
本記事では、NeMo Framework を使用して、日本語データセットで大規模言語モデル (LLM) の継続事前學習を実行する方法を説明します。
NeMo Framework とは
NeMo Framework は、LLM をはじめ、生成 AI モデルを構築、カスタマイズするためのクラウドネイティブなフレームワークです。NGC 上にコンテナーが公開されており、すぐに利用を開始することができます。
NeMo Framework は、NGC 上に公開されているコンテナーを無償利用していただくこともできますが、NVIDIA AI Enterprise の対象ソフトウェアとなっているため、エンタープライズ サポートを希望される場合は NVIDIA AI Enterprise ライセンスの購入をご検討ください。
LLM のワークフロー
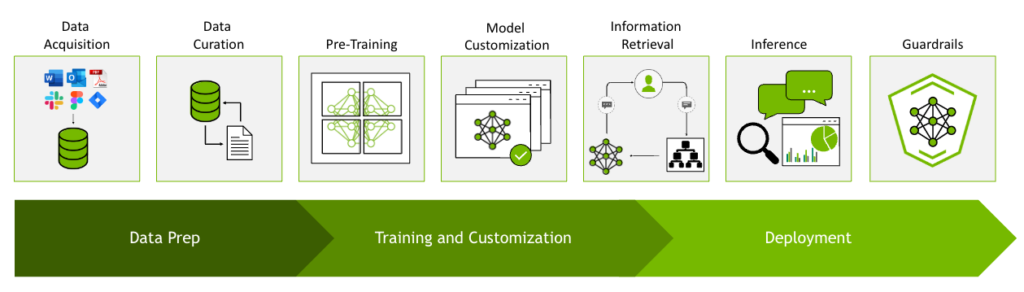
LLM の開発におけるタスクには以下のようなものがあります。
- 事前學習に必要な大規模データの準備
- 分散學習を利用した LLM の事前學習
- LLM をカスタマイズするためのファインチューニングやアライメントおよびプロンプトエンジニアリング
- LLM の推論を高速化するためのモデル最適化
- GPU を最大限に活用した LLM のサービング
- コストを抑えながら LLM に最新情報を反映させるための RAG
- LLM アプリケーションの意図しない挙動を抑えるためのガードレール
LLM の開発、サービスでの利用には多くのステップが必要になりますが、NeMo Framework コンテナーには、データの準備から LLM の學習、カスタマイズに必要な下記モジュールが含まれており、これらを使用することで LLM の構築に関するステップを 1 つのコンテナー環境で実行できます。
- NeMo Curator
LLM の學習に必要な大規模データセットのダウンロードから抽出、クリーニング、フィルタリングなどを行うためのスケーラブルなツールキット。 - NeMo
LLM、マルチモーダル、音聲などの生成 AI モデルを構築するためのスケーラブルなフレームワーク。 - NeMo Framework Launcher
クラウド、オンプレのクラスターからジョブを起動するためのツールキット。 - Megatron-LM
Transformer モデルの大規模學習に関する研究プロジェクト。 - Transformer Engine
FP8 を中心とした Transformer モデルを高速化させるツールキット。 - NeMo-Aligner
人間のフィードバックからの強化學習 (RLHF) 、DPO、SteerLM などを使用して LLM を効率的にアライメントするためのツールキット。
これらのライブラリは、GitHub 上に OpenSource として公開されていますが、依存関係が解消されている NeMo Framework コンテナーから利用することをお薦めします。コンテナーの場合、/opt ディレクトリ配下に上記のモジュールが配置されています。
継続事前學習とは
継続事前學習 (Continual Pre-training) とは、事前學習済みのモデルを下流タスクでファインチューニングする前に、下流タスクに関連したデータで事前學習タスクを追加的に実施し、ドメイン適応を行う手法です。
ここでは例として日本語を上手く扱える LLM を構築するケースを考えてみます。日本語のように (英語に比べ) リソースが少ない言語でフルスクラッチで事前學習を実施するには、モデルの規模に応じて多くのデータを収集、合成するなどしなければなりません。また、それらのデータに対してはクリーニング、重複排除、フィルタリングなどを実施しなければならず、これらの作業負荷も発生します。さらに、モデルがゼロから目標とするタスクで高いパフォーマンスを獲得するまでには、長い學習ステップが必要になります。
一方で、継続事前學習では、大規模な (主に英語) データで學習されたモデルを開始點にすることで、フルスクラッチに比べ、少量のデータでもモデルを新しい言語やタスクに効果的に適応させることができます。これは低リソースな言語やドメインでは特に有効なアプローチとなります。
既存の LLM に対して、日本語で継続事前學習を実施しているモデルは Swallow LLM をはじめ、多くの事例があります。また、NVIDIA ではチップ設計に特化させるためにドメイン適応を実施した ChipNeMo などの事例があります。リソース不足が課題となる言語やドメインでは、こうした手法がモデルの適応範囲を広げてくれます。同時に、各國が自國のデータや計算資源を活用し、獨自の AI 技術を構築するソブリン AI の重要性も認識されるようになりました。
ソブリン AI の重要性
各國が自國の経済発展やデータ管理を目的に、自律的かつ獨立した AI 技術の構築を目指す取り組みとしてソブリン AI が注目されています。ソブリン AI とは、國家が自國のインフラ、データ、労働力、ビジネスネットワークを活用して開発した人工知能、およびそれを開発/運用する能力を指します。
生成 AI の臺頭により、近年ソブリン AI は特に重要性を増しています。
