NVIDIA NeMo Customizer for Developers
NVIDIA NeMo? Customizer is a high-performance, scalable microservice that simplifies fine-tuning and alignment of generative AI models for domain-specific use cases. The microservice supports popular customization techniques such as low-rank adaptation (LoRA), p-tuning, and supervised fine-tuning (SFT), with continued integration of the latest customization techniques.
NeMo Customizer, along with the other NeMo microservices, enables developers to create data flywheels that continuously optimize generative AI agents, enhancing the overall experience for end users.
See NVIDIA NeMo Customizer in Action
Learn how NeMo Customizer, along with NeMo Evaluator and NeMo Guardrails, enables developers to build custom AI agents.
How NVIDIA NeMo Customizer Works
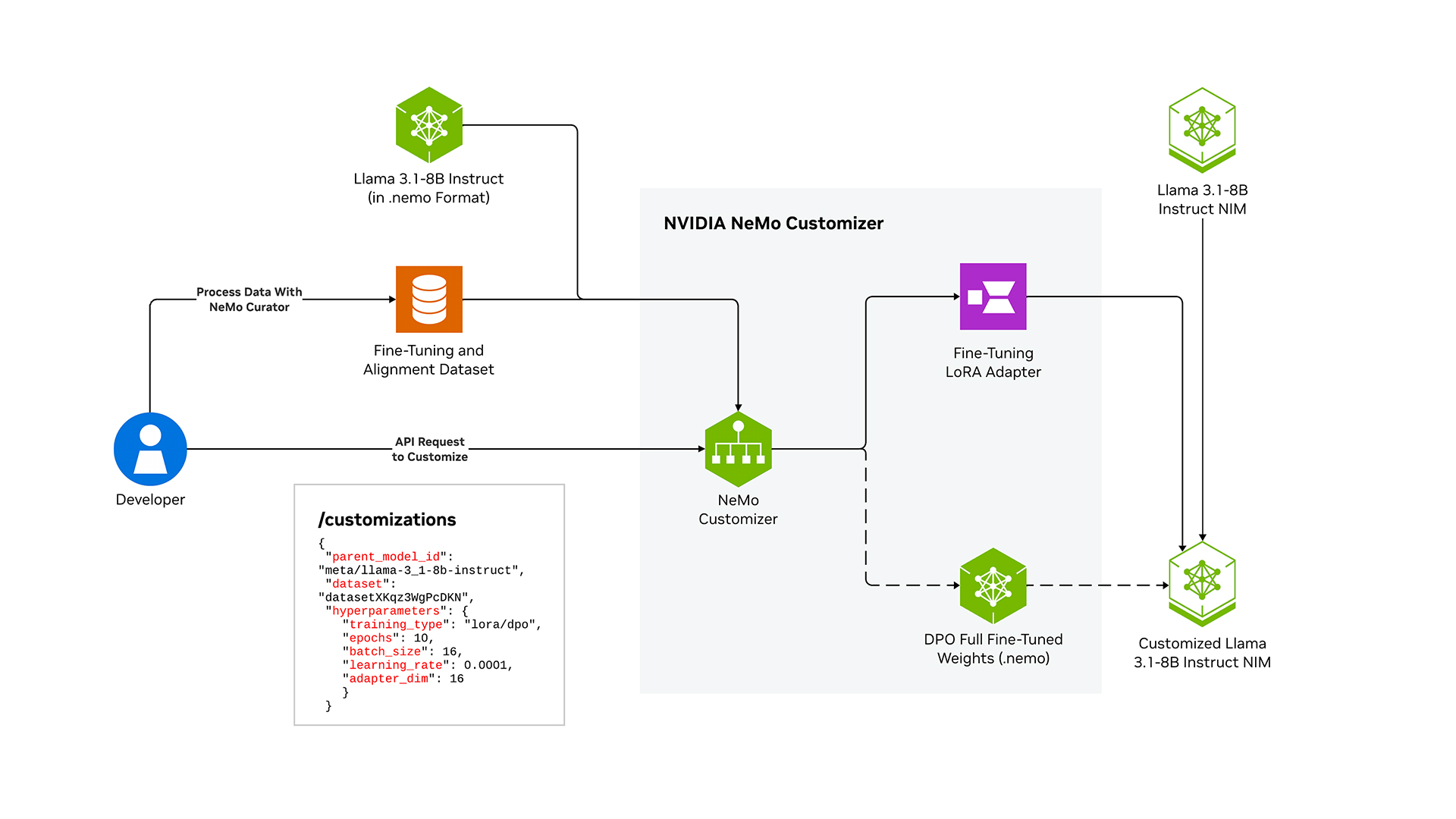
NeMo Customizer provides an easy-to-use API that lets you customize generative AI models. Simply provide the dataset, model name, hyperparameters, and type of customization in the API payload. NeMo Customizer will initiate a job to tune the model, resulting in a customized version for you.
The architecture diagram below illustrates the flow for using NeMo Customizer letting you seamlessly launch multiple customization jobs. In the depicted scenario, you can utilize the NVIDIA NeMo Curator to gather high-quality data and NeMo Customizer to create two customization workflows: one for fine-tuning and one for alignment tuning. These outputs, along with NVIDIA NIM?, allow you to deploy a customized model tailored to your specific use case.
Introductory Blog
Read how NeMo Customizer simplifies the alignment and customization of generative AI models.
Tutorials
Explore tutorials designed to help you build custom generative AI models with the NeMo Customizer microservice.
GTC Session
Understand how NeMo Customizer, along with other NeMo microservices, facilitates the customization of generative AI models and supports ongoing performance evaluation, ensuring models remain relevant and effective over time.
How-To Blog
Dive deeper into how NVIDIA NeMo microservices help build data flywheels with a case study and a quick overview of the steps in an end-to-end pipeline.
Ways to Get Started With NVIDIA NeMo Customizer
Use the right tools and technologies to simplify fine-tuning and alignment of large language models (LLMs) for domain-specific use cases.
Develop
Get free access to the NeMo Customizer microservice for research, development, and testing.
Download NowDeploy
Get a free license to try NVIDIA AI Enterprise in production for 90 days using your existing infrastructure.
Request a 90-Day LicensePerformance
NeMo Customizer uses several parallelism techniques to reduce the training time for large models with support for multi-GPU and multi-node infrastructure. These methods operate together to enhance the training process, ensuring optimal use of resources and improved training performance.
Experience 1.8x Faster Customization With NeMo Customizer

The benchmark represents customizing Llama-3-8B on one 8xH100 80G SXM with sequence packing (4096 pack size, 0.9958 packing efficiency).
On: customized with NeMo Customizer.
Off: customized with leading market alternatives.
Starter Kits
Start tuning your generative AI models with NeMo Customizer by accessing tutorials, best practices, and documentation for various use cases.
Customizing LLMs
Get started with popular customization techniques, such as LoRA, SFT, and p-tuning.
NVIDIA NeMo Customizer Learning Library
More Resources


Ethical AI
NVIDIA’s platforms and application frameworks enable developers to build a wide array of AI applications. Consider potential algorithmic bias when choosing or creating the models being deployed. Work with the model’s developer to ensure that it meets the requirements for the relevant industry and use case; that the necessary instruction and documentation are provided to understand error rates, confidence intervals, and results; and that the model is being used under the conditions and in the manner intended.