最大限のパフォーマンスに近づいています。これは、InfiniBand に加えてイーサネットにも同様に GDS を適用できることを示しています。
IBM Spectrum Scale
IBM Spectrum Scale (舊稱 GPFS) は、同社の GA 製品に最近追加されました。その構成では、IBM Spectrum Scale 5.1.1 を実行する 1 つの ESS 3200 ストレージ ファイラーで 71 GiB/s (77 GB/s) を達成しました。
ストレージと 2 臺の DGX A100 は、NIC スロット 4 と 5 にある総計 4 枚の HDR InfiniBand NIC で接続され、IO サイズは 1MB でした。通常そうであるように、絶対的なパフォーマンスは使用されるスレッドの數に応じて上昇します (図 4)。GDS ありと GDS なしでは、スレッドの數を変えても、相対的に同じくらいの改善が見られます。もっとも、スレッドの數が少ないほうが速くなります。
GDS の有無による相対的な性能差は、スレッド數を変えても安定していますが、スレッドが少ない方が良い結果が得られています。
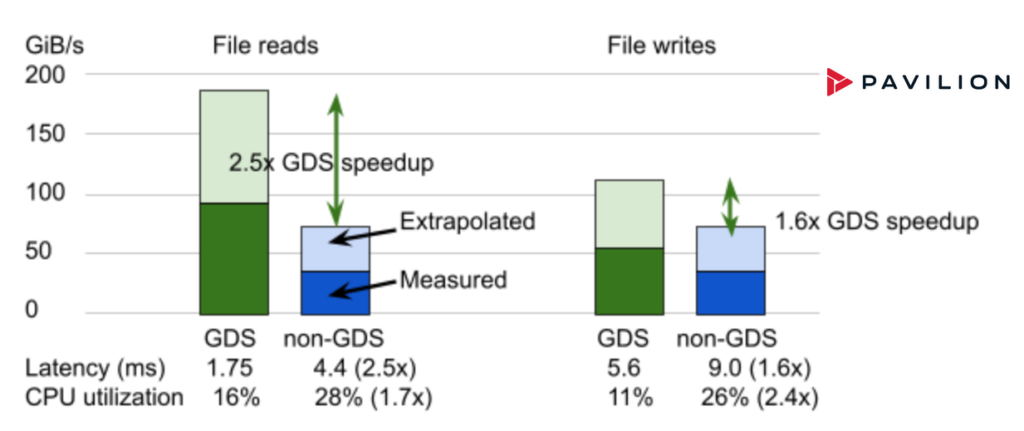
Pavilion
Pavilion は、分散並列ファイル システム、ブロック、オブジェクト インターフェイスを提供するストレージ ソリューションで、NFS over RDMA での GDS を実現します。Pavilion Data は、4U サイズのストレージ ノードを提供しています。 このストレージを 2 ノードで、2 NIC 構成の DGX A100 を 4 臺、あるいは 8 NIC 構成の DGX A100 を 1 臺飽和させるだけの帯域幅を提供します。図 5 の結果は実験的な 8 NIC 構成と、Pavilion のソフトウェアのバージョン 2 によるものです。
Liqid
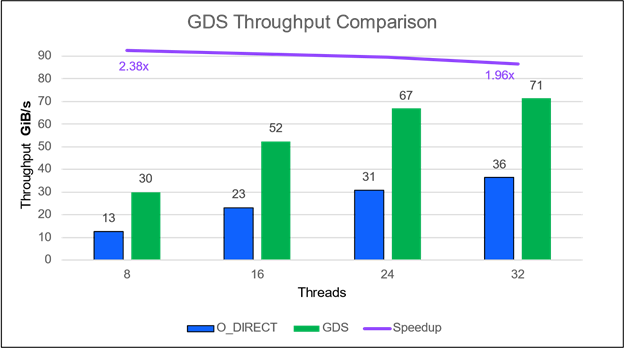
Liqid のシステムで最近測定されたパフォーマンスは、PCIe ベースの P2P パスがイーサネット/InfiniBand 経由の NVMe-oF より高速であることを示しています。GDS と統合された GPU と SSD 間の P2P 通信は最大 2900K IOPS を達成し、スループットが 16 倍に向上します。レイテンシは、GDS 以外のパスと比較して 712 us から 112 us に 1.86 倍改善されます (図 6)。
GPU から SSD へ、 P2P 無効
IOPS レイテンシ: 712 us
GPU から SSD へ、P2P 有効、GDS
IOPS レイテンシ: 112 us
データは 3 つの異なる構成で収集されました。
- 構成 #1: GPU-to-NVMe。Liqid ファブリックを使用し、同じ PCIe ファブリック上のすべてのデバイスを接続します。
- 構成 #2: GPU-to-CPU-to-NVMe。各 GPU ドライブと NVMe ドライブを CPU マザーボードに直接接続します。
- 構成 #3: GPU-to-NIC-NIC-NVMe-oF。GPU を NVMe-oF (CX-5) に使用し、ネットワーク経由でリモート NVMe にアクセスします。
構成の詳細は次のとおりです。
- マザーボード: AsROCK Rack ROME8D-2T、AMD Epyc 7702p、512GB DDR4 2933
- システム ソフトウェア: Ubuntu Server 20.04.2、NVIDIA ドライバー バージョン 470.63.01、CUDA 11.4
- Phison E16 800GB、Gen4 PCIe、Liqid v3.0 を実行する 24 Port Management Switch (TORs)、24 Port Gen4 Data Switch (Astek) を備えた Liqid QD4500
- NVIDIA A100 40GB と PCIe Gen4、LQS4500 と同じ PCIe スイッチ上に
- BIOS は ACS = Off に設定、Liqid で P2P を有効に。