まず安全保障の観點で、ソブリン AI を推進することにより、各國が自國のデータや技術インフラを完全に管理することで、外部依存を減らし、安全性やプライバシー保護を強化することができます。特にサイバーセキュリティや気候変動対策など、國家規模で取り組むべき課題への対応力や、エネルギー効率向上といった持続可能性への取り組みでも、ソブリン AI は重要な役割を果たします。また、ソブリン AI は自國の経済や産業の競爭力強化にも不可欠であるだけでなく、地域特有の言語や文化、慣習に適応したモデルを開発することで、地域のイノベーションを支援し、多様性の保護やその地域の社會ニーズや優先事項に沿った AI 技術を開発することを可能にします。
ソブリン AI は単なる技術ではなく、國家戦略として社會全體に大きな影響を與える重要な要素となっています。そのため、各國が獨自の取り組みを進める中で、日本もソブリン AI に注力しており、人材育成、日本語モデル開発、自然災害対応など多岐にわたる分野で NVIDIA との協業が進められています。
継続事前學習チュートリアル
本記事では、Hugging Face Model Hub から meta-llama/Llama-3.1-8B をダウンロードして、NeMo Framework を使用して継続事前學習を実行します。
このチュートリアルは、シングル ノードで日本語 Wikipedia データを使用した小規模な構成になっていますが、よりデータを増やし、マルチ ノードの計算環境を使用することで、大規模な學習に変更することも容易です。
本チュートリアルでの手順は以下の通りです。
- 継続事前學習を実行するための事前準備
- NeMo Framework のコンテナーを起動
- Hugging Face Model Hub から事前學習済みのモデルをダウンロード
- ダウンロードしたモデルを nemo フォーマットへ変換
- 継続事前學習に使用するデータの準備および前処理
- 継続事前學習の実行
また、今回のチュートリアルの検証環境は以下の條件で行っております。
- ハードウェア
- DGX H100
- GPU: 8 x NVIDIA H100 80 GB GPUs (driver version: 550.90.7)
- CPU: Intel(R) Xeon(R) Platinum 8480C
- システム メモリ: 2 TB
- ソフトウェア
- OS: Ubuntu 22.04.5 LTS
- Container:
nvcr.io/nvidia/nemo:24.09
事前準備
以下のコマンドで作業用のディレクトリを作成し、移動します。
mkdir cp-example
cd cp-exampleDocker コンテナーの起動
以下のコマンドでコンテナーを起動します。
sudo docker run --rm -it --gpus all --shm-size=16g --ulimit memlock=-1 --network=host -v ${PWD}:/workspace -w /workspace nvcr.io/nvidia/nemo:24.09 bashHugging Face Model Hub からモデルのダウンロード
このチュートリアルでは、meta-llama/Llama-3.1-8B を使用します。以下のコードで Hugging Face の Model Hub からモデルをダウンロードします。このモデルは、アクセス許可が必要なため、huggingface のアカウントで許可をとった後に以下のコマンドでログインします。
huggingface-cli login次にモデルをダウンロードします。
import os
from huggingface_hub import snapshot_download
MODEL_DIR = "./models"
os.makedirs(MODEL_DIR, exist_ok=True)
snapshot_download(
repo_id="meta-llama/Llama-3.1-8B",
local_dir=f"{MODEL_DIR}/Llama-3.1-8B",
)nemo フォーマットへの変換
スクリプトを使用して、ダウンロードした HuggingFace のモデルを nemo フォーマットへ変換します。今回、Llama-3.1 のモデルを変換するために、チュートリアルで使用する nvcr.io/nvidia/nemo:24.09 へ、 PR#11548 と PR#11580 を反映させます。
cd /opt/NeMo/
curl -L https://github.com/NVIDIA/NeMo/pull/11548.diff | git apply
curl -L https://github.com/NVIDIA/NeMo/pull/11580.diff | git apply次に以下のスクリプトを実行します。
export INPUT="/workspace/models/Llama-3.1-8B"
export OUTPUT="/workspace/models/Llama-3.1-8B.nemo"
export PREC="bf16"
