
? ???? NVIDIA? ?? ?? ??? ????? ????? ??? CUDA? ?? ?? ??? ?????. 2013?? CUDA? ?? ?? ???? ?? ???? ???? ?? ??? ???? CUDA ?????? ? ???? GPU? ?? ???? ??? ????? (??? ? ??) ??? ?????.
CUDA C++? CUDA? ??? ?? ??????? ?? ? ?? ?? ? ?????. ??? C++ ????? ??? ???? GPU?? ???? ?? ?? ?? ???? ???? ??? ????? ??? ? ????. ?? ???? ??? ???? ?? ? ???? ?? ???? ??????? ??????, ???? ? ???? ??? ?? ??? ???? ??? ????? ?????? ?????? ?????.
?? CUDA? ?? ??? ???????. ?? ???? ???????? ???? ??? ??????. C ?? C++ ??????? ? ??? ???? ?? ??? ? ????. ? ??? ????? CUDA ?? GPU? ??? ???(Windows, Mac ?? Linux, NVIDIA GPU? ?? ??) ?? GPU? ??? ???? ????(AWS, Azure, IBM SoftLayer ? ?? ???? ??? ?????? ??)? ?????. ?? ??? ???? CUDA ??? ???? ??? ???. ????? GPU?? ???? Jupyter ????? ??? ?? ????.
??? ???!

???? ????
?? ?? ?? ??? ?? ? ??? ??? ???? ??? C++ ?????? ???????.
#include <iostream>
#include <math.h>
// function to add the elements of two arrays
void add(int n, float *x, float *y)
{
for (int i = 0; i < n; i++)
y[i] = x[i] + y[i];
}
int main(void)
{
int N = 1<<20; // 1M elements
float *x = new float[N];
float *y = new float[N];
// initialize x and y arrays on the host
for (int i = 0; i < N; i++) {
x[i] = 1.0f;
y[i] = 2.0f;
}
// Run kernel on 1M elements on the CPU
add(N, x, y);
// Check for errors (all values should be 3.0f)
float maxError = 0.0f;
for (int i = 0; i < N; i++)
maxError = fmax(maxError, fabs(y[i]-3.0f));
std::cout << "Max error: " << maxError << std::endl;
// Free memory
delete [] x;
delete [] y;
return 0;
}?? ? C++ ????? ????? ?????. ?? ??? ??? ?? add.cpp?? ???? ??? ?? C++ ????? ???? ??????. ?? Mac? ???? ??? clang++? ???? ??? Linux??? g++?, Windows??? MSVC? ??? ? ????.
> clang++ add.cpp -o add?? ?? ?????:
> ./add
Max error: 0.000000(Windows??? ?? ?? ??? add.exe? ???? .\add? ??? ? ????.)
???? ??? ??? ??? ??? ?? ?????. ?? ? ??? GPU? ?? ???? (???) ?????. ?? ? ?? ??? ???? ?? ? ????.
?? add ??? GPU? ??? ? ?? ??, ? CUDA? ??? ???? ?? ???. ??? ??? ??? __global__??? ???? ????? ?? ???, ?? CUDA C++ ????? ? ??? GPU?? ???? ???? CPU ???? ??? ? ??? ?????.
// CUDA Kernel function to add the elements of two arrays on the GPU
__global__
void add(int n, float *x, float *y)
{
for (int i = 0; i < n; i++)
y[i] = x[i] + y[i];
}??? __global__ ??? ????? ??, GPU?? ???? ??? ?? ???? ???? ?? CPU?? ???? ??? ??? ???? ???.
CUDA? ??? ??
GPU?? ????? GPU?? ???? ? ?? ???? ???? ???. CUDA? ?? ???? ???? ?? GPU? CPU? ???? ? ?? ?? ??? ??? ???? ?? ?? ????. ?? ???? ???? ????? ???(CPU) ?? ?? ????(GPU) ???? ???? ? ?? ???? ???? cudaMallocManaged()? ???? ???. ???? ????? ???? cudaFree()? ???? ???.