図 6. GPU と SSD (または NVMe ドライブ) 間のピアツーピア (P2P) 通信では、GPUDirect Storage で IOPS が桁違いに改善されます。Liqid Matrix 拡張シャーシの GPUDirect Storage は、GPU と SSD 間の P2P 直接通信を可能にし、IOPS を最大 1620% スピードアップし、レイテンシを 86% 改善します。
InfiniBand とイーサネット
Infiniband は従來の HPC システムで人気ですが、イーサネットはエンタープライズ データ センターで大きな存在感を示しています。GDS はイーサネットと IB の両方でごく普通に動作します。主な要件は、基礎となるシステムとリモート ファイラーで RDMA がサポートされていることです。これは RoCE で可能になります。 それでは、2 つの違いは何でしょうか。最初の調査の結果は次のようになります。ネットワークのスケールによるストレージ アクセスを徹底的に分析することはこの投稿の範囲外ですが、ネットワークをデータに基づいて設計したい方にはお勧めです。
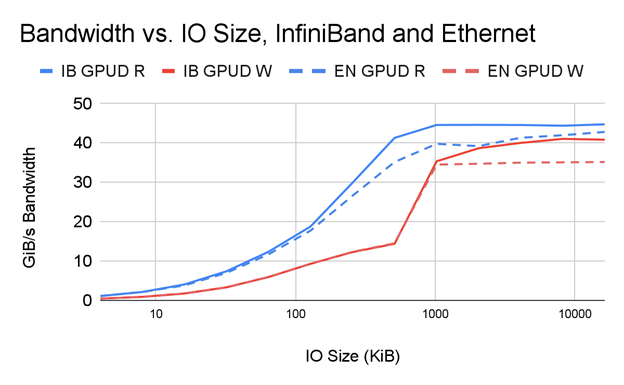
図 7 は、次の條件の下で IO サイズの関數として帯域幅を並べて比較した結果を示しています。
- 1 つの PCIe ツリーの 2 つの NIC が InfiniBand を利用して 1 つの DDN AI400x ファイラーに接続されます。
- 1 つの PCIe ツリーの 2 つの NIC がイーサネットを利用して同じ DDN AI400x ファイラーに接続されます。
ご覧のとおり、明らかに GPUDirect RDMA を基盤に開発されている GDS では、パフォーマンスは IB と Ethernet は比較に値します。IB はイーサネットに比べて最大 1.17 倍パフォーマンスがアップします。IO サイズが大きく、パフォーマンスが最高になり、ネットワーク速度が最も差別化されるときに特にアップします。
コミュニティ版 Lustre
コミュニティ版の Lustre にはさまざまなベンダーが獨自の価値を付加しています。しかしながら、OSS コミュニティ版の Lustre を使用しているお客様もいます。そのようなお客様も非専売のソリューションで GDS の長所を活用しているでしょうか。その答えはイエスです。
GDS で得られる帯域幅、レイテンシ、CPU 利用率のアップは、GDS なしと比較したとき、他の GDS 有効実裝のそれとすべて同様になります。リリース別バージョンのバージョン 2.15 をダウンロードできます。今すぐお試しください。
様々な組み合わせ
NVIDIA には、ForMIO (For Magnum IO) という実験的なクラスターがあります。Magnum IO (MIO) に関連するさまざまなテクノロジの評価および調査目的で使用されているため、この名稱になっています。DDN と Pavilion からは、ファイラー向け機材の使用許可をいただいております。メディア ベンダーの Kioxia、Micron、Samsung からは、こうしたファイラーの一部にデータを入力するドライブを提供していただけました。これは GDS を利用した DL フレームワークとカスタマー アプリケーションの評価を加速するため、うれしく思っています。
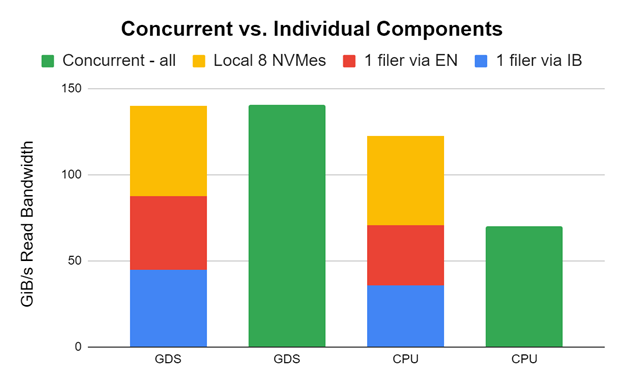
とんでもないものを試してみましたが、うまくいきました。1 つの DDN AI400x (InfiniBand、2 つの HDR200 NIC)、1 つの DDN AI400s (イーサネット、2 つの HDR200 NIC)、8 つのローカル NVMe を 1 つの DGX A100 に接続しました。全體で GDSIO パフォーマンス評価ツールを使用して評価しました。
図 8 の初期の結果と調整されていない結果は、ストレージ帯域幅を全體で組み合わせ、アプリケーションに帯域幅を供給できることを示しています。実際には必ずしもこれをお勧めしませんが、可能であることを知っておいて損はありません。これを可能にしてくれた DDN に感謝です。
