あらゆる業界や業務で、生成 AI が組織內の可能性を引き出し、データを知識に変え、従業員がより効率的に働けるようにしています。?
正確で関連性のある情報は、データに基づく意思決定のために重要です。このため、企業はビジネス データの保存、インデックス作成、アクセスの方法を改善するために投資を続けています。
IDC Global DataSphere Forecast 2023 によると、2024 年には、企業固有のデータが 11 ゼタバイト生成されると言われています。企業が生成する固有のデータの量は 2027 年までに 20 ゼタバイトになると予測されており、そのうち、83% は構造化されておらず、半分は音聲と動畫になるとのことです。2027 年に生成される非構造化データの量は、約 80 萬館の議會図書館に相當します。企業の環境では、この情報は複數のデータ レイクにまたがるデータから抽出する必要があります。?
この情報にアクセスするため、ライブ ダッシュボード、グラフ、表、図が混在する手動作成レポート、テキスト、データベース クエリ、汎用検索ツールなど、さまざまなソースが使用されます。
情報の內容と文脈の両方が時間の経過と共に変化するため、そうしたソース全體で情報を使用し、証拠や決定を再評価するというサイクルを繰り返す必要があります。複雑なビジネス上の質問に答えるとき、このプロセスは手動で集中的に行われ、時間がかかることがあります。関連するデータ ポイントにアクセスするための簡単なソリューションがないため、情報が十分に活用されない可能性があります。
生成 AI を使用することで、ツールを使用してデータを検索し、質問に答えることができる対話型インターフェイスを構築できるようになりました。つまり、データに話しかけることで意思決定が速くなり、より賢くなります。NVIDIA NeMo Retriever はこのプロセスのあらゆる段階を支援します。
NVIDIA NeMo Retriever とは?
カスタム生成 AI を開発するためのエンドツーエンド プラットフォームである NVIDIA NeMo に含まれる NeMo Retriever は、企業データのセマンティック検索を可能にし、検索拡張機能を使用して高い精度で応答するマイクロサービスからなるコレクションです。開発者はさまざまな GPU 対応マイクロサービスを活用しますが、それぞれ、以下のような特定のタスクを処理するように調整されています。
- PDF レポート、Office ドキュメント、その他のリッチ テキスト ファイルの形式で大量のドキュメントを取り込む。
- セマンティック検索のために上記をエンコードして保存する。
- 既存のリレーショナル データベースとやりとりする。
- ビジネス上の質問に答えるために関連情報を検索する。
こうしたマイクロサービスは、使いやすさ、信頼性、パフォーマンスを最大化するために、CUDA、NVIDIA TensorRT、NVIDIA Triton Inference Server、NVIDIA ソフトウェア スイートの他の多くの SDK をベースに構築されています。

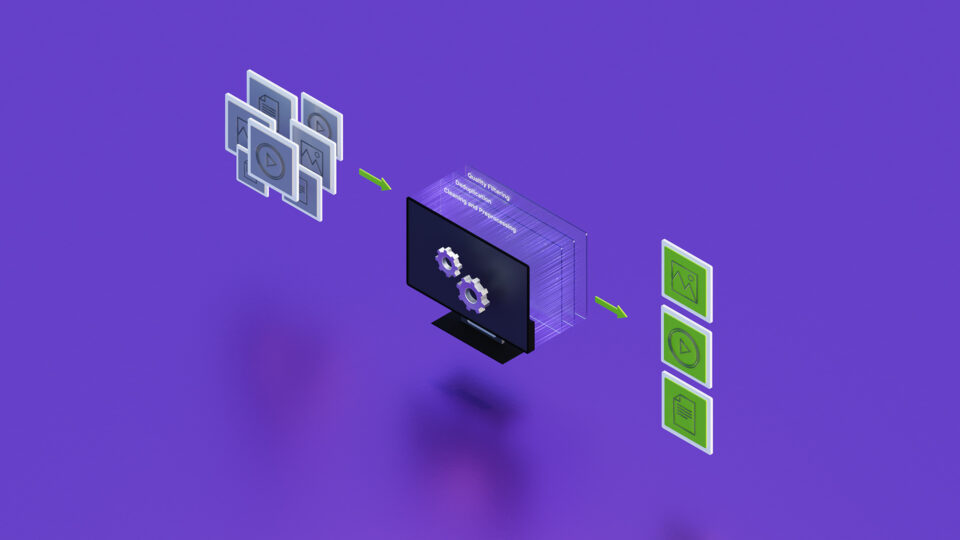
複雑なビジネス上の質問に答えるには大抵、効果的な計畫と専門的なツールが必要になり、また、さまざまなモダリティにまたがるデータから情報を抽出することが必要になります (図 1)。これは、LLM を活用した AI エージェントを構築することで達成できます。NeMo Retriever を活用したエージェントの構築に関するガイドラインを提供するために、マイクロサービスはいくつかのリファレンス エージェントと共にパッケージ化されています。?
