
??? AI? ?? ???? ?? ??? ??? ????? ??? ??? ???? ???? ?? ?? ??? ????? ???? ????. ??? ??? ?? ??? ?????? ??????? ??? ??????.
??? ?? ??? ?? ????? ???? ??? ?? ??? ???? ??? ?? ???? ? ????. ?? ??? ????? ?? ??? ???? ?? ???? ??? ????? ??? ??? ?????.
NVIDIA TensorRT 9.2.0??? ??? ??? ????? NVIDIA ?????? ?? ?? ??? ?? ?? ? ??? ??? 8??(FP8 ?? INT8) ?? ? ???(PTQ)? ?? ?? ??? ??? ??? ??????. TensorRT? 8?? ??? ??? ?? ?????? ??? ?? ??????? ???? ???? ??? ???? ?? ??? AI ???? ???? ???? ?????.
? ?????? Stable Diffusion XL? ??? TensorRT? ??? ?? ?????. ?? ?? ??? ?? ???? ?? ??? ?? TensorRT? ??? ??? ? ? ?? ??? ??? ??? ?? ?????. ?????, ? ?? ????? ?? ??? ??? ?? TensorRT? ???? ??? ??????.
????
?? ??? ?? NVIDIA TensorRT INT8 ? FP8 ??? ???? FP16?? ???? ?? PyTorch? torch.compile? ???? NVIDIA RTX 6000 Ada GPU?? 1.72? ? 1.95?? ?? ??? ?????. INT8? ?? FP8? ???? ?? ??? ?? ?? ?? ??(MHA) ???? ??? ?????. TensorRT 8?? ???? ???? ??? AI ??????? ???? ????? ?? ??? ??? ? ????.
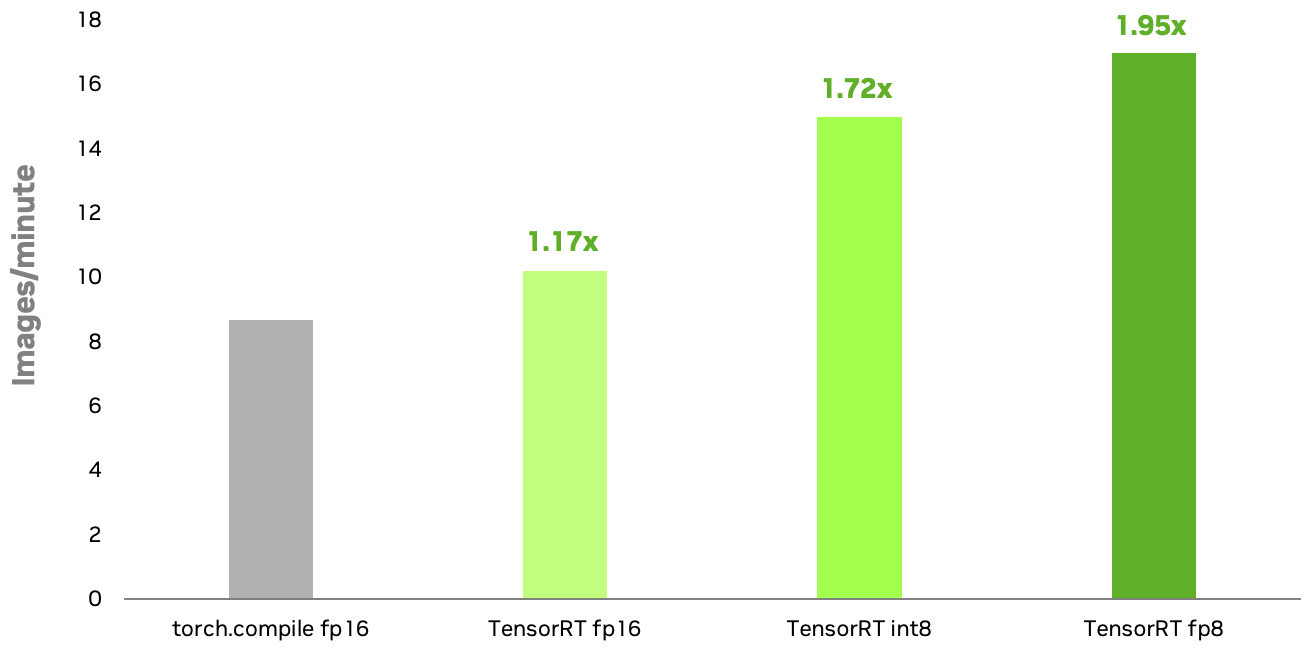
??????: Stable Diffusion XL 1.0 ?? ??, ??? ???=1024×1024, ?? ??=1, 50??? ??? ????, NVIDIA RTX 6000 Ada GPU. TensorRT INT8 ???? ?? ?? ????, FP8? ? ??? ?????. TensorRT FP8? ????? ?? ??? ??? ? ????.
?? ??? ??? ? ??? TensorRT 8?? ???? ??? ??? ???? ? ?????. ???? ??? ??? ?? ?? FP16 ???? ?? ??? ???? ?????. ??? ??? ? ?? ????? ????.

