<xmp id="om0om">
<td id="om0om"></td>
<table id="om0om"><noscript id="om0om"></noscript></table>
DEVELOPER
ホーム
ブログ
フォーラム
ドキュメント
ダウンロード
トレーニング
Search
Join
AI Inference
2024 年 11 月 8 日
NVIDIA TensorRT-LLM の KV Cache Early Reuseで、Time to First Token を 5 倍高速化
KV キャッシュの再利用技術と、TTFT のさらなる高速化を実現するベストプラクティスについて解説します。
2 MIN READ
NVIDIA TensorRT-LLM の KV Cache Early Reuseで、Time to First Token を 5 倍高速化
2024 年 4 月 2 日
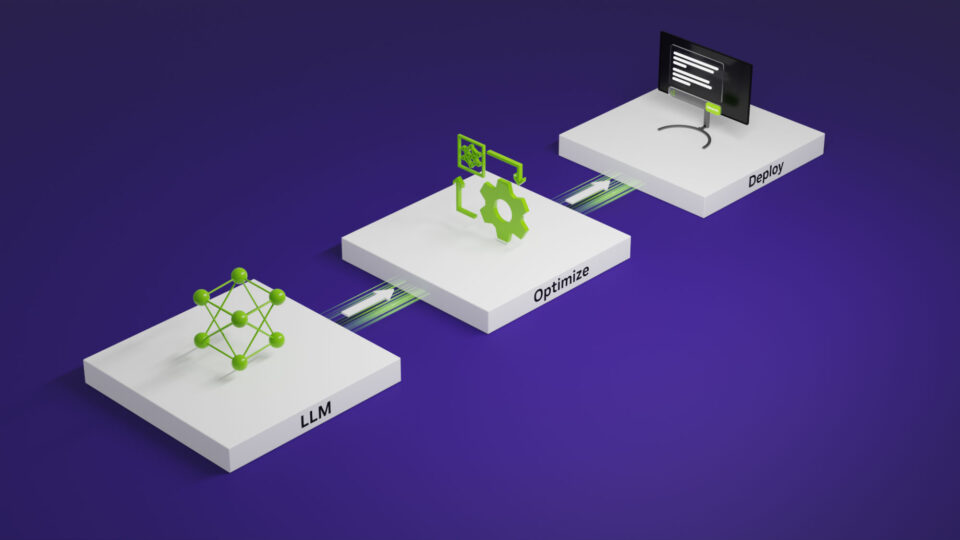
NVIDIA TensorRT-LLM による、LoRA LLM のチューニングとデプロイ
LLM のトレーニング コストを抑え、そのパワーを活用可能なファインチューニングの手法の 1 つである、Low-Rank Adaptation (LoRA) の洞察力と実裝について説明し、その応用と利點の一部をご紹介します。
7 MIN READ
NVIDIA TensorRT-LLM による、LoRA LLM のチューニングとデプロイ
2024 年 3 月 18 日
NVIDIA GB200 NVL72 は兆単位パラメーターの LLM トレーニングとリアルタイム推論を実現
新しい NVIDIA GB200 NVL72 は、計算負荷が高く、リソースを大量に消費する大規模なモデルのトレーニングとデプロイに対応するシステムの 1 つです。
4 MIN READ
NVIDIA GB200 NVL72 は兆単位パラメーターの LLM トレーニングとリアルタイム推論を実現
2024 年 1 月 17 日
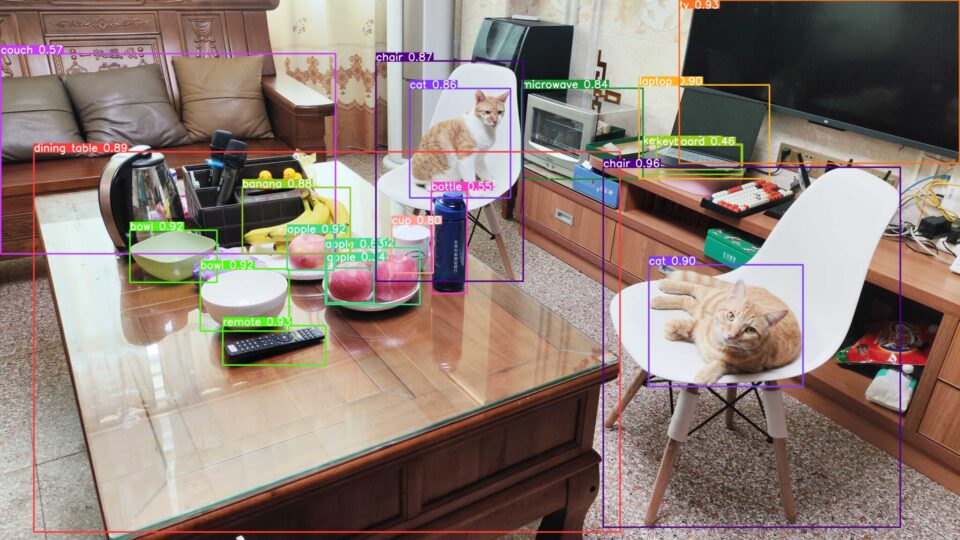
cuDLA による NVIDIA Jetson Orin 上での YOLOv5 の紹介
この投稿は、Orin プラットフォームを使用する組込み開発者が、YOLOv5 をリファレンスとして、
5 MIN READ
cuDLA による NVIDIA Jetson Orin 上での YOLOv5 の紹介
2023 年 11 月 17 日
LLM テクニックの習得: 推論の最適化
LLM 推論における最も差し迫った課題と、いくつかの実用的な解決策について説明します。
6 MIN READ
LLM テクニックの習得: 推論の最適化
詳細を見る
人人超碰97caoporen国产
Search
Join
ホーム
ブログ
フォーラム
ドキュメント
ダウンロード
トレーニング