由于時間序列數據固有的復雜性和不可預測性,對其建模可能具有挑戰性(也很有吸引力)。例如,時間序列中的長期趨勢可能會因某些事件而發生劇烈變化。回想一下全球疫情開始時,航空公司或實體店等企業的客戶數量和銷售額迅速下降。相比之下,電子商務業務繼續運營,中斷較少。
交互項可以幫助建模這種模式。它們能捕捉變量之間的復雜關系,從而產生更準確的預測。
這篇文章探討:
- 時間序列預測中的交互項
- 建模復雜關系時交互術語的好處
- 如何在模型中有效地實現交互術語
交互術語概述
交互術語可以幫助您探究目標和功能之間的關系是否會隨著另一個功能的值的變化而變化。想要了解更多詳細信息,請參閱我之前的文章,線性回歸中交互術語的全面指南。
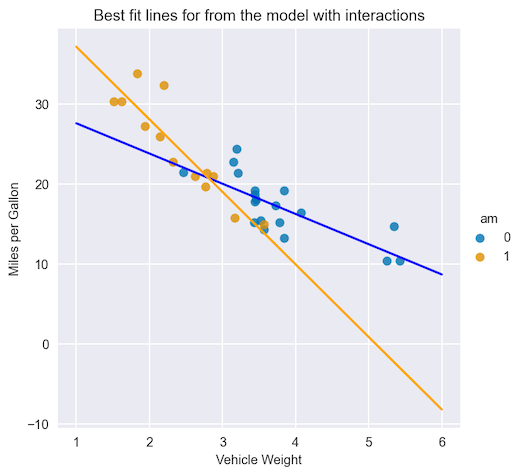
圖 1 顯示了一個散點圖,表示每加侖英里數(目標)和車輛重量(特征)之間的關系。根據變速器類型(另一個特征)的不同,這種關系會大不相同。
提高線性模型精度
如果不使用交互項,線性模型將無法捕捉到如此復雜的關系。實際上,無論傳輸類型如何,它都會為權重特征分配相同的系數。圖 1 顯示了按權重特征劃分的系數(線的斜率),不同傳輸類型的系數有很大不同。
為了克服這種謬論并使線性模型更加靈活,可以添加交互項。一般來說,它們是原始特征的乘積。通過將這些新變量添加到回歸模型中,可以測量它們與目標之間相互作用的效果。