TensorRT ???: ?? ?? ?? ??
PTQ? ?? AI ???? ??? ??? ??? ?? ??? ??? ?? ?? ???? ?????, ?? ???? ?? ??? ? ?? ?? ????. ?? ???? ??? ??? ??? ?? ????? ??? ? ?? ???? ??? ?? ????? ?? ??? ?? ??? ? ????. ??? ??? PTQ ?? ??? ???? ?????.
?? ???? SmoothQuant? LLM? 8?? ???, 8?? ???(W8A8) ???? ???? ?? ?? ?? PTQ ???? ???? ????. ? ??? ?? ??? ????? ??? ??? ?? ??? ??? ????? ???? ?????? ??? ???? ???? ?? ??? ????.
??? ???? ???? ????? SmoothQuant ??? ????? ???? ???? ? ???? ?? ??? ????. ?? ??? ??? ??? SmoothQuant? ??? ??? ??? ???? ? ???? ??? ?? ?????? ???? ??? ???? ??? ??????. ?? ??? ?? ?? ?? ??? ??? ?? ??? ?? ???? ???? ??, ???? ??? ??? ?? ??? ?? ? ?? ???? ?? ??? ?? ????.
??? ??? ???? ?? NVIDIA TensorRT? ???? ???? ?? ?????? ???? SmoothQuant? ? ?? ???? ?? ??? ???? ??? ?????. ?? ?? ?? ??? ?? ?? ?? ?????? ??? ? ????. ? ??? ???? ??? ??? ?? ?? ??? ?? ?? ???? ??? ???? ???? ??? ??? ??? ?? ? ?? TensorRT ???? ??? ? ????.
??? ??? ?? ??? ?? ?? ??? ? ???, ???? ??? ???? ???? ?? ??? ?? ????? ?? ???? Q-Diffusion? ??? ?? ?????. ??? ??? ?? ??? ???? ?? ???? ? ??? ??? ?????.
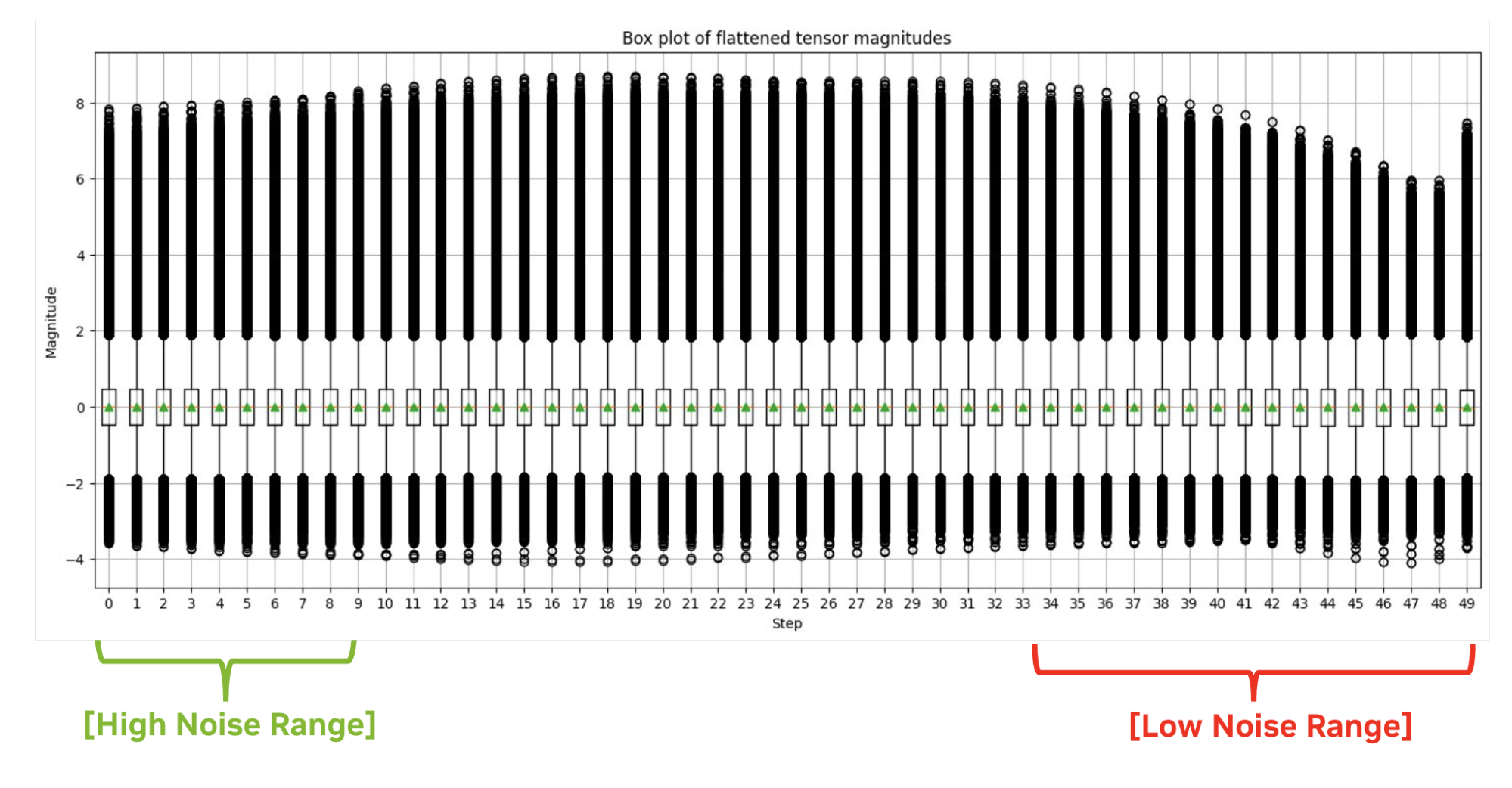
?? ??? ?? ???? ?? ??? ???? ??? ????? ?????, ?? ???? ???? ?? ??? ??? ??? ???? ??? ??? ???? ?????. ???? ??(Percentile Quant)?? ?? ?? ? ??? ?? ??? ?? ??? ??? ????? ??? ????. ?? ?? TensorRT? ?? FP16 ???? ??? ???? ?? ??? ???? ??? ? ????.

