
コンピューティングの世界は劇的な転換期にあります。
コンピューティング性能、特にハイパフォーマンス コンピューティング (HPC) の需要は年々増加しており、それはまたエネルギー消費量も増加していることでもあります。しかし、根底にある問題は、エネルギーが制限のある資源であるということです。そのため世界は、演算の焦點を性能からエネルギー効率にどのようにシフトさせるのが最善か、という問題に直面しています。
この問題を考えるとき、タスクを完了させる速度とエネルギー消費の相関関係を考慮に入れることが重要です。この関係は見落とされがちですが、不可欠な要素です。
この記事では、スピードとエネルギー効率の関係を探り、より速くタスクを完了させる方向にシフトした場合の影響について考察します。
輸送の場合を例に取ってみましょう。
物體の運動の場合、真空以外の場所では、抗力は移動速度の 2 乗に比例します。つまり、ある距離を 2 倍の速さで進むには、4 倍の力とエネルギーが必要になります。私たちの地球上で人や物が移動するということは、空気か水 (どちらも物理學では「流體」です) の中を移動するということであり、この概念は、なぜ速く移動するにはより多くのエネルギーが必要なのかを説明するのに役立ちます。
輸送技術の多くは化石燃料を利用していますが、それは化石燃料のエネルギー密度とそれらを燃料として動作するエンジンの重量が、現在でさえも匹敵することが難しいからです。たとえば、原子力技術には、廃棄物、安全な運用に必要な専門的な人材、重量などの課題があり、原子力を動力とする自動車、バス、飛行機がすぐに実現するわけではありません。
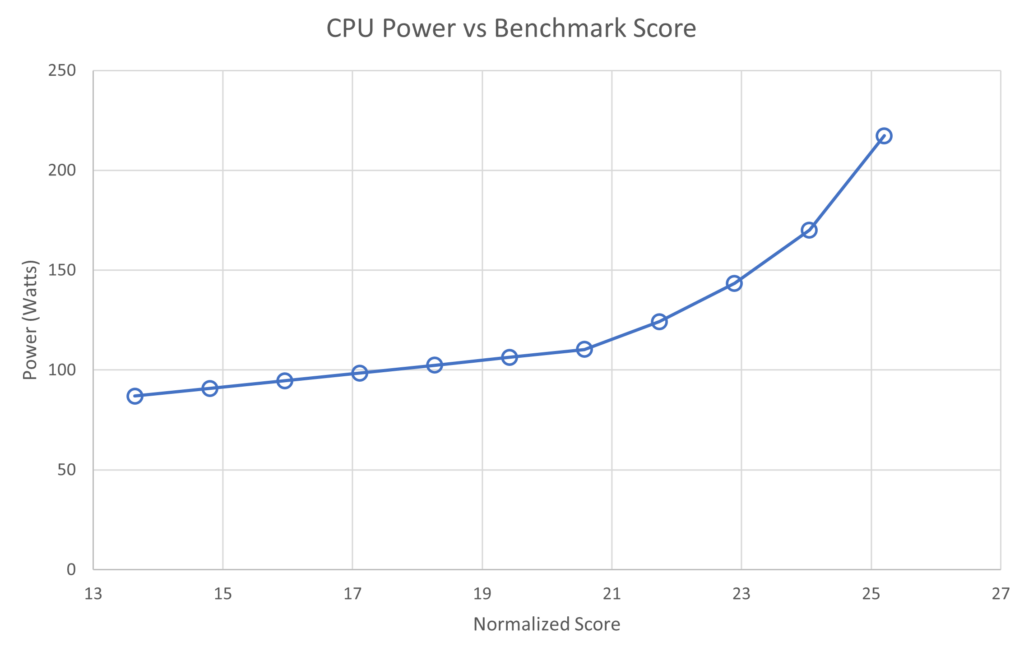
半導體プロセッサも速度との間で同じような関係にあります。前述のグラフは、整數の処理速度を上げることは、電力 (単位時間當たりのエネルギー) の増加とともに達成されることを示しています。つまり、輸送と同様、プロセッサが速くなればなるほど、より多くのエネルギーを使うことになります。
あなたは「なぜ現代のコンピューターは數十キロワットもの電力で動くことにならないのですか? それらは 50 年間高速化し続けています。」と思われるかもしれません。
その答えは、プロセッサの高速化に伴い、小型化も進んでいるためです。シリコンの機能を縮小することで、エネルギー効率が向上し、一定の電力で、より高いクロック速度でより高速に動作することができます。大まかに言えば、これはデナード則として知られています。
マルチノード並列コンピューティング
HPC における極めて重要な概念は、並列コンピューティングが、総計算時間を犠牲にして経過実行時間を短縮するという影響です。HPC アプリケーションに逐次計算がごく一部含まれているような場合 (詳しくない方のために説明すると、これはほとんどの場合に該當します)、より多くの計算リソースが追加されるにつれて、実行時間は漸近的に逐次計算の実行時間に近づきます。
これはアムダールの法則として知られています。
