???? ?? ???????? ????(FL, Federated learning)? ?? ??? ??? ???? ????. ???? ??? ??? ??? ??? ??? ???? ?? ???? ??? ??? ?? ??? AI ??? ??? ? ?? ??. ?? ??? ??? ???19 ??? ?? ?? ??? ?? ????(Federated learning for predicting clinical outcomes in patients with COVID-19)? ?????.
NVIDIA FLARE v2.0? ???? FL SDK???. ??? ???? ??? ???????? ?? ??? ??? ?? ??? ???(weights)?? ??? ???? ???? ??? AI ??? ??? ??? ? ??? ?????.
? ?? ??? ??? ??? ???? ???? ??? ??? ??? ?? ??? ??, ??, ??? ?? ???? ??? ?? ??? ???? ???? ???????? ?? ?????.
NVIDIA FLARE
NVIDIA FLARE? ???? ?????? ??? ??(Federated Learning Application Runtime Environment)? ?????. NVIDIA Clara Train FL ?????? ?? ???? ?? ???, ??? ??, ???, ???19 ??? AI ??????? ????. ??? ??? ???? ???? ? SDK? ????, ??? ?? ??? ? ?? ?????? ?? ????? ?? ??? ? ????. ??? ?? ??? ??? ???? ?? ?? ??? ??? ?? ???? ?????? ???? ???? ??? ? ??.
???(Python)?? ??? NVIDIA FLARE? ???? ?? ??? ??? ?? ?? ?????? ???? ?? ???? ?????? ???(agnostic) ???? ?????. ????(PyTorch)? ????(TensorFlow), ? ??? ???(NumPy)? ??? ??? ??? ??? ???? ?????? ???? ? ???? ??? ????? ?????.
?? ???? ?? ???(FedAvg) ????? ??? ??? ???? ?? ???. ?? ? FL ?????? ??? ??? ??? ???? ?? ????? ?? ?? ?? ??? ??????, ???? ??? ??? ?? ?????. ??? ??? ????? ?? ??? ??? ????? ? ?? ??? ????? ????. ? ??? ??? ?? ??? ?? ? ?????.
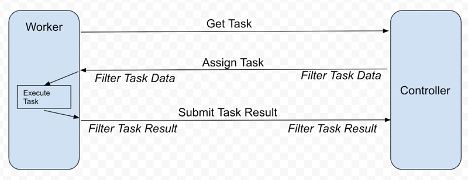
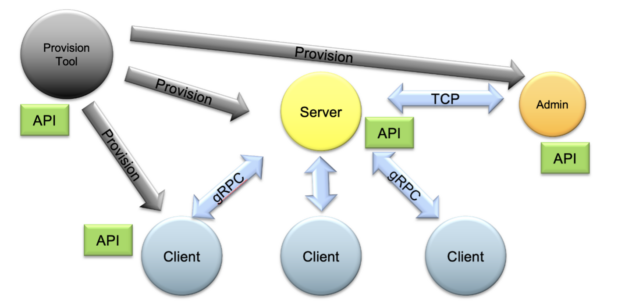
NVIDIA FLARE? ??????? ??? ???? ?????? ?? FedAvg? ??? ?? FL ?????, ?? ??? ??? ??(cyclic weight transfer) ?? ??? ?????. ? ?? ???? ?? ??? ??? ?? FL ??????? ????? ???? ????. ? ?????? ??? ? ???????? ?? ???? ?? ??? ??, ???? ??? ??? ????? ? ? ??? ??? ?? ????? ??? ? ????. ?? 1? ? ??? ?????.
? FL ?????? ??? ???? ? ?? ??? ????? ???? ??(worker) ??? ???. ????? ??? ??? ???? ??? ????? ????. ? ???? ?????(homomorphic encryption)? ???(decryption), ?? ??????? ?? ???? ??? ?????? ??? ??? ??? ? ????.
FedAvg ?? ??? CIFAR-10? ?? ??? ?????? ??? ???? ????? ??? ?? ??? ????. ?? ?? ????? ??? ?? ??? ??? ??? ? ????. ?? ?????? ?? ???? ??(loop)? ???? ??? ??? ???????.