python /opt/NeMo/scripts/checkpoint_converters/convert_llama_hf_to_nemo.py --input_name_or_path ${INPUT} --output_path ${OUTPUT} --precision ${PREC} --llama31 True生成された Llama-3.1-8B.nemo ファイルは、distributed checkpoint が使用されているため、Llama-3.1-8B.nemo の checkpoint を都度変更することなく、任意の Tensor Parallel (TP) や Pipeline Parallel (PP) などモデル パラレルの組み合わせでロードすることができます。
データの準備
このチュートリアルでは、llm-jp-corpus-v3 の中に含まれている ja_wiki を利用します。以下のコマンドでデータをダウンロードし、data というディレクトリに格納しておきます。
cd /workspace/
mkdir -p data/ja_wiki
wget -O data/ja_wiki/train_0.jsonl.gz --no-check-certificate https://gitlab.llm-jp.nii.ac.jp/datasets/llm-jp-corpus-v3/-/raw/main/ja/ja_wiki/train_0.jsonl.gz?ref_type=heads
wget -O data/ja_wiki/train_1.jsonl.gz --no-check-certificate https://gitlab.llm-jp.nii.ac.jp/datasets/llm-jp-corpus-v3/-/raw/main/ja/ja_wiki/train_1.jsonl.gz?ref_type=heads
wget -O data/ja_wiki/train_2.jsonl.gz --no-check-certificate https://gitlab.llm-jp.nii.ac.jp/datasets/llm-jp-corpus-v3/-/raw/main/ja/ja_wiki/train_2.jsonl.gz?ref_type=heads
wget -O data/ja_wiki/train_3.jsonl.gz --no-check-certificate https://gitlab.llm-jp.nii.ac.jp/datasets/llm-jp-corpus-v3/-/raw/main/ja/ja_wiki/train_3.jsonl.gz?ref_type=heads
wget -O data/ja_wiki/train_4.jsonl.gz --no-check-certificate https://gitlab.llm-jp.nii.ac.jp/datasets/llm-jp-corpus-v3/-/raw/main/ja/ja_wiki/train_4.jsonl.gz?ref_type=heads
wget -O data/ja_wiki/train_5.jsonl.gz --no-check-certificate https://gitlab.llm-jp.nii.ac.jp/datasets/llm-jp-corpus-v3/-/raw/main/ja/ja_wiki/train_5.jsonl.gz?ref_type=heads
wget -O data/ja_wiki/train_6.jsonl.gz --no-check-certificate https://gitlab.llm-jp.nii.ac.jp/datasets/llm-jp-corpus-v3/-/raw/main/ja/ja_wiki/train_6.jsonl.gz?ref_type=heads
wget -O data/ja_wiki/train_7.jsonl.gz --no-check-certificate https://gitlab.llm-jp.nii.ac.jp/datasets/llm-jp-corpus-v3/-/raw/main/ja/ja_wiki/train_7.jsonl.gz?ref_type=heads
wget -O data/ja_wiki/train_8.jsonl.gz --no-check-certificate https://gitlab.llm-jp.nii.ac.jp/datasets/llm-jp-corpus-v3/-/raw/main/ja/ja_wiki/train_8.jsonl.gz?ref_type=heads
wget -O data/ja_wiki/train_9.jsonl.gz --no-check-certificate https://gitlab.llm-jp.nii.ac.jp/datasets/llm-jp-corpus-v3/-/raw/main/ja/ja_wiki/train_9.jsonl.gz?ref_type=heads
wget -O data/ja_wiki/train_10.jsonl.gz --no-check-certificate https://gitlab.llm-jp.nii.ac.jp/datasets/llm-jp-corpus-v3/-/raw/main/ja/ja_wiki/train_10.jsonl.gz?ref_type=heads