? ???? new? ?? ??? cudaMallocManaged() ??? ??? delete []?? ?? ??? cudaFree? ?? ??? ???? ?? ???.
// Allocate Unified Memory -- accessible from CPU or GPU float *x, *y; cudaMallocManaged(&x, N*sizeof(float)); cudaMallocManaged(&y, N*sizeof(float)); ... // Free memory cudaFree(x); cudaFree(y);
????? GPU?? ?? ???? add() ??? ???? ???. CUDA ?? ??? ?? ?? ?? ?? <<< >>>? ???? ?????. ???? ?? ?? ??? ??? add? ????? ?? ???.
add<<<1, 1>>>(N, x, y);?????! ?? ?? ??? ?????? ? ??? ????????, ??? ? ?? add()? ???? ?? ??? GPU ???? ????? ?? ?? ???.
? ?? ?: CPU? ??? ??? ??? ????? ??? ????? ???(CUDA ?? ??? ???? CPU ???? ???? ????). ?? ?? CPU?? ?? ?? ??? ???? ?? cudaDeviceSynchronize()? ???? ???.
?? ??? ??? ????:
#include <iostream>
#include <math.h>
// Kernel function to add the elements of two arrays
__global__
void add(int n, float *x, float *y)
{
for (int i = 0; i < n; i++)
y[i] = x[i] + y[i];
}
int main(void)
{
int N = 1<<20;
float *x, *y;
// Allocate Unified Memory – accessible from CPU or GPU
cudaMallocManaged(&x, N*sizeof(float));
cudaMallocManaged(&y, N*sizeof(float));
// initialize x and y arrays on the host
for (int i = 0; i < N; i++) {
x[i] = 1.0f;
y[i] = 2.0f;
}
// Run kernel on 1M elements on the GPU
add<<<1, 1>>>(N, x, y);
// Wait for GPU to finish before accessing on host
cudaDeviceSynchronize();
// Check for errors (all values should be 3.0f)
float maxError = 0.0f;
for (int i = 0; i < N; i++)
maxError = fmax(maxError, fabs(y[i]-3.0f));
std::cout << "Max error: " << maxError << std::endl;
// Free memory
cudaFree(x);
cudaFree(y);
return 0;
}CUDA ??? ?? ???? .cu???. ??? ? ??? add.cu?? ??? ???? CUDA C++ ????? nvcc? ??????.
> nvcc add.cu -o add_cuda
> ./add_cuda
Max error: 0.000000? ??? ???? ?? ???? ?? ??? ?? ??? ???? ??? ? ??? ?? ?????? ???? ??? ??? ? ?? ??? ????. ?? ?? ?? ?? ???? ?? ??? ?? ?? ??? ?? ??? ?????.
??: Windows? ?? Microsoft Visual Studio?? ????? ?? ???? ???? x64? ????? ???? ???.
???????!
??? ???? ? ??? ??? ???? ?? ??? ??? CUDA ??? ?? ???? ??? GPU ?????? nvprof? ??? ???? ????. ???? nvprof ./add_cuda? ????? ?? ???:
$ nvprof ./add_cuda
==3355== NVPROF is profiling process 3355, command: ./add_cuda
Max error: 0
==3355== Profiling application: ./add_cuda
==3355== Profiling result:
Time(%) Time Calls Avg Min Max Name
100.00% 463.25ms 1 463.25ms 463.25ms 463.25ms add(int, float*, float*)
...?? nvprof? ?? ????, add? ?? ??? ?????. NVIDIA Tesla K80 ?????? ? 0.5?? ???, 3?? ? Macbook Pro? NVIDIA GeForce GT 740M??? ?? ?? ??? ????.
?? ??? ? ??? ??? ???.
??? ????
