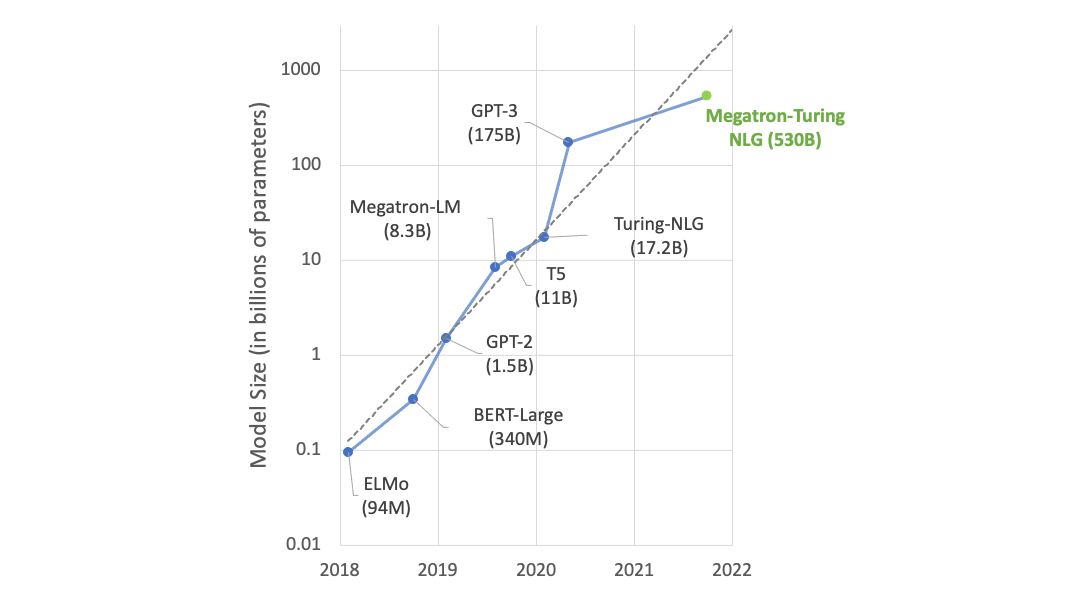
背景
在 MoE 模型的訓練過程中,EP rank 之間的 A2A 通信在端到端時間中占據了相當大比重,對訓練效率影響很大,特別是對于 Fine-grained MoE model,EP size 會比較大,跨機通信基本無法避免。那么要如何減少 EP A2A 對整體訓練效率的影響呢?
- 首先是盡可能提升 EP A2A 通信本身的效率。DeepSeek 開源的 DeepEP 通信庫通過將通信拆分為機內通信和機間通信,并將二者進行 overlap, 實現了很高的通信效率。這一工作已經集成到 NVIDIA Megatron-LM 中;
- 其次是讓 EP A2A通信盡可能和計算 overlap,用計算來掩蓋通信的時間。本文從這個主題出發,介紹我們如何基于 1F1B 的流水線機制來實現 EP A2A 與計算的 overlap。
用計算掩蓋 EP A2A 通信的相關研究
關于如何用計算掩蓋 EP A2A 通信,我們注意到目前有以下這些研究(不完全統計):
1, micro batch 內 overlap
- EP A2A 和 expert mlp overlap (minimax-01 方案、faster moe 方案、 tutel 方案);
- 將 Attention + MLP 整體分成多個 block,block 間的 EP A2A 和計算 overlap (AMPipe)。
2, micro batch 間 overlap
- DeepSeek V3 論文提出了一種新的流水線并行算法:DualPipe。實現了在兩個 micro batch forward 和 backward 之間的 EP A2A 通信與計算 overlap。
以上方案有各自的不足之處:
- EP A2A 和 expert mlp overlap: 其效果比較好的前提是計算時間要大于通信時間,但對于跨機 A2A 的情況,A2A 的通信可能會大于 expert mlp 計算時間,DeepSeek V3 論文中提到訓練過程中 EP A2A 的整體耗時占比大約是 50%,此時這一方案的 overlap 效果就大打折扣了;
- Attention + MLP 整體分成多個 block 方案:需要分塊 attention, 支持起來比較麻煩,而且分了 block 可能會降低計算效率,另外這個方案可能和其他分布式并行策略有沖突,比如 CP;
- DeepSeek DualPipe:毋庸置疑是很優秀的工作,但是調度邏輯比較復雜,難以理解與 debug,另外需要對現有的分布式訓練框架(如 Megatron-LM)進行大范圍的重構才能接入。
我們分析認為, Deepseek DualPipe 調度核心亮點是實現了 batch 之間 EP A2A 通信和 attention 、mlp 計算 overlap 的精細化調度, 從而使得跨機 EP 成為可行的分布式策略。