時間序列預測中的交互項
交互項使線性模型更加靈活。以下示例顯示了它們在時間序列預測中的工作方式。
先決條件
首先,加載所需的庫:
import numpy as np
import pandas as pd
from sklearn.linear_model import LinearRegression
import seaborn as sns
import matplotlib.pyplot as plt
數據集生成
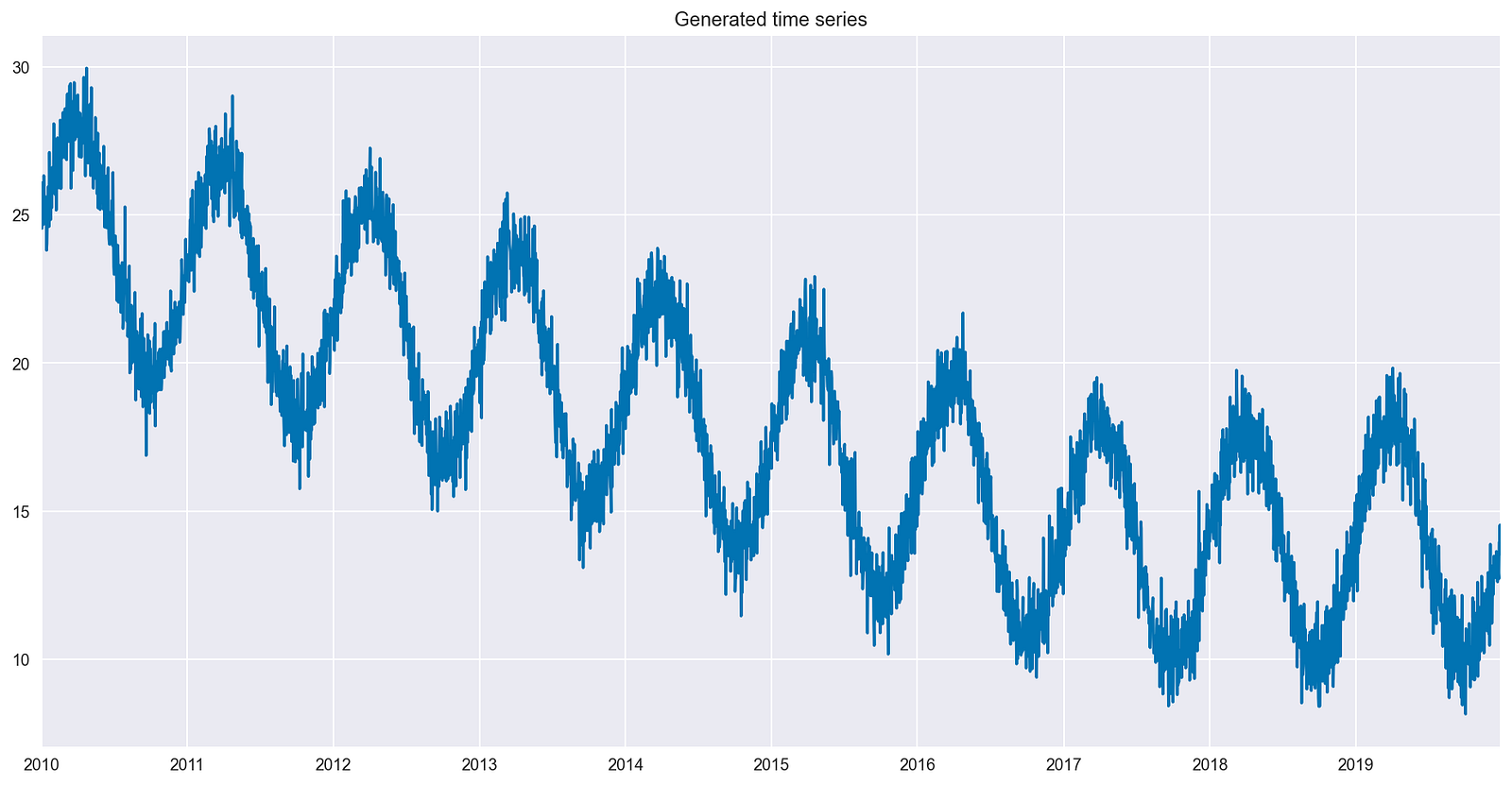
然后,生成一些具有以下特征的人工時間序列數據:
- 10 年的日常數據
- 時間序列中存在的重復模式(季節性)
- 前 7 年呈下降趨勢
- 過去 3 年無趨勢
- 隨機噪聲,作為最后一步添加
# for reproducibility
np.random.seed(42)
# generate the DataFrame with dates
range_of_dates = pd.date_range(
start="2010-01-01",
end="2019-12-30"
)
df = pd.DataFrame(index=range_of_dates)
# create a sequence of day numbers
df["linear_trend"] = range(len(df))