これらのマイクロサービスとエージェントでは、関連情報を見つけてまとめるという時間のかかる手作業に人間が時間を費やすのではなく、複雑で専門知識を必要とすることが多い「適切な質問をして回答する」ことに人間が集中できるようにすることで、膨大なデータから情報を抽出するプロセスを高速化できます。
世界の企業データを解き放つ
Adobe、Cloudera、Cohesity、DataStax、NetApp、Pure Storage などのデータ プラットフォーム企業は、NVIDIA と協力して NeMo Retriever を活用し、データを価値あるビジネス インサイトに変換しています。
- Adobe 獨自の AI は、世界中で 3 兆以上ある PDF の中から知識を引き出します。
- Cloudera は、NeMo Retriever を Cloudera Machine Learning と統合し、25 エクサバイトの企業データの可能性を引き出すことで、その生成 AI の能力を拡張します。
- Cohesity データ プラットフォームの顧客は、生成 AI インテリジェンスを自社のデータのバックアップとアーカイブに追加できます。
- DataStax Astra DB は NVIDIA NeMo Retriever と NVIDIA NIM 推論マイクロサービスを活用し、RAG アプリケーションのパフォーマンスを改善します。NVIDIA H100 GPU を使用することで、埋め込みとインデックス作成のレイテンシを 10 ms にしています。
- NetApp はエクサバイト規模のデータを解放し、顧客が安全に「自社のデータに話しかけ」ビジネス インサイトを利用できるようにします。
- Pure Storage は、NeMo Retriever マイクロサービス、NVIDIA GPU、オールフラッシュ エンタープライズ ストレージの Pure Storage を活用する RAG パイプラインを開発しました。その結果、同社は AI トレーニングに自社の內部データを使用する企業がインサイトを得るまでの時間を短縮しています。使用されるデータは常に最新の狀態になり、LLM を定期的に再トレーニングする必要がありません。
企業検索の事例
企業が情報に簡単にアクセスできるようになれば、それを活用する方法は無數にあります。このセクションでは、いくつかの事例を見ていきます。いずれのケースでも、ビジネス上の質問に回答するには、的を絞った一連の質問に回答する必要があります。さまざまなモダリティとデータ ストアにまたがって情報を抽出することによってのみ生成できる回答です。
ソフトウェア セキュリティの脆弱性を分析する
共通脆弱性識別子 (CVE) のためにソフトウェア コンテナーをトリアージするプロセスでは、さまざまな異なるデータ ソースから數百もの情報を検索する必要があります。これは數日かかる可能性がある面倒な手動プロセスです。イベントトリガー式の LLM エージェントは、あたかも自分自身と會話しているかのように、 perceive-reason-act (感知し、考え、行動する) ループを何度も実行することで、このプロセスを自動化します。NVIDIA NIM 推論マイクロサービス、NeMo Retriever、NVIDIA Morpheus サイバーセキュリティ AI フレームワークを使用すると、このプロセスを數秒に短縮することができます。
技術的な問題を解決する
次のシナリオを考えてみます。ネットワーク ソリューション エンジニアがデータ センターの問題を診斷しています。このエンジニアは、マシン ログとシステム メトリックを調査し、現狀をより良く理解する必要があります。また、影響を受けたコンポーネントをさらに特定するため、個々のコンポーネントの特定の情報や動作も調べる必要があります。この情報は、技術文書、回路図、ベンダーの SKU カタログなど、さまざまなソースに分散されています (図 2)。

この技術診斷プロセスは反復的プロセスです。多くの場合、エンジニアは問題から遡って考え、複數のハードウェア層とソフトウェア層にまたがる一連の個々のコンポーネントを調べ、根本原因を突き止める必要があります。各コンポーネントには異なるユーティリティがあり、大規模なシステム アーキテクチャの中で特定の目的のために役立ちます。反復プロセスでは、各コンポーネントに関する情報を検索し、ログの動作が予想される動作と一致するかどうか判斷し、予期しない動作が発生した場合に代替手段を特定し、意思決定します。