wget -O data/ja_wiki/train_11.jsonl.gz --no-check-certificate https://gitlab.llm-jp.nii.ac.jp/datasets/llm-jp-corpus-v3/-/raw/main/ja/ja_wiki/train_11.jsonl.gz?ref_type=heads
wget -O data/ja_wiki/train_12.jsonl.gz --no-check-certificate https://gitlab.llm-jp.nii.ac.jp/datasets/llm-jp-corpus-v3/-/raw/main/ja/ja_wiki/train_12.jsonl.gz?ref_type=heads
wget -O data/ja_wiki/train_13.jsonl.gz --no-check-certificate https://gitlab.llm-jp.nii.ac.jp/datasets/llm-jp-corpus-v3/-/raw/main/ja/ja_wiki/train_13.jsonl.gz?ref_type=heads
wget -O data/ja_wiki/validation_0.jsonl.gz --no-check-certificate https://gitlab.llm-jp.nii.ac.jp/datasets/llm-jp-corpus-v3/-/raw/main/ja/ja_wiki/validation_0.jsonl.gz?ref_type=heads
gunzip data/ja_wiki/*以下のスクリプトを使用して、NeMo のバックエンドで使用されている Megatron で継続事前學習が実行できるようにデータを処理します。
mkdir ds
# for training data
python /opt/NeMo/scripts/nlp_language_modeling/preprocess_data_for_megatron.py --input="/workspace/data/ja_wiki" --json-keys=text --tokenizer-library=huggingface --tokenizer-type="meta-llama/Llama-3.1-8B" --dataset-impl mmap --append-eod --output-prefix="/workspace/ds/train" --workers=24 --files-filter '**/train_*.json*' --preproc-folder --log-interval 10000
# for validation data
python /opt/NeMo/scripts/nlp_language_modeling/preprocess_data_for_megatron.py --input="/workspace/data/ja_wiki" --json-keys=text --tokenizer-library=huggingface --tokenizer-type="meta-llama/Llama-3.1-8B" --dataset-impl mmap --append-eod --output-prefix="/workspace/ds/validation" --workers=24 --files-filter '**/validation_*.json*' --preproc-folder --log-interval 1000スクリプトが実行されると ds というディレクトリに以下のファイルが出力されます。
train_text_document.bin
train_text_document.idx
validation_text_document.bin
validation_text_document.idx継続事前學習の実行
継続事前學習は NeMo の /opt/NeMo/examples/nlp/language_modeling/megatron_gpt_pretraining.py で実行できます。
/opt/NeMo/examples/nlp/language_modeling/conf/megatron_gpt_config.yaml に継続事前學習を実行する際に參照される config ファイルがあり、このファイルを直接上書きするか、別の config ファイルを參照するよう変更するか、コマンドラインから上書きする (NeMo Framework は config 設定に Hydra を使用しています) かでモデルの學習に必要な情報を渡します。指定されていない設定については、config ファイルの設定が適用されます。
また、ここで実行されるスクリプトは事前學習用のスクリプトになっており、model.restore_from_path を指定しない場合は、継続ではなく新たに事前學習が開始できます。
このチュートリアルでは、以下のようなスクリプトを用意し、コマンドラインから上書きして學習ジョブを実行します。