df["trend"] = 0.004 * df["linear_trend"].values[::-1]
df.loc["2017-01-01":, "trend"] = 4
# generate the components of the target
signal_1 = 10 + 4 * np.sin(df["linear_trend"] / 365 * 2 * np.pi)
noise = np.random.normal(0, 0.85, len(df))
# combine them to get the target series
df["target"] = signal_1 + noise + df["trend"]
# plot
df["target"].plot(title="Generated time series");
圖 2 顯示了生成的時間序列,其中包括所有所需的特性。
培訓基準模
現在訓練一個線性模型并檢查最佳擬合線。對于這一步,創建具有一些功能的非常簡單的模型。這使您能夠直觀地檢查交互項對模型擬合的影響。
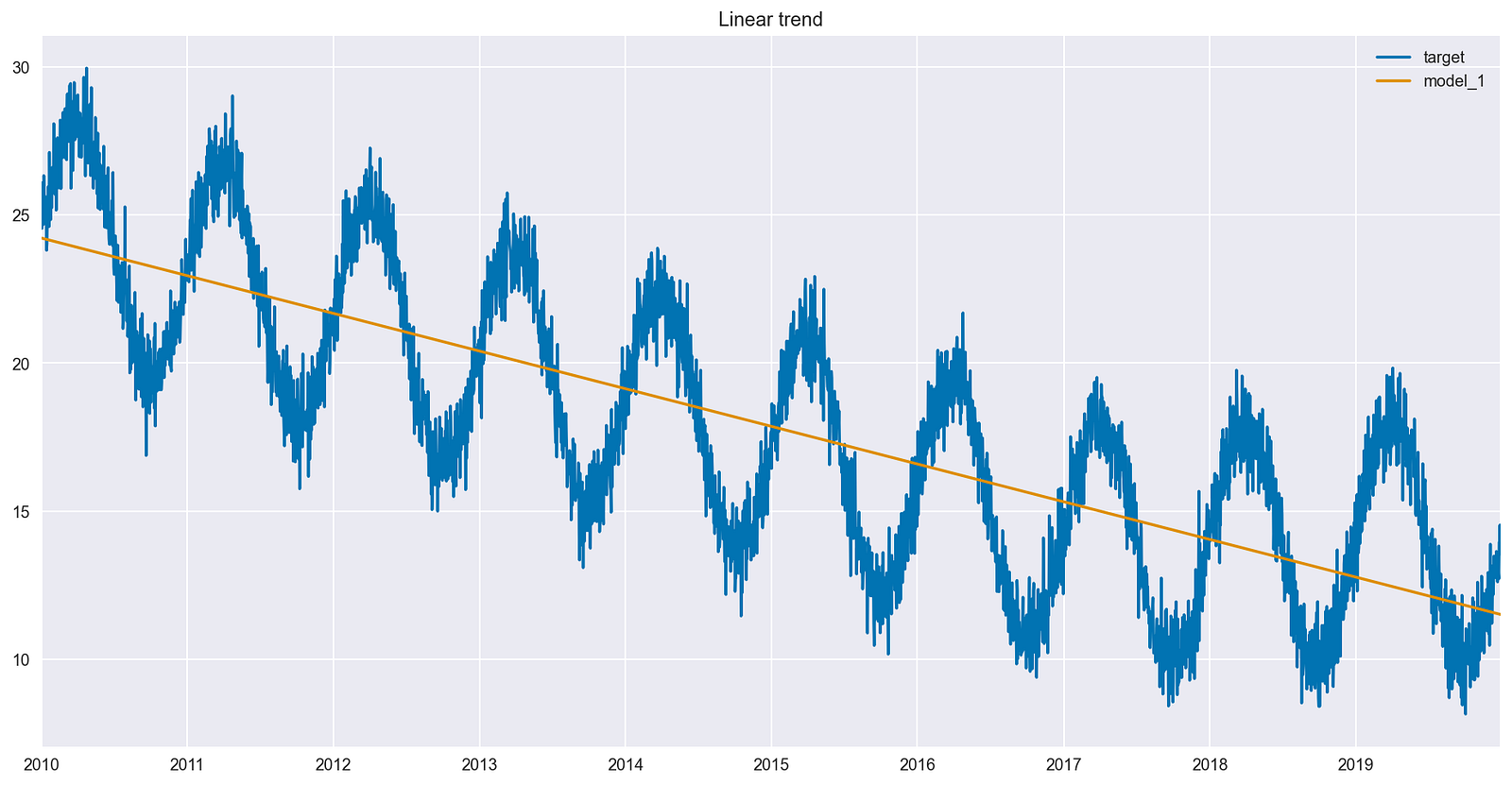
最簡單的模型可能包含一個特性 — 時間流逝的指示器。這個linear_trend為時間序列創建的列實際上是 DataFrame 的行號(按日期排序)。