Dualpipe 起到的主要作用是創造了 overlap 的機會, 從這個角度而言,基于 1F1B 的調度也能做到 batch 之間 forward 和 backward 之間的 EP A2A 通信與計算的 overlap。
基于 1F1B 的 MoE A2A 通信計算 overlap
Conventional 1F1B
可以很自然地想到,通過調整 1F1B 調度來實現 1F1B 調度中穩態階段 f 和 b 的 EP A2A 通信與計算 overlap。
原始的 1F1B 調度,最后一個 pp stage 穩態階段的 f 和 b 之間存在數據依賴,無法實現 f 和 b 之間的 EP A2A 通信與計算 overlap。 為了解決這個問題, 我們可以把最后一個 pp stage 的 warmup step 加 1。同時,考慮到 pp stage 間前反向的數據依賴,其他 pp stage 也需要調整 warmup step。
具體的調度方式如下:
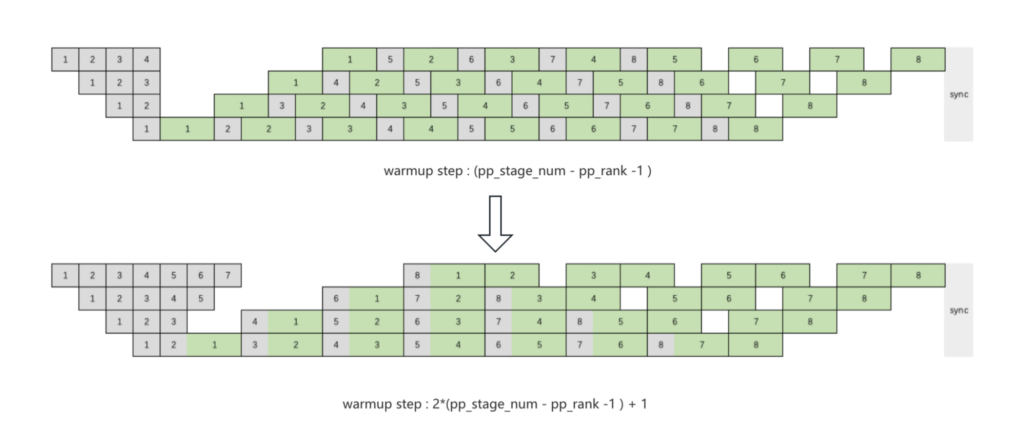
圖 1: 1F1B 調度下 A2A 基于傳統 1F1B 方案實現相鄰 micro batch 間計算和通信的 overlap。
該圖片來源于小紅書 Agi Infra 團隊,若您有任何疑問或需要使用該圖片,請聯系小紅書
我們得到了一個 1F1B 通信計算 overlap 的初步方案,但是這個方案有很大的缺陷:因為 pipeline parallel rank 之間存在數據依賴,warmup step 過大,activation 顯存占用過大。
Interleaved 1F1B
我們轉向考慮 interleaved 1F1B ,沿用上面調整 warmup step 的邏輯,驚喜地發現,通過將穩態的 1F1B stage 中第一個 micro batch 的 fprop 提前到 warmup stage,即 warmup step + 1, 就可以在 interleaved 1F1B 實現 1F1B 穩態階段不同 micro batch 前反向之間的 EP A2A 與計算的 overlap。
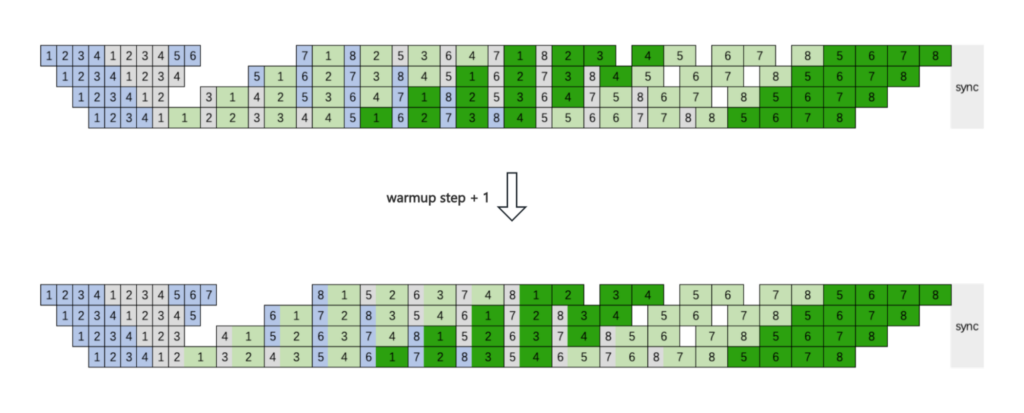
圖 2: 基于 interleaved 1F1B 方案實現相鄰 micro batch 間計算和通信的 overlap。
該圖片來源于小紅書 Agi Infra 團隊,若您有任何疑問或需要使用該圖片,請聯系小紅書
相比于原始的 interleaved 1F1B, 我們的這個方案雖然在 warmup stage 增加了一個 micro batch 的前向計算,但是 1F1B 階段的調度是前反向細粒度地交疊調度,F 在增加 activation 顯存的同時,B 會釋放 activation 顯存,使得峰值顯存基本沒有變化;Bubble rate 和原始的 interleaved 1F1B 完全一致。