このことは、並列コンピューティングで消費されるエネルギーを考える上で重要です。コンピュート ユニットが計算を実行している間、同じ量の電力を消費すると仮定すると、計算タスクは、より大きなコンピュート リソースのセット間で並列化されるにつれて、より多くの電力を消費することになります。
つまり、計算タスクは、より大規模な計算リソースのセット間で並列化されるため、より多くの電力を消費することになります。同時に、タスクの実行時間も短くなります。この調査における仮説は、リソースの追加による実行時間の短縮のペースは、コンピュート リソースの増加による追加電力のペースほどにはならず、最終的にはより多くのエネルギーを消費するということです。
言い換えれば、冒頭で述べたように、速く走ろうとすればするほど、より多くのエネルギーを使うことになるのです。
エネルギー使用量の測定
NVIDIA DGX A100 をベースとした Selene システムを使用することで、エンジニアは Grafana を使用して集約された様々な指標を収集することができます。Grafana の API を使用することで、ユーザーは、ジョブ全體または與えられた時間枠のいずれかで、個々の CPU、GPU、および電源ユニットについて、時間の経過とともに電力使用量を照會することができます。
このデータをシミュレーション出力のタイムスタンプと共に使用することで、使用されたエネルギーが定量化されます。報告されているエネルギー消費の數値は、いくつかの要因を考慮していません:
- ネットワーク スイッチング インフラ (サーバー內蔵のネットワーク カードも含む)
- データの展開と結果収集のための共有ファイルシステム使用
- 電源における AC から DC への変換
- データ センター CRAC ユニットの冷卻エネルギー消費量
最も大きな誤差となるのは、空冷式データ センターの項目であり、データ センターの電力使用効率 (PUE: Power Usage Effectiveness) と密接に 一致します (空冷式では~ 1.4、液冷式では~ 1.15)。さらに、AC / DC 変換は、測定されたエネルギー消費量を 12% 増加させることで近似できます。しかし、この議論ではエネルギーの比較に重點を置くため、これらの誤差は両方とも無視します。
この記事の続きでは、電力にはワット (ジュール毎秒)、エネルギーにはキロワット時 (kWh) を使用します。
実験の設定
| ノードあたりのアクティブな NVIDIA Infiniband 接続 | ||||
| 1 | 2 | 4 | ||
| ノードあたりの GPU 數 | 1 | ? | ||
| 2 | ? | |||
| 4 | ? | ? | ? | |
GPU により高速化された世界中の HPC システムの構成、要件、および HPC シミュレーション アプリケーション全體における高速化技術の採用の段階はさまざまであるため、異なる構成の計算ノードを使用して並列シミュレーションを実行することが有用です。これにより、性能と効率がさらに最適化されます。