X = df[["linear_trend"]]
y = df[["target"]]
lm = LinearRegression()
lm.fit(X, y)
df["model_1"] = lm.predict(X)
df[["target", "model_1"]].plot(title="Linear trend");
值得一提的是,重點不是使用單獨的訓練集和測試集來正確評估預測,而是解釋交互項對模型擬合的影響。通過檢查擬合值(對訓練集的預測)并將這些擬合值與原始時間序列進行比較,更容易觀察交互項的影響。
圖 3 顯示,線性模型確定了整個時間序列的下降趨勢。與此同時,過去 3 年的數據似乎不符合,因為沒有趨勢。
添加斷點
接下來,嘗試使用特征工程使模型學習新模式(趨勢變化)。為此,請創建一個斷點,它是一個占位符變量,指示給定的觀測值是否在 2017 年 1 月 1 日之后。在這種情況下,趨勢變化發生的確切時間點是已知的。
接下來,訓練另一個線性模型,這次有兩個功能:
df["after_2017_breakpoint"] = np.where(df.index >= pd.Timestamp('2017-01-01'), 1, 0)
X = df[["linear_trend", "after_2017_breakpoint"]]
y = df[["target"]]
lm = LinearRegression()
lm.fit(X, y)
df["model_2"] = lm.predict(X)
df[["target", "model_2"]].plot(title="Linear trend + breakpoint");
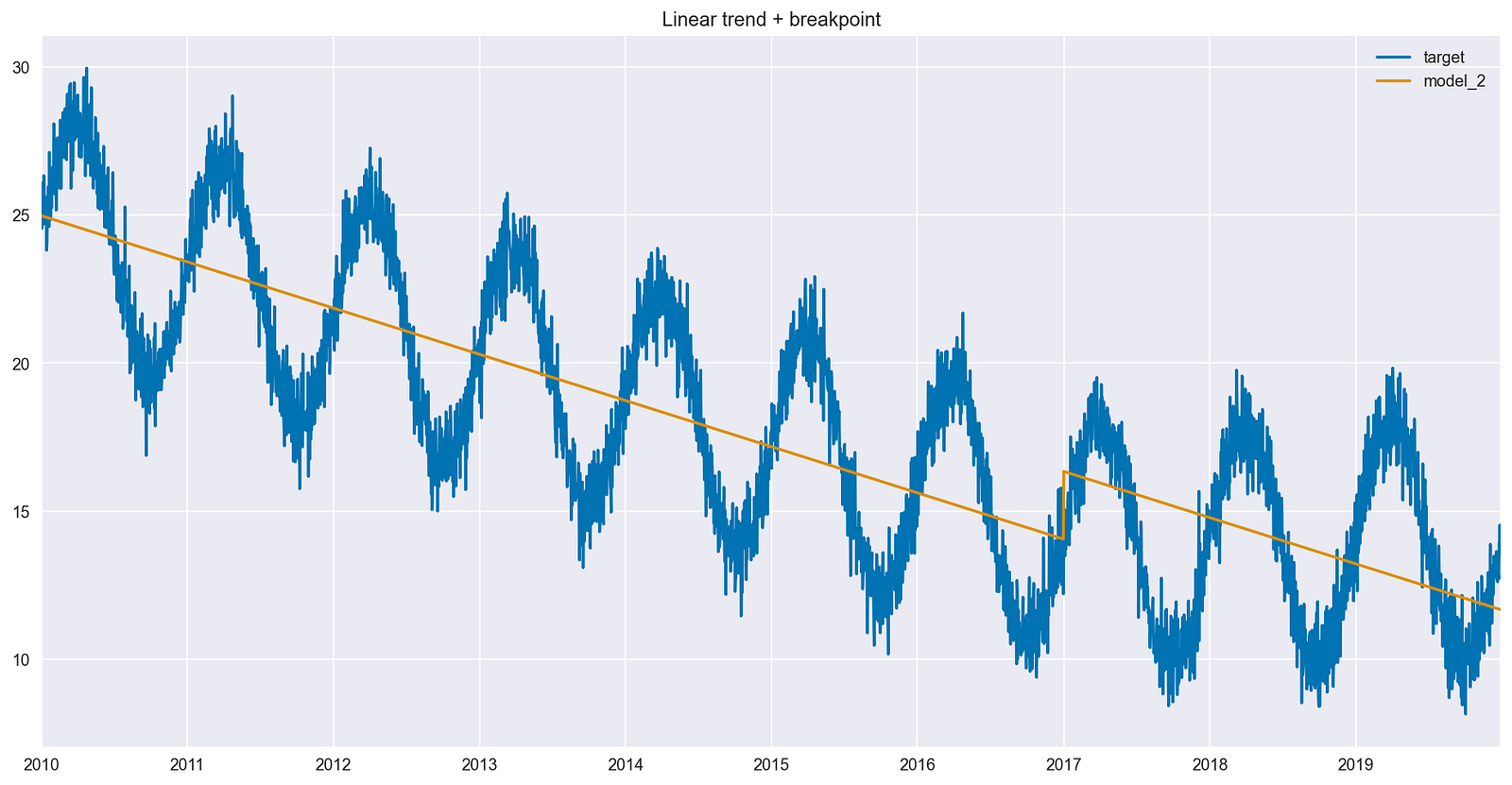
圖 4 顯示了一些重要的變化,如下所示:
- 擬合線顯示垂直跳躍,該跳躍對應于新布爾特征的系數。
- 垂直跳躍恰好發生在功能激活的第一個日期(值為 1 而不是 0 )。
- 在引入斷點之前和之后,直線的斜率是相同的。
- 該模型試圖通過在斷點后的預測中添加固定的量來補償不正確的斜率。
在過去 3 年的數據中沒有趨勢,因此理想情況下, 2017 年 1 月 1 日之后,該線應接近持平。
添加交互項
要更改斷點后的斜率,請添加一個更復雜的時間戳依賴項(用線性趨勢表示)。這正是交互項的作用——它是線性趨勢和占位符變量的乘積。
df["interaction_term"] = df["after_2017_breakpoint"] * df["linear_trend"]
X = df[["linear_trend", "after_2017_breakpoint", "interaction_term"]]