因此我們最終選擇使用 interleaved 1F1B with A2A overlap 方案。
Fine-grained schedule of 1F1B overlap
具體來說,對于兩個 micro batch 之間 forward 與 backward 的 EP A2A 通信/計算 overlap, 我們采用了類似 DualPipe 的方案, 拆分了 dw。我們認為這是很有必要的。如果計算與通信 1:1, 那就意味著前向的計算比通信少, 反向的計算比通信多,前向的計算不足以 overlap 反向的通信, 需要用 dw 來 overlap 部分反向通信。
我們通過下面一組流程圖來對比說明 dw 拆分的必要性。Baseline 版本將 forward 和 backward 的計算部分放到了同一個 stream 中,通信部分放到了另一個 stream 中,通過將 forward 和 backward 的各個模塊交錯排布,消除了同一時刻計算流和通信流上 kernel 的數據依賴,從而實現了 batch 間的 EP A2A 和計算的 overlap。
但如果 EP A2A 的時間比較長,超過了計算時間,比如下圖里的 F/attn 和 F/mlp,此時 EP A2A 通信還是會暴露出來。這時我們可以把 mlp 和 attention 的 dw 從 backward 計算中拆分出來, 那么 B/dispatch 和 B/combine 的執行就可以提前,因為 B/dispatch 和 B/combine 只依賴 dx 的結果。這樣用來 overlap B/dispatch 的計算除了 F/mlp 之外還有 W/mlp 的一部分,從下面兩種方案的對比我們也可以看出,拆分 dw 之后,計算流上 kernel 的排布更加緊密,整體的執行時間也要比 Baseline 快。
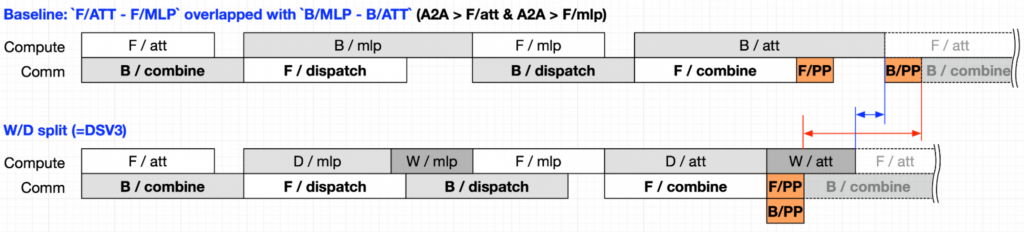
圖 3: 拆分 dw 前后,計算和通信 overlap 示意圖。
該圖片來源于NVIDIA,若您有任何疑問或需要使用該圖片,請聯系NVIDIA
與 Deepseek DualPipe 對比
| DualPipe | 1F1B with A2A overlap | |
| PP bubble overhead | (PP/2-1) x (F&B + B -3W) | (PP – 1) x (F + B) / vpp |
| Memory: param | 2X | 1X |
| Memory: activation | PP+1 | PP+(PP-1)/vpp |
注:F – forward chunk time, B – full backward chunk time, W – “backward for weight” chunk, F&B – two mutually overlapped forward and backward chunks.