実行の際に Llama-3.1 では model_config の設定により、HF のリポジトリからトークナイザのダウンロードが発生します。実行前に読み取り権限のあるアクセストークンで HuggigFace にログインしていることを確認してください。
export HYDRA_FULL_ERROR=1
export OC_CAUSE=1
export TORCH_DISTRIBUTED_DEBUG=INFO
export WANDB=False
export PJ_NAME="CP"
export EXP_DIR="./results/"${PJ_NAME}
export EXP_NAME="Llama-3.1-8B"
export MODEL="/workspace/models/Llama-3.1-8B.nemo"
export TOKENIZER_LIBRARY="huggingface"
export TOKENIZER_TYPE="meta-llama/Llama-3.1-8B"
export TOKENIZER="/workspace/models/Llama-3.1-8B/tokenizer.json"
export TP_SIZE=2
export SP=False
export PP_SIZE=1
export EP_SIZE=1
TRAIN_DATA_PATH="{train:[1.0,/workspace/ds/train_text_document],validation:[/workspace/ds/validation_text_document],test:[/workspace/ds/validation_text_document]}"
python /opt/NeMo/examples/nlp/language_modeling/megatron_gpt_pretraining.py \
exp_manager.exp_dir=${EXP_DIR} \
exp_manager.name=${EXP_NAME} \
exp_manager.create_wandb_logger=${WANDB} \
exp_manager.wandb_logger_kwargs.project=${PJ_NAME} \
exp_manager.wandb_logger_kwargs.name=${EXP_NAME} \
exp_manager.checkpoint_callback_params.save_nemo_on_train_end=True \
exp_manager.checkpoint_callback_params.save_top_k=3 \
exp_manager.checkpoint_callback_params.always_save_nemo=False \
trainer.precision=bf16 \
trainer.devices=8 \
trainer.num_nodes=1 \
trainer.max_epochs=-1 \
trainer.max_steps=150 \
trainer.log_every_n_steps=1 \
trainer.val_check_interval=15 \
trainer.limit_val_batches=1 \
trainer.limit_test_batches=1 \
trainer.gradient_clip_val=1.0 \
model.restore_from_path=${MODEL} \
model.encoder_seq_length=8192 \
model.max_position_embeddings=8192 \
model.num_layers=32 \
model.hidden_size=4096 \
model.ffn_hidden_size=14336 \
model.num_attention_heads=32 \
model.hidden_dropout=0.0 \
model.attention_dropout=0.0 \
model.apply_query_key_layer_scaling=True \
model.bias=False \
model.activation=fast-swiglu \
model.normalization=rmsnorm \
model.position_embedding_type=rope \
+model.rotary_base=5000000.0 \
model.share_embeddings_and_output_weights=False \
model.num_query_groups=8 \
model.scale_positional_embedding=True \
model.bias_activation_fusion=False \
model.bias_dropout_add_fusion=False \
model.tokenizer.library=${TOKENIZER_LIBRARY} \
model.tokenizer.type=${TOKENIZER_TYPE} \
model.tokenizer.model=${TOKENIZER} \
model.megatron_amp_O2=True \