?? ??? ???? ??? ???? ??? ????? ??? ??? ?? ? ????? ??? CUDA? <<<1, 1>>> ??? ????. ?? ?? ????? ??, CUDA ???? GPU?? ??? ? ??? ?? ??? ?? ?????. ???? ? ?? ????? ???, ?? ? ?? ????? ??? ??? ??? ?? ???? ??? ??? ?????. CUDA GPU? 32? ?? ??? ??? ??? ???? ??? ????? 256?? ???? ???? ?? ?????.
add<<<1, 256>>>(N, x, y);? ?? ??? ??? ??? ???? ?? ???? ?? ??? ???? ?? ???? ? ?? ??? ?????. ?? ??? ????? ??? ???? ???. CUDA C++? ??? ?? ?? ???? ???? ??? ? ?? ???? ?????. ????? threadIdx.x? ?? ?? ? ?? ???? ???? ????, blockDim.x? ?? ? ??? ?? ?????. ?? ???? ??? ????? ??? ???????.
__global__
void add(int n, float *x, float *y)
{
int index = threadIdx.x;
int stride = blockDim.x;
for (int i = index; i < n; i += stride)
y[i] = x[i] + y[i];
}add ??? ?? ???? ?????. ??? index?? 0?? ???? ?????(stride)? 1? ???? ? ?? ??? ????? ?????.
??? add_block.cu? ???? nvprof?? ?? ????? ?????. ? ?? ??? ????? ??? ?? ?? ????????.
Time(%) Time Calls Avg Min Max Name
100.00% 2.7107ms 1 2.7107ms 2.7107ms 2.7107ms add(int, float*, float*)?? ? ?? ??(463ms?? 2.7ms? ??)???, 1 ????? 256 ???? ???? ??? ??? ?? ????. K80? ? ?? ?? ?? GPU(3.2ms)?? ? ????. ? ?? ??? ?? ?? ???? ?????.
?? ???
CUDA GPU?? ???? ?????? ?? SM?? ???? ?? ?? ????? ????. ? SM? ?? ?? ?? ??? ??? ??? ? ????. ?? ??, ??? GPU ???? ??? Tesla P100 GPU?? 56?? SM? ???, ? SM? ?? 2048?? ?? ???? ??? ? ????. ? ?? ???? ??? ????? ?? ??? ???? ??? ???? ???.
?? ?? ??? ? ?? ????? ??? ??? ?? ????? ?? ????? ????. ?? ??? ??? ?? ????? ??? ?? ?????. ???? ? ??? N??? ??? ???? 256???? ?? N?? ???? ?? ?? ?? ?? ???? ???. N? ?? ??? ???? ?? ???(N? blockSize? ??? ?? ?? ???? ?????).
int blockSize = 256;