import torch
import torch.nn as nn
import torch.nn.functional as F
from nvflare.apis.dxo import DXO, DataKind, MetaKey, from_shareable
from nvflare.apis.executor import Executor
from nvflare.apis.fl_constant import ReturnCode
from nvflare.apis.fl_context import FLContext
from nvflare.apis.shareable import Shareable, make_reply
from nvflare.apis.signal import Signal
from nvflare.app_common.app_constant import AppConstants
class SimpleNetwork(nn.Module):
def __init__(self):
super(SimpleNetwork, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = torch.flatten(x, 1) # flatten all dimensions except batch
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
class SimpleTrainer(Executor):
def __init__(self, train_task_name: str = AppConstants.TASK_TRAIN):
super().__init__()
self._train_task_name = train_task_name
self.device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
self.model = SimpleNetwork()
self.model.to(self.device)
self.optimizer = torch.optim.SGD(self.model.parameters(), lr=0.001, momentum=0.9)
self.criterion = nn.CrossEntropyLoss()
def execute(self, task_name: str, shareable: Shareable, fl_ctx: FLContext, abort_signal: Signal) -> Shareable:
"""
This function is an extended function from the superclass.
As a supervised learning-based trainer, the train function will run
training based on model weights from `shareable`.
After finishing training, a new `Shareable` object will be submitted
to server for aggregation."""
if task_name == self._train_task_name:
epoch_len = 1
# Get current global model weights
dxo = from_shareable(shareable)
# Ensure data kind is weights.
if not dxo.data_kind == DataKind.WEIGHTS:
self.log_exception(fl_ctx, f"data_kind expected WEIGHTS but got {dxo.data_kind} instead.")
return make_reply(ReturnCode.EXECUTION_EXCEPTION) # creates an empty Shareable with the return code
# Convert weights to tensor and run training
torch_weights = {k: torch.as_tensor(v) for k, v in dxo.data.items()}
self.local_train(fl_ctx, torch_weights, epoch_len, abort_signal)
# compute the differences between torch_weights and the now locally trained model
model_diff = ...
# build the shareable using a Data Exchange Object (DXO)
dxo = DXO(data_kind=DataKind.WEIGHT_DIFF, data=model_diff)
dxo.set_meta_prop(MetaKey.NUM_STEPS_CURRENT_ROUND, epoch_len)
self.log_info(fl_ctx, "Local training finished. Returning shareable")
return dxo.to_shareable()
else:
return make_reply(ReturnCode.TASK_UNKNOWN)
def local_train(self, fl_ctx, weights, epoch_len, abort_signal):
# Your training routine should respect the abort_signal.
...
# Your local training loop ...
for e in range(epoch_len):
...
if abort_signal.triggered:
self._abort_execution()
...
def _abort_execution(self, return_code=ReturnCode.ERROR) -> Shareable:
return make_reply(return_code)???? ??? ??? ???? ??? ??? ??? ? ????. ? ?????? ?? ?? ??? ??? (????? ??? ????) ??? ?????, ?? ???? ???? ?????, ????? ?? ??? ??? ? ??.
FL ???? ? ? ??? ???? ??? ??? ??? ??? ? ????. ? ??? ????? CIFAR-10? ??? ??? ????? 8?? ?????? ??? ??????. ?? 2? NVIDIA FLARE 2.0?? ???? ??? ??? ?? ??? ?????.
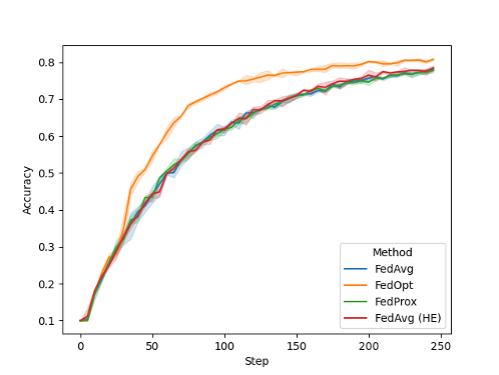
?? ????? FedAvg? FedAvg HE, FedProx? ?? ??? ??? ??????. ?? SGD? ??? ??? ??? ??? ?????? FedOpt ??? ???? ????(convergence)? ??? ? ??.
?? FL ???? ??? API(admin API)? ??? ???? ???? ??? ??? ?????? ?? ?? ??? ? ????. NVIDIA? ?? ??? ????? ???? ?? FL ??????? ?? ???? ???? ???? ??? ? ??? ???? ??, ?? FL ????? ??? ?? ?? ??(proof-of-concept) ??? ?? ?????.
????
NVIDIA FLARE? ????? ?? ??? ?????. ??? ??? ??? ?? ??(wellbore) ??? ??, ????? ?? ?? ???, ?? ??? ?? ?? ?? ?? ?? ?? ??? ??? ??? ??? ??? ??? ????.
? ??? ??? ??? ??? ???(GitHub)? NVIDIA/NVFlare?? ?????.