model.tensor_model_parallel_size=${TP_SIZE} \
model.pipeline_model_parallel_size=${PP_SIZE} \
model.sequence_parallel=${SP} \
model.expert_model_parallel_size=${EP_SIZE} \
model.transformer_engine=True \
model.fp8=False \
model.seed=42 \
model.enable_megatron_timers=False \
model.optim.name=distributed_fused_adam \
model.optim.lr=2.5e-5 \
model.optim.weight_decay=0.1 \
model.optim.betas=[0.9,0.95] \
model.optim.sched.warmup_steps=15 \
model.optim.sched.constant_steps=0 \
model.optim.sched.min_lr=2.5e-6 \
model.micro_batch_size=1 \
model.global_batch_size=1024 \
model.data.data_prefix=${TRAIN_DATA_PATH} \
model.data.validation_drop_last=True \
model.data.num_workers=2NeMo Framework は、実験管理のために Weights and Biases をサポートしており、上記のスクリプトを、export WANDB=True と変更することで wandb 上で実験管理することができます。
上記の設定では、學習は 6 時間ほどで完了しました。
ジョブが途中で中斷された際に再開したい場合は、同じコマンドを再度実行すると checkpoints 內にある -last がついたチェックポイントが読み込まれ、再開できます。
學習が終わると results/CP/ という名前のディレクトリが作成され、中に學習時の config や log などが出力されます。また、同じディレクトリの checkpoints 內にある Llama-3.1-8B.nemo が 今回の継続事前學習 で作成されたモデルになります。
作成されたモデルは、同一フォーマットのまま、SFT などの後続ステップで活用することもできますし、NVIDIA NIM を活用してカスタマイズしたモデルをデプロイすることもできます。Hugging Face フォーマットへ変換することも可能です。
NeMo Framework コンテナー上で推論を実行するチュートリアルはこちらにあります。nemo フォーマットから、Hugging Face フォーマットへ変換するスクリプトはこちらにあります。
參考: Nejumi リーダーボード 3 での評価
Nejumiリーダーボード 3 は、LLM の日本語能力をさまざまな評価データセットを用いて多面的に評価できるベンチマークです。ベンチマーク用のスクリプトを実行することで、自社のモデルをさまざまなモデルと比較することが可能です。
ご自身の環境で実行する際は、wandb の GitHubリポジトリを參照してください。
今回はこのチュートリアルで作成したモデルとオリジナルの meta-llama/Llama-3.1-8B についてベンチマークを計測しました。MT-bench (160 サンプル) で 2 つのモデルの応答を比べてみると日本語の指示文に対して、オリジナルのモデルは 3-4 割ほどの応答が英語になっていたのに対し、今回作成したモデルでは英語の応答は數件程度に減少しました。
まとめ
本記事では、NeMo Framework を使用した継続事前學習の実行方法を紹介しました。繰り返しになりますが、このチュートリアルの內容は、より大きなデータと計算環境でスケールさせることが可能です。NeMo Framework を使用して、日本語やビジネス ドメインに特化したソブリン AI の開発が加速すると嬉しいです。
関連情報
- 技術ドキュメント: NVIDIA NeMo Framework User Guide
- 技術ドキュメント: NeMo Framework Single Node Pre-training
- 技術ブログ: Training Localized Multilingual LLMs with NVIDIA NeMo, Part 1
- 技術ブログ: Training Localized Multilingual LLMs with NVIDIA NeMo, Part 2
- 技術ブログ: NeMo Curator を使った日本語データのキュレーション
- 技術ブログ: NeMo Framework で日本語 LLM をファインチューニング – SFT 編 –
- 技術ブログ: NeMo Framework で日本語 LLM をファインチューニング – PEFT 編 –
- 技術ブログ: NeMo Framework で日本語 LLM をファインチューニング – DPO 編 –
- 技術ブログ: NVIDIA NIM でファインチューニングされた AI モデルのデプロイ