前述の表では、各アプリケーションの 5 つの異なるスケーリング方法を示しています。以下のプロットでは、読みやすくするために、一貫したビジュアル表現を使用しています。単一の NVIDIA InfiniBand 接続では、グレーまたは黒の點線を使用します。二重の Infiniband 接続は緑の実線を使用し、四重の Infiniband 接続はオレンジの破線を使用します。
HPC アプリケーションのパフォーマンスとエネルギー
このセクションでは、計算流體力學、分子動力學、気象シミュレーション、量子色力學などの分野を代表する主要な HPC アプリケーションに関するインサイトを提供します。
アプリケーションとデータセット
| アプリケーション | バージョン | データセット |
|---|---|---|
| FUN3D | 14.0-d03712b | WB.C-30M |
| GROMACS | 2023 | STMV (h-bond) |
| ICON | 2.6.5 | QUBICC 10 km resolution |
| LAMMPS | develop_7ac70ce | Tersoff (85M atoms) |
| MILC | gauge-action-quda_16a2d47119 | NERSC Large |
FUN3D
FUN3D は、非圧縮性フローから遷音速流領域までの非構造格子流體力學シミュレーションのアルゴリズムを研究し、新しい手法を開発するために、1980 年代に初めて記述されました。この 40 年の間にこのプロジェクトは、解析だけでなく、隨伴行列ベースの誤差推定、メッシュ適合、設計最適化をカバーするツール群へと成長しました。また、極超音速までの流れ領域も扱います。
現在、米國市民専用のコード、研究、學術、産業界すべてのユーザーが FUN3D を活用しています。例えば、Boeing、Lockheed、Cessna、New Piper などの企業が、高揚力、巡航性能、革命的コンセプトの研究などの用途に FUN3D を使用しています。
GROMACS
GROMACS は、數百から數百萬の粒子を持つ體系に対してニュートン運動方程式を用いる分子動力學パッケージです。GROMACS は、主にタンパク質、脂質、核酸のような、多くの複雑な結合相互作用を持つ生化學分子向けに設計されています。GROMACS は、非結合相互作用 (通常シミュレーションを支配する) の計算が非常に速く、多くのグループが非生物系 (例えばポリマー) の研究にも使用されています。
GROMACS は、最新の分子動力學実裝で一般的なアルゴリズムをすべてサポートしています。
ICON モデリング フレームワーク
ICON モデリング フレームワークは、ドイツ気象局 (DWD) とマックス プランク気象研究所 (Max-Planck-Institute for Meteorology) の共同プロジェクトで、統合された次世代グローバル數値気象予測 (NWP: Numerical Weather Prediction) と気候モデリング システムを開発するためのものです。ICON モデリング フレームワークは、2015 年 1 月に DWD の予報システムで運用を開始しました。