為了更好地對比兩種方案的 bubble overhead,接下來我們對 F/B/W 的時間做一個合理的假設(參考圖三):B=2F=2W,F&B 的耗時比較難以給出較準確的估計,我們合理地認為 F&B=B,即前向傳播的時間完全被反向傳播掩蓋住,這種估計的合理性在于:
- 在拆分 dw 之前,反向傳播的計算和通信時間都大于與其 overlap 的前向計算的時間;拆分 dw 之后,dw 的計算時間可以進一步被 overlap;
- 計算和通信的 overlap 在相當程度上會對計算 kernel 產生 overhead;
| DualPipe | 1F1B with A2A overlap | |
| PP bubble | (PP/2-1) x F | 3 x (PP-1) / vpp x F |
據以上公式,我們可以估算出兩種方案 bubble overhead 的比例:
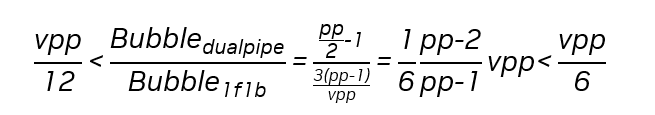
可以看出,vpp=8 大致是兩種方案的 bubble overhead 比值的分界點,我們從一些常見模型的最佳配置里抽離出 vpp 的設置如下:
| Model | PP | VPP |
| GPT-175B | 8 | 8 |
| llama3-70B | 4 | 5 |
| llama3-405B | 9 | 7 |
| Nemotron-22B* | 4 | 10 |
| Nemotron-340B* | 8 | 12 |
| Mixtral-8x7B | 4 | 8 |
| Mixtral-8x22B | 4 | 14 |
| QWen* | 4 | 7 |
注:* 該模型的最佳配置為內部測試結果,訓練腳本尚未開源
因此,多數情況下兩種方案的 bubble overhead 是比較接近的。另外大多數情況下 micro batch 的數量比較多,PP bubble 在端到端的耗時占比處于比較低的水平,此時 PP bubble 對整體的性能影響比較有限。
關于 PP bubble 帶來的 Activation memory 開銷,從上面常見模型的最優配置可以看出,PP size 通常小于 VPP,此時 1F1B with A2A overlap 方案的 Activation memory 開銷要低于 DualPipe。
總結
針對 MoE 模型訓練過程中 EP A2A 通信占比過高的問題,我們分析了現有的優化策略,認為 在 batch 間進行通信計算 overlap 是比較高效的實現方案。參考 DeepSeek 提出的 DualPipe,我們設計了一種基于現有的 interleaved 1F1B 策略實現 batch 間計算通信 overlap 的方案,該方案具有以下幾個特點:
- 基于現有的 1F1B 方案實現了和 DualPipe 相似的 batch 間 EP A2A 與計算 overlap 的效果;
- 與 DualPipe 相比, Interleaved 1F1B 大多數情況下展現出較接近的 bubble overhead。另外大多數訓練場景下,micro batch 的數量都比較多,此時這兩種方案下 bubble rate 在端到端訓練中的耗時占比都非常低;
- 不需要存儲一份額外的模型參數;
- 能很好地兼容 NVIDIA Megatron-Core 現有的代碼結構和分布式策略;
NVIDIA 技術團隊正與小紅書技術團隊一起將該優化方案實現到 Megatron-Core 中。目前,前期的 PoC 驗證和 Design 已完成,預計 3 月中下旬可提供 EA 版本供試用。