y = df[["target"]]
lm = LinearRegression()
lm.fit(X, y)
df["model_3"] = lm.predict(X)
df[["target", "model_3"]].plot(title="Linear trend + breakpoint + interaction term");
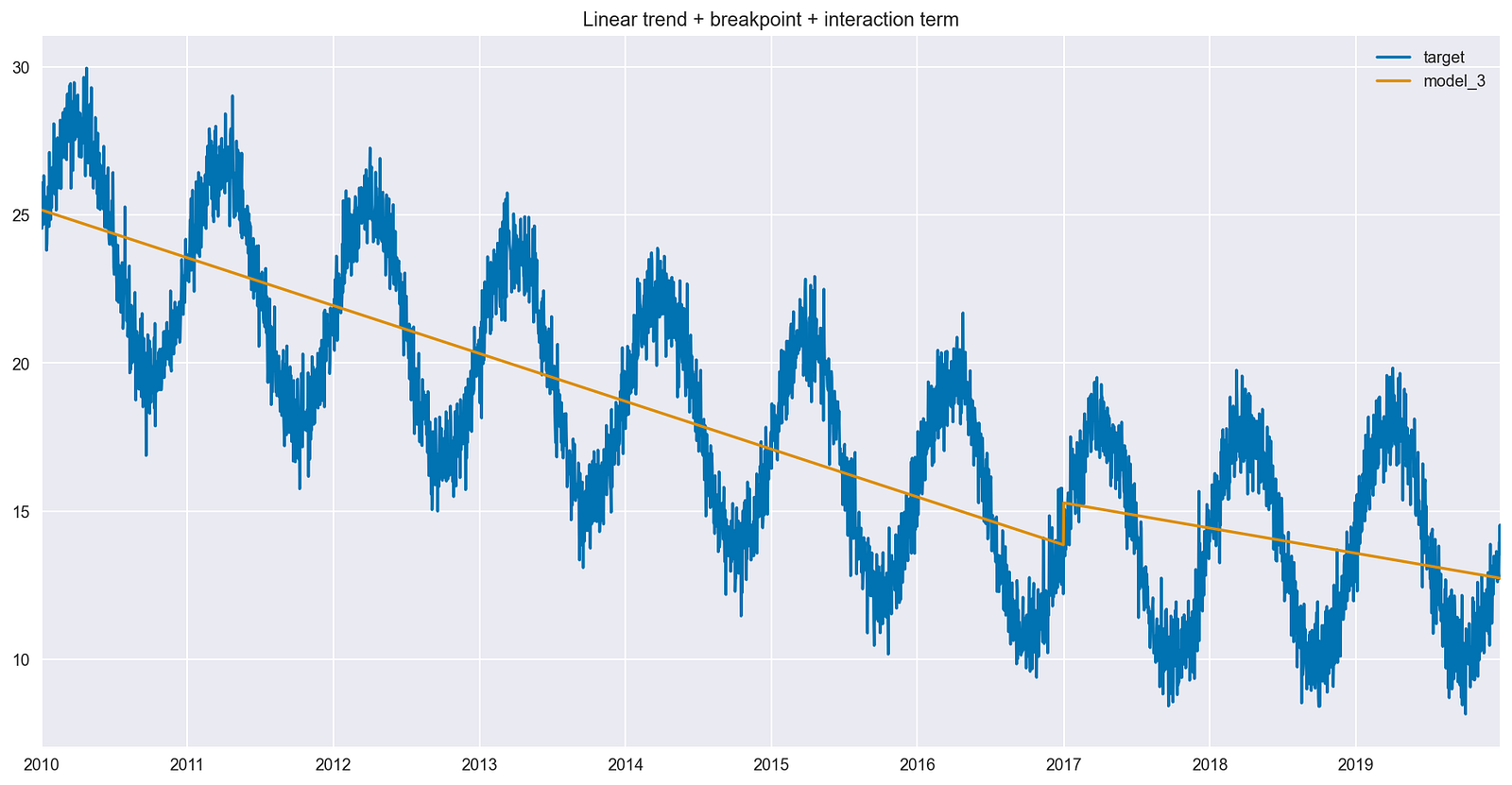
圖 5 顯示了在模型中使用交互項的影響。與圖 4 相比,最佳擬合線在斷點后的斜率不同。
更準確地說,差值實際上是相互作用項的系數值。雖然新線沒有變平,但它仍然沒有時間序列早期那么陡峭。
將斷點與交互項一起引入,提高了模型捕捉時間序列趨勢的能力。反過來,這應該會提高模型的預測性能。
總結
使用交互項可以使線性模型的規范更加靈活(不同線的斜率不同),從而更好地擬合數據并具有更好的預測性能。您可以將交互項添加為原始功能的乘積。在時間序列的上下文中,您可以使用交互術語來更好地捕捉趨勢的任何變化。
您可以在此帖子中使用的代碼“時間序列預測中交互項的全面指南”在 GitHub 上查找。此外,筆記本中的代碼展示了如何利用 cuDF 和 cuML 使用 GPU 加速訓練您的模型。我們歡迎您的反饋,您可以通過Twitter或在評論中聯系我。
?