ICON は、厳密な局所質量保存と質量一貫輸送を必須要件とすることで、より優れた保存特性によって他の NWP ツールとは一線を畫しています。
気候が世界的な問題であることを認識し、將來の超並列 HPC アーキテクチャにおけるスケーラビリティの向上に努めています。
LAMMPS
LAMMPS は古典的な分子動力學コードです。その名の通り、並列マシン上でうまく動作するように設計されています。
その焦點は材料モデリングにあります。そのため、固體材料 (金屬、半導體)、ソフト マター (生體分子、ポリマー)、および粗視化またはメゾスコピック系の潛在的なモデルが含まれています。LAMMPS は、メッセージパッシング技術とシミュレーション領域の空間的分解を使用して並列性を実現しています。LAMMPS のモデルの多くには、CPU と GPU の両方で加速されたパフォーマンスを提供するバージョンがあります。
MILC
MILC は、量子色力學 (QCD: Quantum Chromodynamics) と呼ばれる素粒子物理學の強い相互作用の理論を研究する科學者によって使用され、維持されている共同プロジェクトです。MILC は 4 次元 SU(3) 格子ゲージ理論のシミュレーションを MIMD 並列マシンで実行します。MILC は研究目的で一般に公開されており、MILC またはこのコードの派生物を使用した研究の出版物では、この使用を認める必要があります。
並列スケーラビリティ
以下のプロットでは、標準的な方法で計算された無次元量 SPEEDUP (強いスケーリング) を示します:
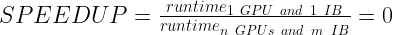
並列 SPEEDUP は、多くの場合 1 つの計算リソースを使用すると SPEEDUP 値は1、2 つのリソース ユニットを使用すると SPEEDUP 値は 2、といった具合で「理想的な 」SPEEDUP に対してプロットされます。ここでは、複數のスケーリング トレースが表示され、それぞれが理想的な SPEEDUP の參照を持っている場合、プロットがデータで非常に混雑するため、これは行われません。
各ノード スイープのノードあたりの GPU 數と有効な CX6 EDR Infiniband 接続數は、凡例に {# GPUs / node} – {# IB / node} で示されています。
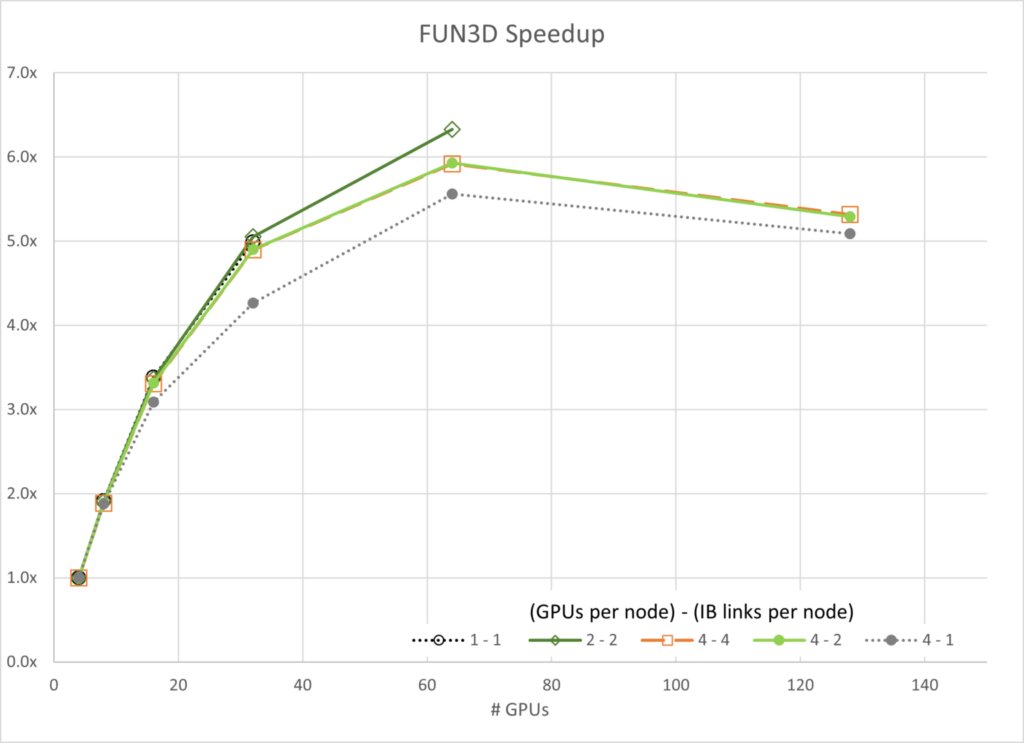
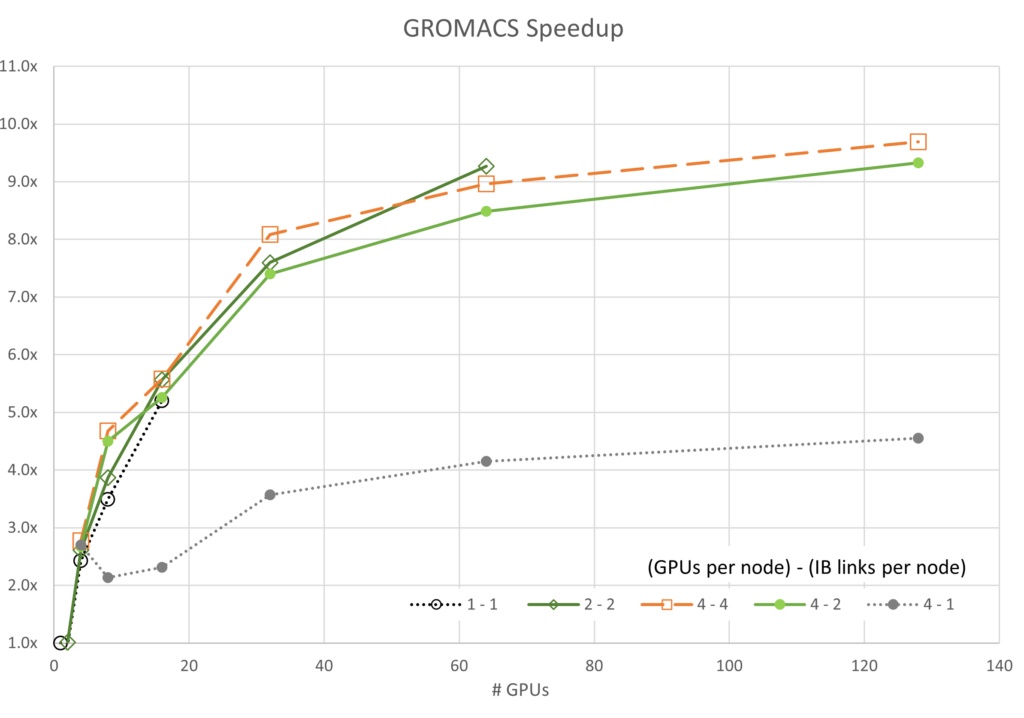
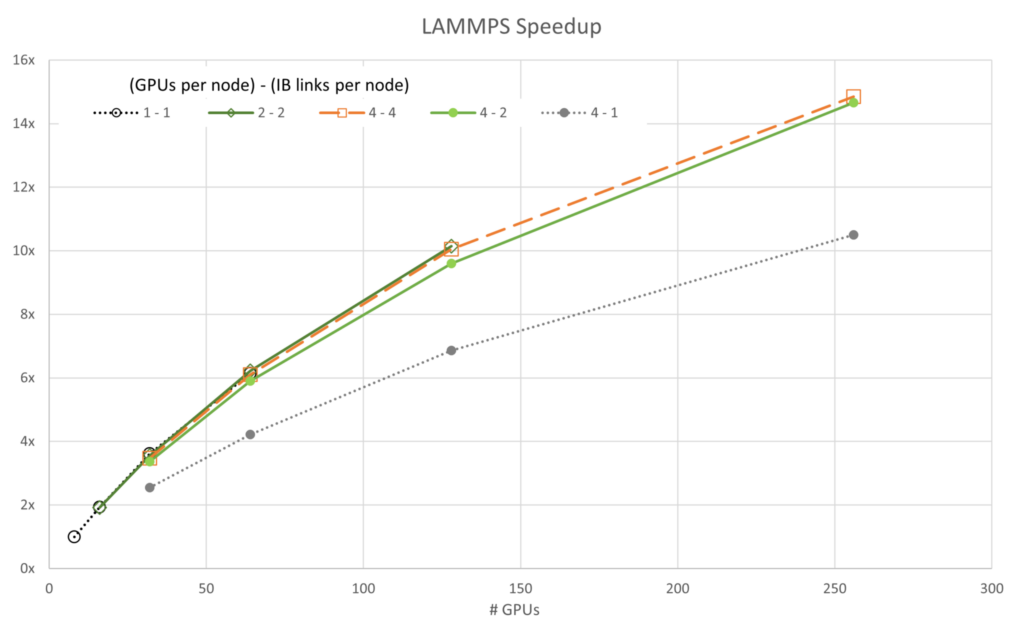
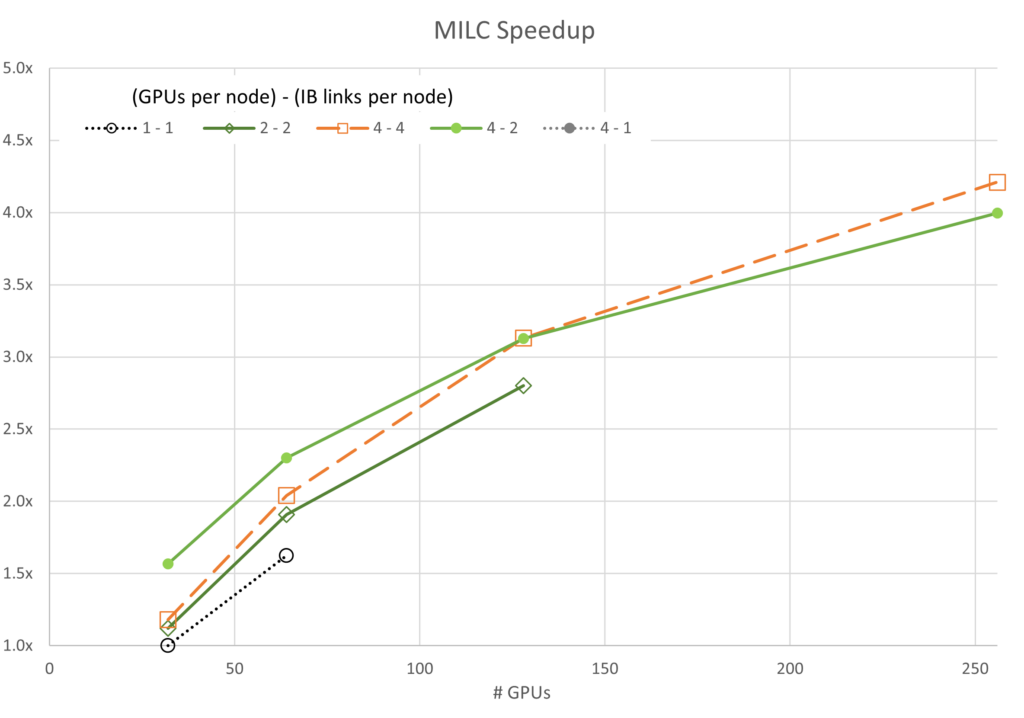