専門家がケース固有の情報に対話形式でアクセスできるようにすることで、時間とエネルギーを節約し、専門家が専門知識の応用に集中できるようにします。その結果、ダウンタイムが短くなり、効率が上がり、それにともないコストも削減されます。このシナリオは、工場で生産が停止した場合でも、IT 施設にネットワークの問題が発生した場合でも、共通となります。
財務分析のためのコパイロット
財務アナリストは、レポート、會計報告、市場データ、マクロ経済の傾向などをまとめ、ビジネスの見通しを評価するために膨大な時間を費やします。もっと具體的に言うと、NVIDIA 擔當のアナリストが最新の収益結果を評価しているとします。このアナリストはおそらく、(記録の) 寫しとプレス リリース、CFO のコメント、10-K と 10-Q のレポート、四半期プレゼンテーション、そして、構造化されたデータベースに保存されている獨自のモデルなどから結果を確認するでしょう。

金融アナリストは以下のような質問をするかもしれません。
- 「NVIDIA の直近の四半期から得られた重要な點は何ですか?」
- 「過去 9 か月間に NVIDIA のフリー キャッシュ フローはどのくらい変化しましたか?」
- 「S&P 500 と比較して NVDA のパフォーマンスはどうですか?」
これらは、アナリストが調査に相當の時間を費やすことになる、基本的な前提條件となる背景に関する質問です。これらの質問に回答するために必要なデータは多くの場合、さまざまな四半期の複數のレポートを參照し、さまざまなキャッシュ フロー テーブルから情報を抽出することで見つかります。アナリストは、複數のソースからデータを抽出するプロセスを合理化することで、會社の業績のレビューを含むレポートを作成するという重要な収益創出タスクに集中することができるようになります。
企業の業務
セールス チームとオペレーション チームは、顧客関係、金融取引、製品在庫に関するデータにアクセスする必要があります。また、市場の動向、競合狀況、財務分析など、ビジネス上の意思決定のためにまとめられた多數のレポートを活用します。
さらに、SKU カタログ、ベンダー情報、専門家によるレビュー、その他の項目が、詳細を掘り下げる際に參照として必要になることがあります。これらのデータは多くの場合、組織のサイロやダッシュボードにあるか、個々の従業員と共にあります。その結果、ソース全體で斷片化が発生し、十分に活用されない可能性があります。
収益はセールス チームにとって重要な業績指標です。正しい情報を見つけるには、複數のデータ ソースであちこち検索する必要があります。チームが次の四半期の計畫を立てる場合であれ、顧客を教育し力を與える場合であれ、取引を成立する場合であれ、関連情報にアクセスするための統合された対話型のインターフェイスはプロセスの合理化に役立ち、セールス チームは収益を創出することに自らの専門知識を集中させることができます。
まとめ
多くの事例と同様に、この記事でご紹介した事例では、ビジネス上の複雑な質問に簡単に回答できるシステムを作るため、さまざまなモダリティとデータストアに分散されている情報にアクセスする必要があります。NeMo Retriever は、必要なインフラの使いやすさ、信頼性、パフォーマンスを最大化し、ユーザーが「データに話しかける」ことを可能にします。
NeMo Retriever マイクロサービスは NVIDIA API カタログから試すことができます。検索拡張生成を使用するアプリケーションの構築を始めるには、NVIDIA 生成 AI の例をご覧ください。RAG アプリケーションを試作から本番環境に移行する方法については、「4 つのステップで RAG アプリケーションを試作から本番環境に移行する方法」を參照してください。
1出典: IDC、Global DataSphere Forecast、2023 年
関連情報
- GTC セッション: パーソナライズされた基盤モデルで職場の生産性を改革する
- GTC セッション: SQL からチャットまで: NVIDIA でエンタープライズ データ分析に革命を起こす方法
- NGC コンテナー: NeMo フレームワーク
- SDK: NeMo Retriever
- SDK: NeMo Megatron