Stable diffusion は畫像生成、畫像編集、畫像変換など畫像における多様な処理ができるモデルです。高品質な畫像を生成できるのですが、仕組み上、推論に時間がかかってしまいます。そこで GPU での推論速度向上を行うために TensorRT を用いた Stable diffusion の高速化を試みました。著者の環境では約 7.68 倍程度の高速化が達成できました。
Stable diffusion について
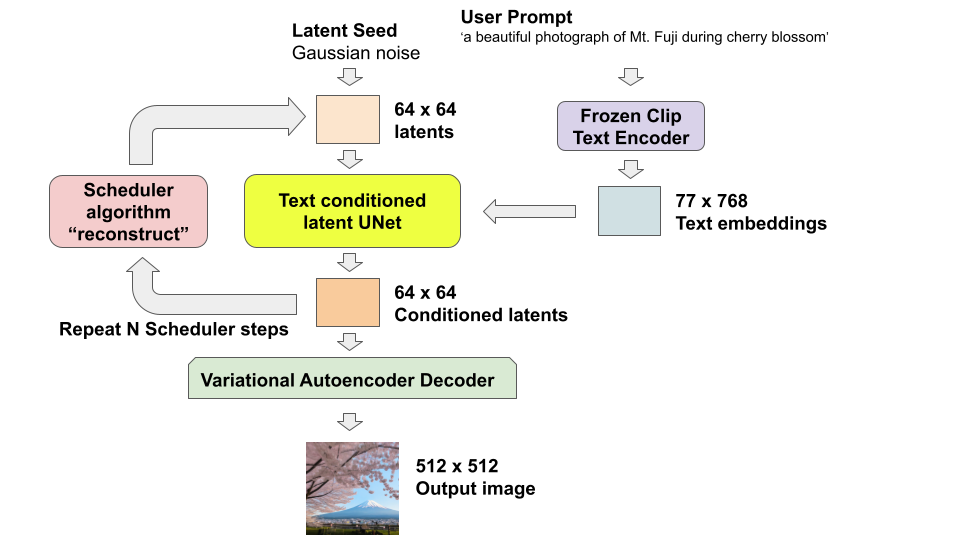
本稿では Hugging Face で提供されている Stable diffusion モデルを対象とします。Stable Diffusionではメモリ消費や計算リソース効率化の為に Latent Diffusion Model が採用されています。このモデルは RGB 畫像 (ピクセル空間) を潛在空間にマッピングしてから拡散処理を行うため、低次元空間で動作します。ピクセル空間拡散モデルと比較して、メモリと計算要件が大幅に削減されます。例えば、Stable Diffusion で使用される Variational Autoencoder Decoder は 8 分の 1 に縮小されます。 (3, 512, 512) の形狀の畫像が、潛在空間では (3, 64, 64) になり、ピクセル空間拡散モデルに比べて、潛在空間の利用による次元數の削減で 64 分の 1 にメモリ使用量が抑えられます。
モデル構成
Stable Diffusion with ?? Diffusers のブログを參照してモデルの構造を確認しました。
モデルは下記の 3 つの要素で構成されています。
- ユーザーのプロンプトを処理: CLIP Text Encoder
- ユーザーのプロンプトとノイズから埋め込みコードを生成: U-Net
- 埋め込みコードから畫像生成: Variational Autoencoder Decoder
大きくこの 3 つのモデルで構成されているため、TensorRT ではこれらを TensorRT Engine 化します。
TensorRT による高速化
TensorRT には下記のような機能があります。この機能を利用して GPU 上での推論性能を向上します。
- 混合精度: FP32、TF32、FP16、INT8?
- レイヤーとテンソルフュージョン: GPU メモリ帯域の利用を最適化?
- GPU カーネルのオートチューニング: ターゲット GPU に最適なアルゴリズムを選択?
- 動的なテンソルメモリ: メモリ効率の良いアプリを展開?
- マルチストリーム実行: 複數のストリームを処理するためのスケーラブルな設計?