図 3 から 7 は、各シミュレーションのスケーラビリティを示しています。 一般に、ほとんどのデータはアムダールの法則に基づいて予想される傾向に従っています。 注目すべき例外は、4 基の GPU とノードあたり 1 つの InfiniBand 接続を使用した GROMACS 構成です (ラベル 4-1) この構成は、最初は負のスケーリングを示します。つまり、スケーリングを開始する前にリソースが追加されると速度が低下します。
ネットワーク構成を考えると、スケーリングはネットワークの帯域幅と各並列スレッドが通信しようとするデータによって制限されるようです。リソースの數が GPU 16 基から 32 基の間で増加するにつれて、タスクは帯域幅に縛られなくなり、わずかな範囲でスケーリングするポイントに達します。
ICON と LAMMPS では、4-1 構成で同様の異常値動作が見られますが、両者とも GROMACS よりはるかに容易にスケールします。
また、4-4 構成が常に最高のパフォーマンスを発揮するわけではないということも興味深いです。FUN3D (2-2) と MILC (4-2) の一部では、わずかな差で他の構成でのスケーリングが優れたパフォーマンスを示しますが、その他すべての場合において、4-4 構成が最良の構成です。
エネルギー使用量
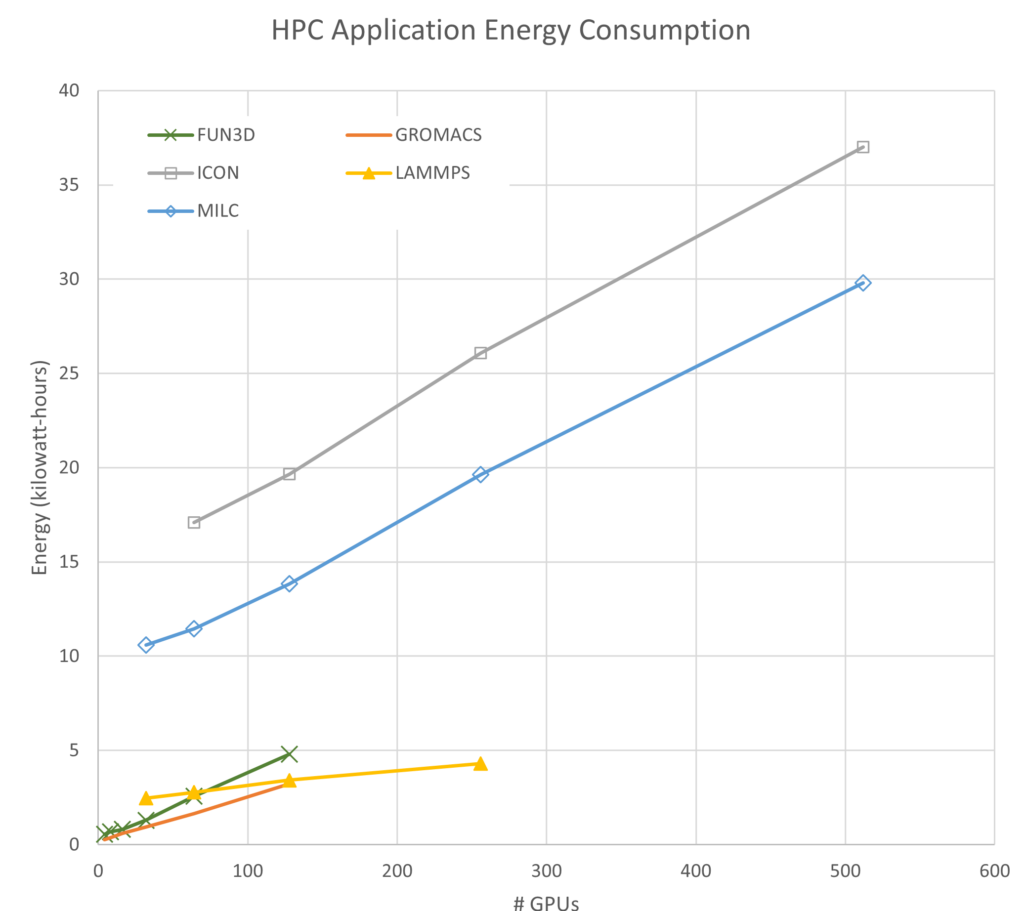
図 8 では、簡潔にするため、4 基の GPU と 4 つの Infiniband 接続 (4-4) のエネルギー消費量のみを 1 つのグラフで示しています。各シミュレーションで使用されるエネルギー量は任意のものであり、問題のサイズや解析タイプを変更することで上下に調整できます。注目すべき関連する特徴が 2 點あります:
- 各アプリケーションの勾配は正の値であり、これはスケールが大きくなるにつれて、より多くのエネルギーを使用することを意味する。
- FUN3D のように使用エネルギーが急速に増加するアプリケーションもあれば、LAMMPS のように徐々に増加するアプリケーションもある。
解決までの時間とエネルギーとの比較
図 8 から、これらのシミュレーションを実行するための最適な構成は、シミュレーションごとに使用されるリソースの數を最小化することであると結論付ける方もいるかもしれません。エネルギーの観點から見ればその結論は正しいですが、エネルギー以外にも考慮すべきことがあります。
例えば、プロジェクトの期限に追われている研究者の場合、解決までの時間は極めて重要です。また、営利企業の場合、製造プロセスを開始し、製品を市場に投入する準備を整えるために、最終データが必要になることがよくあります。このような場合にも、シミュレーション結果をより早く出すために必要な追加のエネルギーよりも、解決までの時間の価値の方が上回ることがあります。
したがって、これは定義された各目的の重要度により複數の解を持つ多目的最適化問題です。
理想的なケース
目的を探る前に、以下のような理想的なケースを検討してみましょう:
完全な並列 (直列演算がないことを意味する) 高速化された HPC アプリケーションは、プロセッサが追加されるにつれて線形にスケールします。グラフ的には、SPEEDUP 曲線は単純に (1,1) から始まり、1.0 の傾きで右上がりの直線になります。
ではこのようなアプリケーションについて、エネルギーについて考えてみましょう。追加されたすべてのプロセッサが同量の電力を消費する場合、実行中の消費電力は以下の式となります:
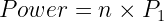
この場合、 は使用されるプロセッサの數、
は 1 基の GPU によって使用される電力です。
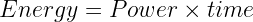
ただし、時間は の逆関數なので、次のように書き換えることができます。
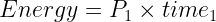
値は相殺され、理想的な場合、
は GPU の數の関數ではなく、実際には一定であることがわかります。
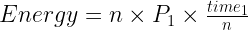
いくつかのケースでは、HPC アプリケーションは、並列高速化においてもエネルギーにおいても理想的ではありません。高速化はリソースを追加するにつれて収穫が逓減するケースであり、一方エネルギーはリソースを追加するにつれてほぼ直線的に増加するため、高速化とエネルギーの比が最大となる GPU の數が存在するはずです。
より形式的に、エネルギーと時間の重みが等しいと仮定します:
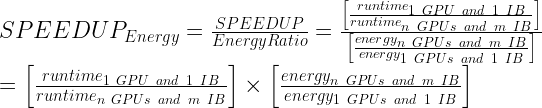
この式において、以下は一定であるとします:
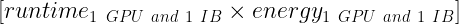
以下を最大化する必要があります:
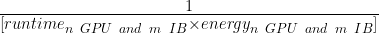
あるいは、以下を最小限に抑える必要があります:
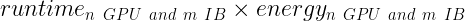
一方の軸に実行時間を、対する軸にエネルギーをプロットした場合、最小化すべき量は単純に実行時間にエネルギーを掛けた面積となります。
このように問題を定義することで、並列実行で使用されるリソース數、GPU クロック周波數、ネットワークの遅延、帯域幅、および実行時間とエネルギー使用量に影響するその他の変數など、これらに限定されない複數の獨立変數の調査も可能になります。
スピードとエネルギーのバランス
以下のグラフは、実行時間とエネルギー消費の積であり、獨立変數は並列実行する GPU 數です。これらのグラフは、実行時間とエネルギーの最適化のための解のパレート フロントの中から 1 つの解を決定する 1 つの方法を提供します。
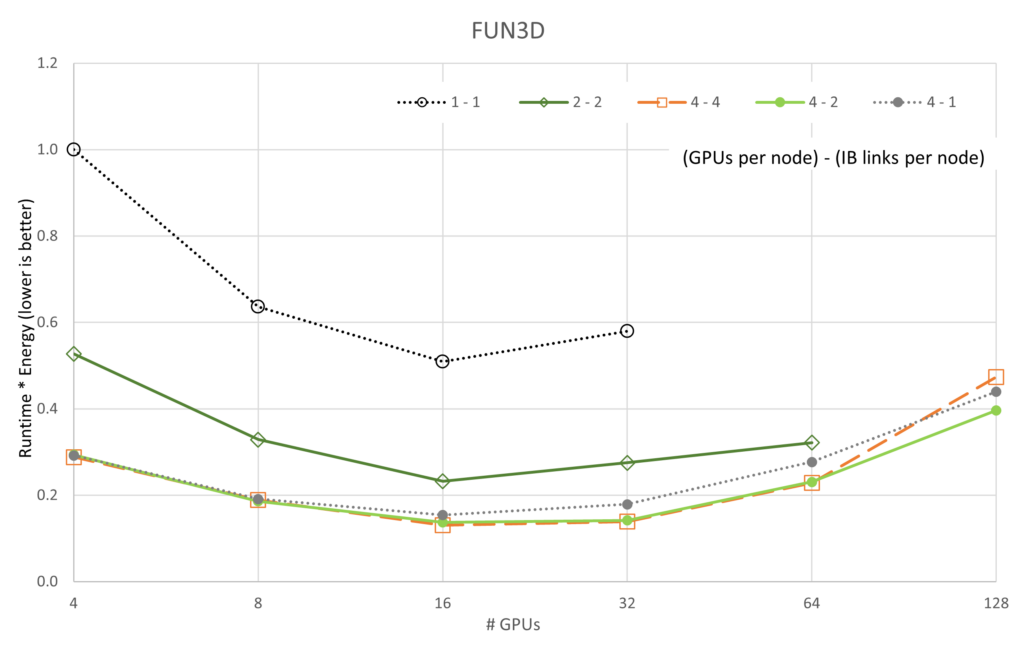
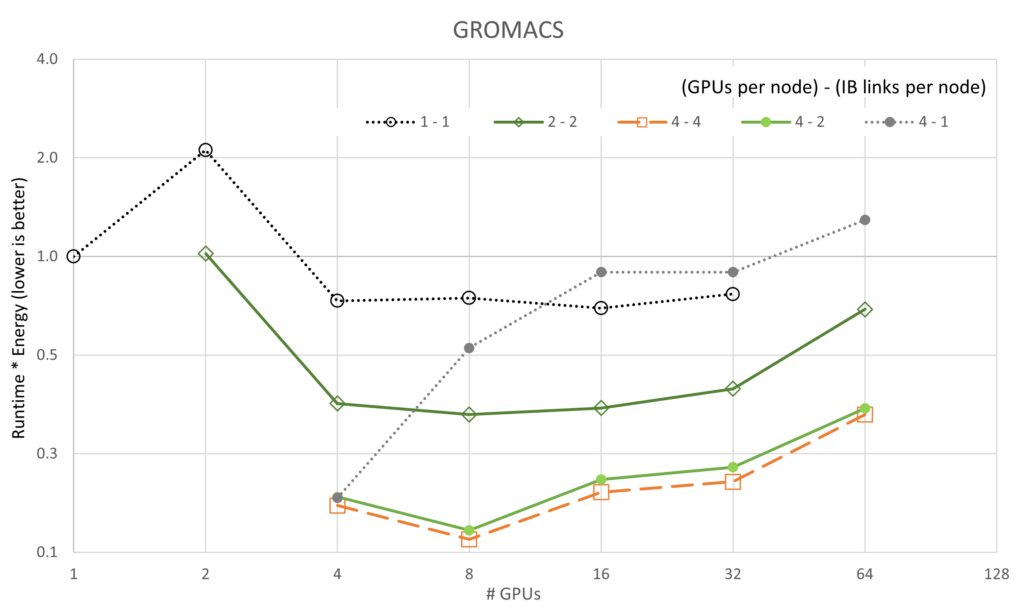
