
?? ??? AI ??? ???? ???? ?? ??? ????, ???? ? ??, ??? ???? ????? ?????. NVIDIA? NVIDIA H100 Tensor ?? GPU? ??? NVIDIA Hopper ????? ?? ?? ?? ???? ??? ?? ?? NVIDIA TensorRT-LLM? ??????. ??? ???? ?? Llama 2 70B? ?? ??? ?? ???? ????? H100 GPU?? ???? FP8 ??? ???? ??? ? ????.
?? ?? ????? AMD? H100 GPU? ?? ??? MI300X ?? ?? ??? ??????. ??? ??? ???? ?????? ???? ????, ??? ?????? ?? H100? 2? ? ????.
??? Llama 2 70B ???? 8?? NVIDIA H100 GPU? ??? ?? NVIDIA DGX H100 ??? ?? ??? ?????. ???? ?? ??? ? ?? ??? ???? ‘Batch-1’? ??? ?? ?? ?? ??? ??? ??? ?? ?????.
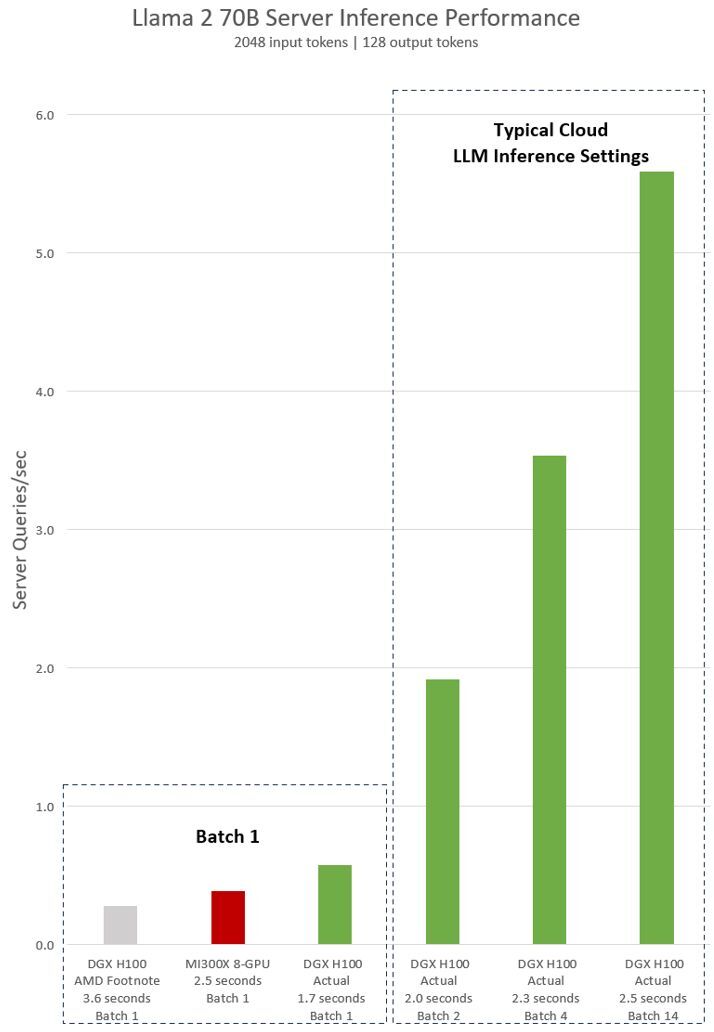
AMD? H100? ?? ??? AMD? ?? ?? ?? #MI300-38?? ??? ??? ???? ???. vLLM v.02.2.2 ?? ?????? NVIDIA DGX H100 ???, ?? ??? ?? 2,048, ?? ??? ?? 128? Llama 2 70B ??? ??????. 8x GPU MI300X ???? ??? DGX H100? ???? ????? ??? ????? ??????.
NVIDIA ?? ???? ??, ????? ?? ??? NVIDIA TensorRT-LLM, batch 1? ?? v0.5.0, ?? ??? ??? ?? v0.6.1? ??? 80GB HBM3? ?? 8x NVIDIA H100 Tensor ?? GPU? ??? DGX H100? ??????. ???? ?? ??? ?? #MI300-38? ?????.
DGX H100? batch ?? 1, ? ? ?? ??? ?? ??? ???? ?? ??? 1.7? ?? ??? ? ????. batch ??? 1?? ??? ??? ? ??? ?? ?? ?? ??? ?? ? ????. ?? ??? ??? ?? ???? ?? ????? ?? ???? ?????? ?? ???? ?? ?? ?? ??? ?????. ?? ?? ?? ?? ??? ? ? ‘batch’? ???? ??? ?? ?? ?? ?? ?? ? ????. MLPerf? ?? ?? ?? ????? ? ?? ?? ?? ????? ??? ?????.
?? ??? ??? ???? ??? ????? ??? ? ?? ?? ??? ?? ?? ??? ? ????. 2.5?? ?? ?? ?? ??? ???? 8-GPU DGX H100 ??? ?? 5? ??? Llama 2 70B ??? ??? ? ?? ??, batch 1? ???? ?? 1? ??? ??? ? ????.
AI? ??? ???? ???, NVIDIA CUDA ?????? ?? ??? ???? ????? ???? ? ????. ??? ?????? ????? ??? AI ??? ????? ??? ????, ?? ???? GitHub ????? ?? ??? ??? ???.
??? AI ?? ??? ???? ??
?? 1? DGX H100 AMD Footnote? ?? vLLM ???????? ????? ???? ?? AMD Footnote?? ??? ??? ?????vLLM?? NVIDIA? ?? ??? ????.
$ python benchmarks/benchmark_latency.py --model "meta-llama/Llama-2-70b-hf" --input-len 2048 --output-len 128 --batch-size 1 -tp 8MI300X 8-GPU? DGX H100 AMD Footnote? vLLM ?? ?? AMD? ??? ?? ??? ???? ??? ?????.
DGX H100 Actual?? NVIDIA???GitHub?? ?? ??? ?? ??? TensorRT-LLM? ?????Llama 2? TensorRT-LLM ???? ???? ??? ???? ???? ??? ????.
// Build TensorRT optimized Llama-2-70b for H100 fp8 tensorcore
$ python examples/llama/build.py --remove_input_padding --enable_context_fmha --parallel_build --output_dir DTYPE.float16_TP.8_BS.14_ISL.2048_OSL.128 --dtype float16 --use_gpt_attention_plugin float16 --world_size 8 --tp_size 8 --pp_size 1 --max_batch_size 14 --max_input_len 2048 --max_output_len 128 --enable_fp8 --fp8_kv_cache --strongly_typed --n_head 64 --n_kv_head 8 --n_embd 8192 --inter_size 28672 --vocab_size 32000 --n_positions 4096 --hidden_act silu --ffn_dim_multiplier 1.3 --multiple_of 4096 --n_layer 80
// Benchmark Llama-70B
$ mpirun -n 8 --allow-run-as-root --oversubscribe ./cpp/build/benchmarks/gptSessionBenchmark --model llama_70b --engine_dir DTYPE.float16_TP.8_BS.14_ISL.2048_OSL.128 --warm_up 1 --batch_size 14 --duration 0 --num_runs 5 --input_output_len 2048,1;2048,128?? ???
- GTC ??: Hopper Tensor ???? ??? CUDA ?? ??
- GTC ??: NVIDIA Triton ?? ??? ??? ??? ?? ?? ??(CoreWeave ??)
- SDK: cuTENSOR
- SDK: cuTENSORMg
- SDK: TensorFlow-TensorRT
- ???: TensorRT? TRITON? ?? ??? ????