さらに詳しい情報を知りたい方は Achieving World Leading Inference Performance Across Workloads をご參照ください。
Transformer モデルを高速化するための工夫
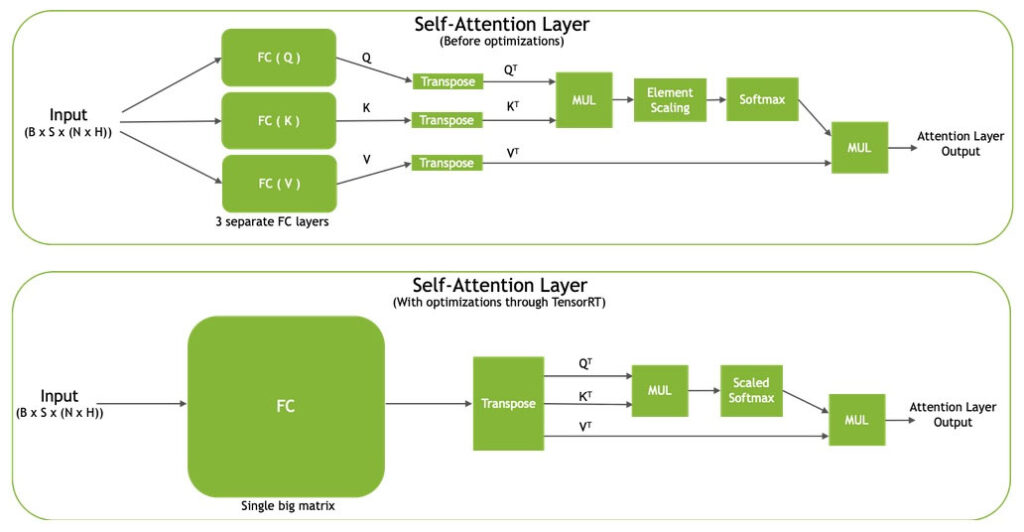
Transformer の Self Attention メカニズムは、全結合 (FC) 層を用いて、入力埋め込みに基づいてクエリー (Q)、キー (K)、バリュー (V) の表現を計算します。 これらの FC 層の入出力次元は B × S × (N × H) であり、B はバッチ サイズ、S はシーケンス長、N は Attention ヘッド數、 H は隠れ層サイズです。
FC 層を融合した後、3 つの転置演算を 1 つの大きな転置演算に融合することで、出力次元は 3 × B × N × S × H となります。FC 層を融合し、大きなテンソルに 1 つの転置演算を行うことで、Q、K、V の表現は、それらに続く演算のためにメモリ上に連続的に配置されます。 この結果、メモリ アクセスが高速化され、モデルのスループットが向上します。
また、要素ごとのスケーリング層とソフトマックス層を融合します。この処理によってメモリアクセス數を減らし、全體のパフォーマンスを向上できます。
図 2 は TensorRT で最適化される前 (図 2: 上) の Self Attention Layer と最適化後 (図 2: 下) のSelf Attention Layer を示しています。
Hugging Face のモデルでの検証
検証に使用したハードウェアとソフトウェアは下記になります。
- ハードウェア
- NVIDIA DGX A100 の GPU 1 枚使用
- ソフトウェア
- ngc の TensorRTコンテナー タグ 23.05-py3 を使用
- requirements.txt のライブラリ
TensorRT の Github に Huggingface のモデルを TensorRT で最適化するサンプル コードが公開されています。txt2img の jupyter notebook を使用して検証します。release-8.6 のバージョンのコードを使用しています。
今回紹介する txt2image 以外にも inpaint と img2img のコードもあるので興味がある方は試してみてください。
コードの一部を確認してみます。通常のモデルは下記の Pipeline で処理をしています。
pipe = StableDiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-2-1",
revision='fp16',
torch_dtype=torch.float16,
scheduler=scheduler,
image_height=512,
image_width=512)
TensorRT を使用する場合は custom_pipeline を使用するだけで良いので非常に簡単に変更できます。
pipe_trt = StableDiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-2-1",