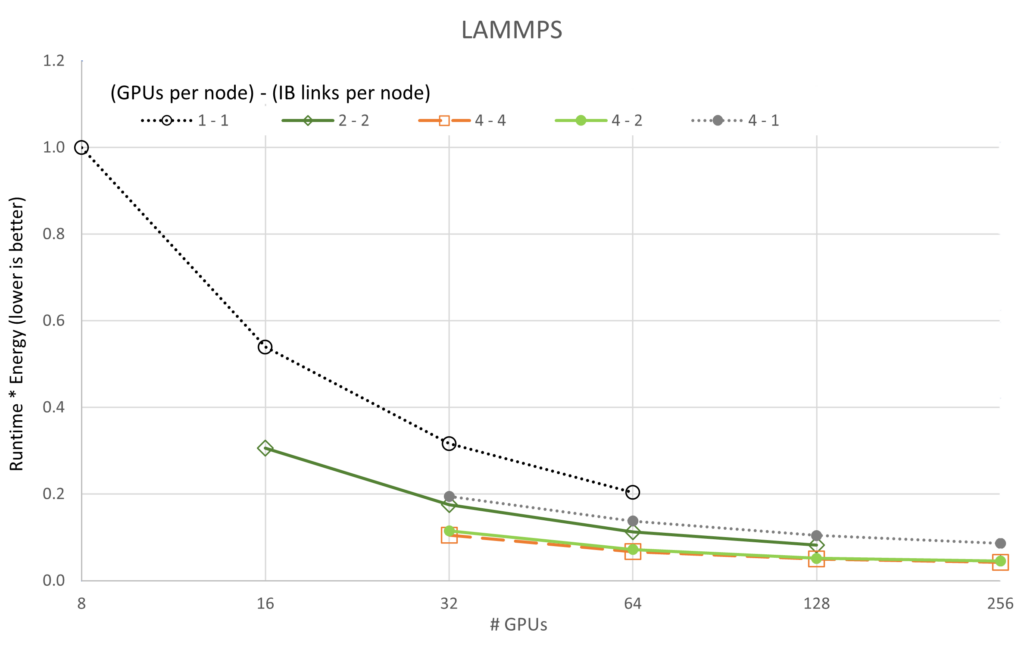
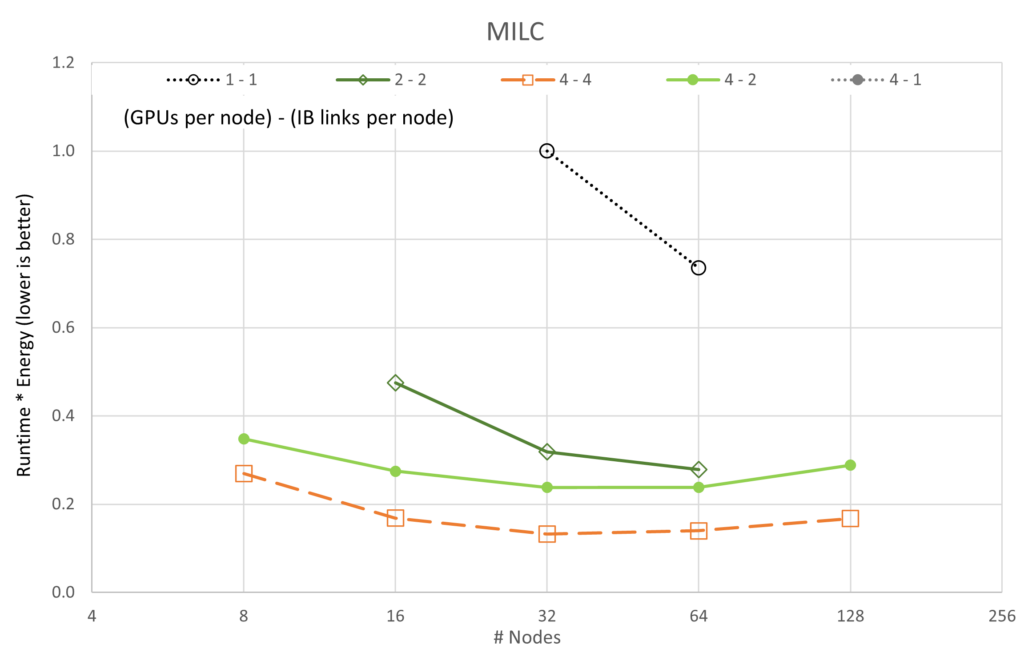
前述の図は、5 つのアプリケーションと 5 基の GPU/ネットワーク構成のそれぞれを GPU 數でスケーリングしたときの実行時間 * エネルギーの変化を示しています。性能のスケーラビリティのグラフとは異なり、すべてのケースで 4-4 構成 (「4-4」は {# GPUs / node} – {# IB / node} を意味します) が最良で、4-2 構成が僅差で 2 位であることがわかります。スケーラビリティのグラフと一致するように、1-1 構成は一貫して最悪の構成です。これは、各サーバーのオーバーヘッドがほとんどアイドル狀態 (各ノードに 8 基の A100 GPU と 8 つの CX6 Infiniband アダプターが搭載) であるためと考えられます。
さらに興味深いのは、LAMMPS と ICON の両方が、私たちが収集したデータに対して、実行時間 * エネルギーが最小値に達していないということです。LAMMPS と ICON が最小値を示すには、より大規模な実行が必要です。
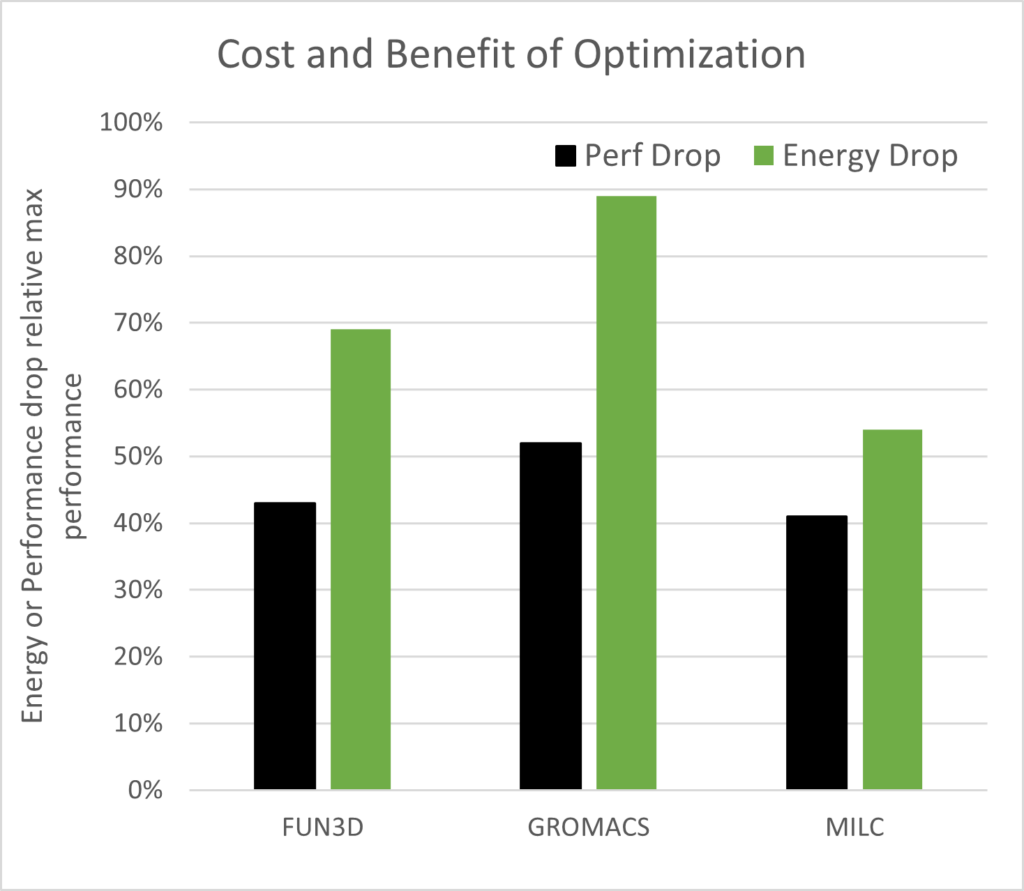
望ましい最適化の結果は、効率を高めてシミュレーションを実行することです。性能低下とシミュレーションごとのエネルギー低減(最大性能ポイントで正規化) を比較することは、最適化された出力が効率向上を達成したことを確認するシンプルな方法です。性能低下がエネルギー低減より小さければ、効率は高いことになり、図 14 の FUN3D、GROMACS、MILC で確認することができます。
最大性能ポイントと比較すれば、エネルギーと性能コストを節約するチャンスがそこにはあります。これを 図 14 が示しています。ICON と LAMMPS は、最適化で最小點を表示しなかったため、プロットしませんでした。望ましい結果は、性能の低下がシミュレーションごとに使用されるエネルギーよりも少ないことであり、FUN3D、GROMACS、MILC ではまさにそれが見られます。
マルチノードのスケーラビリティとエネルギーの交差點を辿る
データ センターの成長と AI の探求と利用の拡大は、データ センター、データ センターのスペース、冷卻、電気エネルギーに対する需要を増大させるでしょう。化石燃料から発電される電力の割合を考えると、データ センターのエネルギー需要によって引き起こされる溫室効果ガスは、管理しなければならない問題です。
NVIDIA は、社內の改革と將來の製品設計への影響に引き続き注力し、AI 革命が社會に與えるプラスの影響を最大化します。NVIDIA アクセラレーテッド コンピューティング プラットフォームを使用することで、研究者は単位時間あたりにより多くの科學的成果を得ることができ、より少ないエネルギーの使用でそれぞれの科學的成果を得ることができます。このようなエネルギーの節約は、比例して二酸化炭素排出量を削減し、地球上のすべての人々に利益をもたらします。