1 つの DDN AI400x (InfiniBand、2 つの HDR200 NIC)、1 つの DDN AI400s (イーサネット、2 つの HDR200 NIC)、8 つのローカル NVMes のパフォーマンスをそれぞれ、1 つの DGX A100 で別々に (赤、青、黃)、そして同時に (緑) 測定しています。個々のコンポーネントが各ペアの左側に重ねられます。緑のバーは、すべて同時に実行されたときのパフォーマンスを示しています。
GDS の場合、GPU ターゲットは干渉しないように慎重に選択されているため、パフォーマンスは完全に一致します。CPU でバウンス バッファーを使用する GDS 以外の場合、CPU との間で輻輳が発生し、同時パフォーマンスが阻害されます。劇的な違いがあります。
まとめ
現在一般提供されている製品を基盤とする運用ソリューションを展開することをお勧めします。また、次世代のシステムには新しいソリューションを導入することを検討してください。GPUDirect Storage は現在 v1.0 が一般提供されています。GDS 対応サービスについては、GA ステータスに移行しているベンダー パートナーが増えています。また、ストレージ フレームワーク、ディープラーニング、地震探査、データ分析、データベースなど、さまざまな導入事例があります。
GDS のパートナーシップ
NVIDIA では、具體的なユース ケースを基づきベンダー パートナーや顧客と交渉することを推奨しています。ご興味がございましたら、NVIDIA チームまでお問い合わせください。GDS 対応の拡張エンドツーエンド ストレージ ソリューションを予定しておられましたら、お話をお聞かせください。GDS によるストレージ ドライバーのイネーブルメントの準備ができているベンダー パートナーには、次のリソースをお勧めします。
- エンド カスタマーと OEM の皆様は、「NVIDIA GPUDirect Storage Design Guide」をご覧ください。
- エンド カスタマー、OEM、パートナーの皆様は、「NVIDIA GPUDirect Storage Overview Guide」をご覧ください。
- GDS によるプログラミングについては、「cuFile API Reference Guide」を參照してください。
- ストレージ システムの GDS イネーブルメントとベンダー パートナー サポートについては、「NVIDIA GPUDirect Storage O_DIRECT Requirements Guide」を參照してください。
- 一般情報については、「NVIDIA GPUDirect Storage」を參照してください。
- 動畫による説明をお探しの場合、GTC 2020 セッションの「Accelerating Storage with Magnum IO and GPUDirect Storage」をご覧ください。
SC21 Birds of a Feature セッション「Accelerating Storage IO to GPUs」のアーカイブもぜひご覧ください。
GDS に貢獻する
ここで説明している GDS カーネルの nvidia-fs.ko はオープンソースです。MagnumIO/tree/main/gds GitHub リポジトリには、メインラインにチェックインされたコードや pull request として利用できるコードがあり、開発を開発するためとコミュニティ全體の活性化のためにコミュニティは貢獻を始めています。コミュニティに參加し、この領域の新しい開発を目撃してください。
謝辭
DELL Technologies、DDN、Excelero、IBM、Kioxia、Micron、Pavilion、Samsung、ScaleFlux、VAST、Weka には、評価のために機材を提供もしくは貸與していただいたこと、OEM プラットフォームにおけるパフォーマンスを特徴付けるデータやコンポーネントを提供いただいたことに感謝します。