int numBlocks = (N + blockSize - 1) / blockSize;
add<<<numBlocks, blockSize>>>(N, x, y);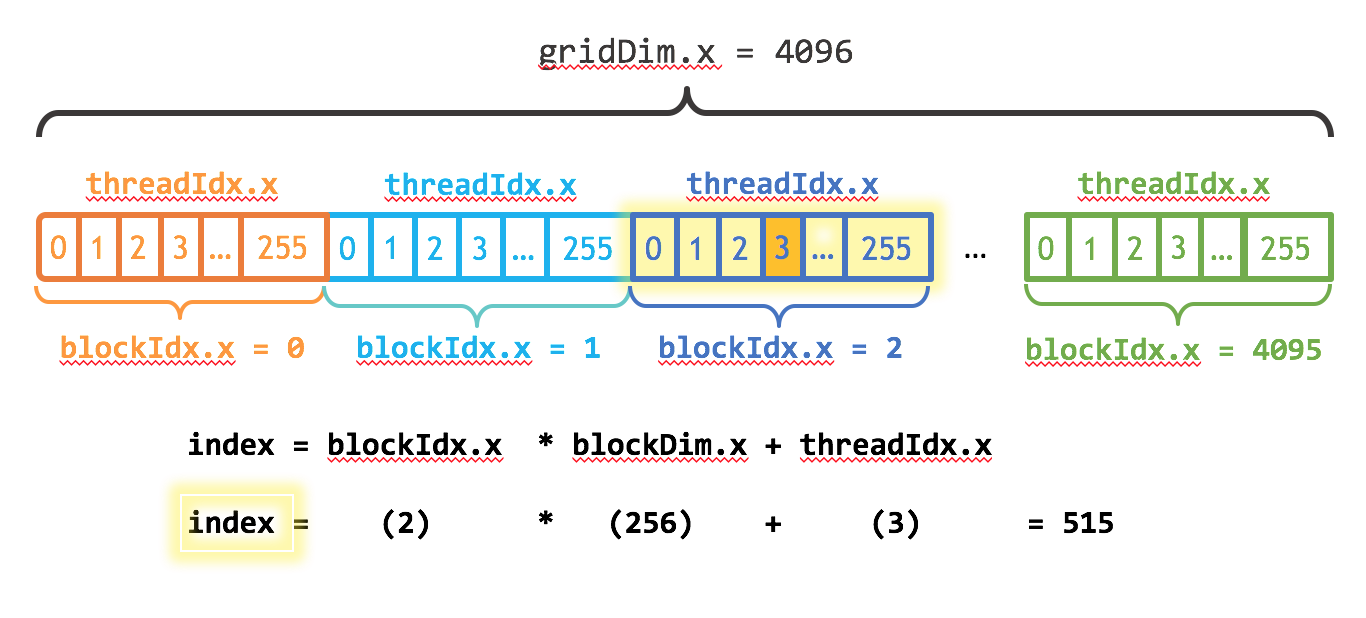
?? ??? ??? ?? ???? ????? ?? ??? ?????? ???. CUDA? ??? ? ?? ?? ???? gridDim.x? ??? ? ?? ??? ??? ???? ???? blockIdx.x? ?????. ?? 1? blockDim.x, gridDim.x ? threadIdx.x? ???? CUDA?? ??(1??)? ????? ??? ?????. ? ???? ??? ?? ??? ?? ???(?? ???? ?? ??: blockIdx.x * blockDim.x)? ???? ?? ??? ???? ???? ???(threadIdx.x) ??? ??? ???? ??? ????. blockIdx.x * blockDim.x + threadIdx.x ??? CUDA ??????.
__global__
void add(int n, float *x, float *y)
{
int index = blockIdx.x * blockDim.x + threadIdx.x;
int stride = blockDim.x * gridDim.x;
for (int i = index; i < n; i += stride)
y[i] = x[i] + y[i];
}????? ??? ?? stride? ???? ? ??? ?(blockDim.x * gridDim.x)? ?????. CUDA ???? ??? ??? ??? grid-stride loop?? ???? ???.
??? add_grid.cu? ???? nvprof?? ?? ????? ?????.
Time(%) Time Calls Avg Min Max Name
100.00% 94.015us 1 94.015us 94.015us 94.015us add(int, float*, float*)K80? ?? SM?? ?? ??? ???? ??? 28? ?????! ??? K80?? 2?? GPU ? ??? ???? ???, ? GPU?? 13?? SM? ????. ? ???? GeForce?? 2?? (? ??) SM? ??? ??? ???? ? 680us? ????? ?? ?????.
??
??? Tesla K80 ? GeForce GT 750M?? ? ?? ??? add() ??? ??? ??? ????.
| ??? (GeForce GT 750M) | ?? (Tesla K80) | |||
| ?? | ?? | ??? | ?? | ??? |
| 1 CUDA ??? | 411ms | 30.6 MB/s | 463ms | 27.2 MB/s |
| 1 CUDA ?? | 3.2ms | 3.9 GB/s | 463ms | 4.7 GB/s |
| ??? CUDA ?? | 3.2ms | 18.5 GB/s | 0.094ms | 134 GB/s |
?????, GPU?? ?? ?? ???? ??? ? ????. ? ?? ??? ???? ?? ????? GPU? ??? ?? ?? ??, ? ??, ??? ? ?? ??, ?? ????? ?? ?? ???? ?? ???? ?????.