custom_pipeline="stable_diffusion_tensorrt_txt2img",
revision='fp16',
torch_dtype=torch.float16,
scheduler=scheduler,
image_height=512,
image_width=512)
下記で cache 用のフォルダーを指定しています。これはモデルを ONNX に変換した後に TensorRT Engine に変換するのですが、その処理は時間がかかるため、キャシュとして保存することで変換処理を一度で済むようにするための工夫になります。
pipe_trt.set_cached_folder("stabilityai/stable-diffusion-2-1", revision='fp16')モデルの TensorRT による最適化は時間がかかります。著者の環境では下記の時間がそれぞれのモデルでかかりました。
- CLIP Text Encoder: 約 5 分
- U-Net: 約 41 分
- Variational Autoencoder Decoder: 約 16 分
最適化が終われば、それぞれのモデルの ONNX ファイルと TensorRT Engine 化された plan ファイルが確認できます。
最適化の手順
下記の手順で最適化をしています。
- ONNX グラフに変換
- ONNX-Graphsurgeon で不要なノードの統合や削除
- TensorRT による最適化
ONNX-Graphsurgeon
ONNX-Graphsurgeon は ONNX モデルの編集や不要なノードの除去などができるツールになります。ONNX-Graphsurgeon について更に詳しい情報を知りたい方は Prototyping and Debugging Deep Learning Inference Models Using TensorRT’s ONNX-Graphsurgeon and Polygraphy Tools をご確認下さい
最適化処理では ONNX グラフに変換に変換後に Folding constants の処理をしています。この処理は定數の処理はなるべく 1 つにまとめて演算する処理になります。
例えば x が入力として c0、c1、c2 が定數として下記のような処理があったとします。
x + (c0 + (c1 + c2))
この処理は下記のようにまとめることができます。
x + e
e = c0 + (c1 + c2)
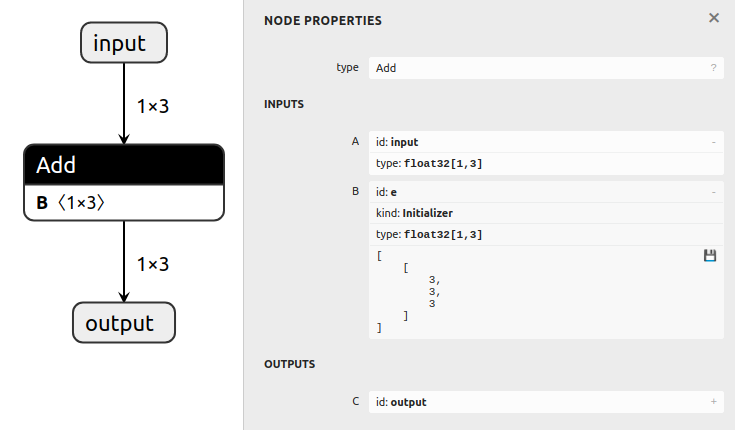
グラフで記述した例だと output = input + ((a + b) + d) の処理をするノードが下記の場合
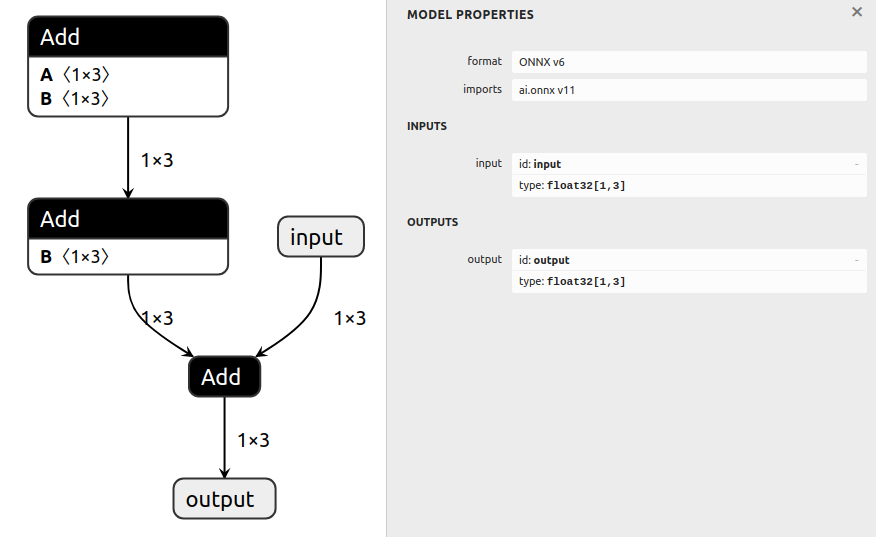
下記のように変換して処理できます。
output = input + e
e = ((a + b) + d)
HuggingFace Diffusers の下記のコードで ONNX-Graphsurgeon による最適化を行っています。
if force_engine_rebuild or not os.path.exists(onnx_opt_path):
logger.warning(f"Generating optimizing model: {onnx_opt_path}")