?? ?? ???? ?? TensorRT 8?? ??? ??
?? /NVIDIA/TensorRT GitHub ?????? ?????, SDXL, 8?? ?? ?????? ????? NVIDIA GPU?? ???? ?? ??? ???? ?? ?? ??? ? ?? ???? ?????.
?? ??? ???? ???? ??? ???? ???? ?????? ?? ??? ?????. ? ????? INT8? ?? ?????, FP8? ?????? ?? ?????.
python demo_txt2img_xl.py "enchanted winter forest with soft diffuse light on a snow-filled day" --version xl-1.0 --onnx-dir onnx-sdxl --engine-dir engine-sdxl --int8 --quantization-level 3??? ? ??? ??? ?? ??? ?? ?????:
- ??
- ONNX ????
- TensorRT ?? ??
??????
??? ??? ? ?? ???? ??? ???? ?????. ?? TensorRT? ??? ??? TensorRT 8?? ??? ??? ??? ???? nvidia-ammo? ????? ????.
# Load the SDXL-1.0 base model from HuggingFace
import torch
from diffusers import DiffusionPipeline
base = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
torch_dtype=torch.float16,
variant="fp16",
use_safetensors=True
)
base.to("cuda")
# Load calibration prompts:
from utils import load_calib_prompts
cali_prompts = load_calib_prompts(batch_size=2,prompts="./calib_prompts.txt")
# Create the int8 quantization recipe
from utils import get_percentilequant_config
quant_config = get_percentilequant_config(base.unet, quant_level=3.0, percentile=1.0, alpha=0.8)
# Apply the quantization recipe and run calibration
import ammo.torch.quantization as atq
quantized_model = atq.quantize(base.unet, quant_config, forward_loop)
# Save the quantized model
import ammo.torch.opt as ato
ato.save(quantized_model, 'base.unet.int8.pt')ONNX ????
???? ?? ?????? ?? ? ONNX ??? ??? ? ????.
# Prepare the onnx export
from utils import filter_func, quantize_lvl
base.unet = ato.restore(base.unet, 'base.unet.int8.pt')
quantize_lvl(base.unet, quant_level=3.0)
atq.disable_quantizer(base.unet, filter_func) # `filter_func` is used to exclude layers you don't quantize
# Export the ONNX model
from onnx_utils import ammo_export_sd
base.unet.to(torch.float32).to("cpu")
ammo_export_sd(base, 'onnx_dir', 'stabilityai/stable-diffusion-xl-base-1.0')TensorRT ?? ??
INT8 UNet ONNX ??? ???? TensorRT ??? ??? ? ????.
??
??? AI ???? ?? ???? ????? ?? ???? ??? ?? ???? ?????. NVIDIA TensorRT? ???? ???? 8?? ??? ??? ?? ?? ??? ?? 2??? ???? ????? ??? ??? ??? ??? ?? ??? ??? ????? ?? ??? ? ????.
??? ?? ??? ??? ??? ?? TensorRT? ??? AI ?????? ???? ?? ???? ???? ?????? ??? ???? ??? ??? ? ??? ?????.
??? ?? GTC ??? ???? ??? ????? ??? AI ??? ?? ??? ?? ??? ????? ??? ?? ??? ?????. ??????? LLM? ???? ?? ??, TensorRT-LLM? ??? SOTA ??? ???? ?? ??? ??? ??? ???? ?? ????.
??? ??? ?? ???? ?????:
- NVIDIA GTC 2024? LLM? ?? ??? ?? ??
- ?? ??? ?? ??? ????? NVIDIA TensorRT-LLM
- TensorRT SDK
- /NVIDIA/TensorRT-LLM GitHub ?????