?? ??
?? ??? ? ??? ?? ?? ? ?? ? ?? ?? ??? ?????. ?? ?? ??? ???? ??? ?????.
- CUDA ?? ???? ?????. ?? CUDA? ???? ???? ?? ?? ???? ?? ???? ?????. ?? ?? ????? ???? ?? ?? ???? ?????. ??? ????? ?? ?? ???? ????.
- ?? ???
printf()? ??? ???. ?? ?? ?? ???? ??threadIdx.x?blockIdx.x? ?? ??? ???. ???? ??? ?????? ? ?? ? ? ???? - ????
threadIdx.y??threadIdx.z(??blockIdx.y)? ?? ??? ???. (blockDim?gridDim? ???????). ? ?? ??? ?????? 0? ?? ?? ?? ????? ??? ?? ???(dim? ?? 1)? - ??? ?? GPU? ???? ? ?? ??
add_grid.cu? ??? ???. K80 ???? ??? ? ???, ????? ? ??? ?????? (??: ???? ??? ?????? ??? CUDA 8 ?? ??? API? ?? ?????.) ? ??? ?? ??? ??? CUDA ???? ?? ?? ??? ???? ?????.
?? ??
? ???? CUDA? ?? ??? ??????, ? ?? ?? ??? ??? ??? CUDA C++? ???? ? ??? ???? ????. ???? ??? ???? ?? ?? ??? ?? ???? ??? ??? ???.
? ???? ???? CUDA ????? ?? ??? ??? ?????, ???? ?? ?? ??? ???? ????? ???(?? ??? ?? ????/??? ?????):
- CUDA C++?? ?? ???? ???? ??
- CUDA C++?? ???? ??? ???? ??? ???? ??
- CUDA C++?? ??? ??? ????? ??
- CUDA C++?? ??? ??? ???? ??
- CUDA C++?? ??? ???? ????? ????? ??
- CUDA C++?? ?? ??? ????
- CUDA C++? ???? ?? ????
- CUDA C++? ?? ???, 1?
- CUDA C++? ?? ?? ??, 2?
- CUDA? ??? ??? ???? ?? ????
??, ?? ??? ??? CUDA Fortran ??? ???? CUDA Fortran? ?? ???? ?????.
Udacity? NVIDIA?? ???? CUDA ?????? ?? ??? ??? ???? ?? ????.
NVIDIA ??? ????? CUDA C++ ? ?? GPU ??? ??? ?? ??? ???? ??? ????? ????!
? ??? ????? ? ?? ?? ??? ????? NVIDIA DLI?? ?? ?? ???? CUDA ????? ??? ?????.
- ?? ? ???? ??? ?? ?? GPU ???, ?? ??? ????? ??, NVIDIA Nsight ??? ??? ????? ??, ?? ?? ??? ??, ??? ??????, 8?? ??? ??, DLI ??? ?? ??? ???? CUDA C/C++? ??? ?? ???? ??? ?????.
- ??? ?????? ?? CUDA ???? ??? ?? ???? ??? ?????.
- ? ?? ?? ? ?? CUDA ????? ??? NVIDIA DLI ?? ??? ????? ?? ??? ??? ?????.
?? ???
- DLI ??: ? ?? CUDA ??
- DLI ??: CUDA C/C++? ??? ?? ???? ??
- GTC ??: CUDA ???? ?? ??: ?? ???
- GTC ??: CUDA C++ ?????: CUDA C++ ?? ?????? ??? ?? ?? ??
- GTC ??: CUDA ????? ? ?? ??? ??
- NGC ????: CUDA