onnx_opt_graph = model_obj.optimize(onnx.load(onnx_path))
onnx.save(onnx_opt_graph, onnx_opt_path)
else:
logger.warning(f"Found cached optimized model: {onnx_opt_path} ")
TensorRT 最適化
TensorRT の最適化は Diffusers のこちらのコードで実行されています。Polygraphy の engine_from_network 関數を使用して最適化されており、TensorRT 化をする際のオプションは CreateConfig で指定されているため、オプションの変更、追加をする場合はこちらのコードを変更する必要があります。使用可能なオプションはこちらを參照してください。
性能検証
Prompt は ”a beautiful photograph of Mt. Fuji during cherry blossom” を使用しました。Hugging Face のモデルと TensorRT 変換後のモデルで生成した畫像は下記になります。TensorRT 変換後も同様な畫像が生成できています。

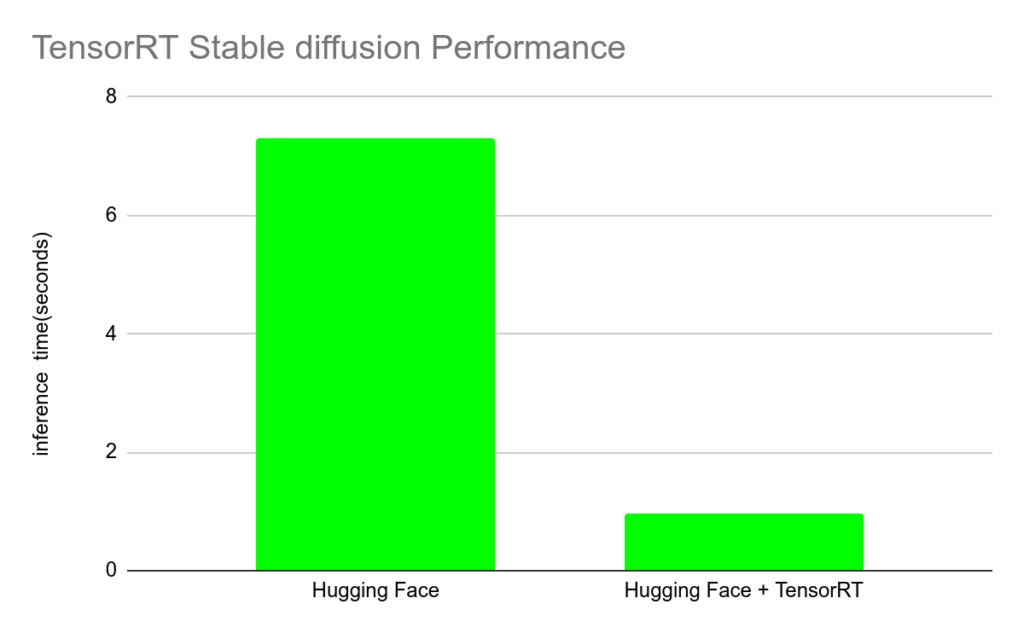
著者の環境では約 7.68 倍程度推論速度が 向上しました。ただし、チューニングを行っていないのでチューニングをすればもっと性能向上する可能性はあります。
検証條件
- 推論條件
- バッチサイズ: 1
- 畫像サイズ: 3 x 512 x 512
測定結果
- Hugging Face: 1 枚の畫像を生成する際の推論速度 7.3 second
- Hugging Face + TensorRT: 1 枚の畫像を生成する際の推論速度 0.95 second
まとめ
本稿では Hugging Face で取得できる Stable Diffusion モデルを TensorRT Engine へ変換してみました。生成モデルの推論を GPU 上で高速化したい場合、TensorRT は強力なツールになるので、是非活用していただけると幸いです。
関連情報
- TensorRT SDK | NVIDIA Developer
- TensorRT – Get Started | NVIDIA Developer
- 後編: TREx による TensorRT 化したStable Diffusion モデルの解析
參考
- Prototyping and Debugging Deep Learning Inference Models Using TensorRT’s ONNX-Graphsurgeon and Polygraphy Tools | NVIDIA On-Demand
- TensorRT/tools/onnx-graphsurgeon at master · NVIDIA/TensorRT · GitHub
- Rombach, Robin, et al. “High-resolution image synthesis with latent diffusion models.” Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022.