VASP とエネルギー効率に焦點を當てた詳細については、「NVIDIA Magnum IO によるマルチノード VASP シミュレーションのエネルギー効率を最適化する」をお読みください。
この短い議論と一連の結果は、HPC センターが研究コミュニティに提供するリソースを割り當て、追跡する方法を変更するための議論を開始するために提供されます。また、大規模な並列シミュレーションを実行する際の選択と、その下流への影響を考慮するよう、ユーザーに影響を與えるかもしれません。
HPC と AI シミュレーションの解決に辿り著くまでのエネルギーと、ここで議論されている解決に至るまでの時間との多目的最適化のバランスについて、會話を始める時です。いつの日か、HPC コミュニティは、メガワット時、あるいは CO2 排出量 1 トン當たりの科學的進歩を測定することになるかもしれません。
詳細については、NVIDIA サステイナブル コンピューティングをご覧ください。そして NERSC とアクセラレーテッド プラットフォームの影響についても、お読みください。また、Alan Gray の NVIDIA 2023 GTC セッションで、効率を最大化するためのアクセラレーテッド プラットフォームのチューニングについてご視聴ください。
関連情報
- GTC セッション: Energy Efficiency: An Application’s Perspective (Spring 2023)
- GTC セッション: Reducing the Environmental Impact of HPC using Dynamic Frequency Scaling (Spring 2023)
- GTC セッション: Optimizing Energy Efficiency for Applications on NVIDIA GPUs (Spring 2023)
- ウェビナー: Accelerate High-Fidelity Computational Fluid Dynamics with GPUs
- ウェビナー: How to Create a Power-Efficient Data Center with DPUs
- ウェビナー: Accelerating the Hybrid Cloud for AI and Data Analytics
翻訳に関する免責事項
この記事は、「Energy Efficiency in High-Performance Computing: Balancing Speed and Sustainability」の抄訳で、お客様の利便性のために機械翻訳によって翻訳されたものです。NVIDIA では、翻訳の正確さを期すために注意を払っておりますが、翻訳の正確性については保証いたしません。翻訳された記事の內容の正確性に関して疑問が生じた場合は、原典である英語の記事を參照してください。





