
GPU 隨著新一代的出現而不斷加快,通常情況下 GPU 上的每個活動(如內核或內存拷貝)都會很快完成。在過去,每個活動都必須由 CPU 單獨安排(啟動),相關的開銷可能會累積起來,成為性能瓶頸。 CUDA Graphs功能通過將多個 GPU 活動安排為單個計算圖來解決這個問題。
這篇文章描述了 CUDA Graphs 最近是如何被GROMACS,是一個用于生物分子系統的模擬包,也是世界上使用率最高的科學軟件應用程序之一。我們將介紹 CUDA Graphs 和 GROMACS ,描述我們將 CUDA Graphs 集成到 GROMACS (以及與 GROMACS 共同設計)中的工作,展示性能結果,并向您展示如何在 GROMACS 中使用 CUDA Graphs
經過 NVIDIA 和core GROMACS developers,以充分利用現代 GPU 加速服務器。有關更多詳細信息,請參閱Creating Faster Molecular Dynamics Simulations with GROMACS 2020,Maximizing GROMACS Throughput with Multiple Simulations per GPU Using MPS and MIG,Massively Improved Multi-node NVIDIA GPU Scalability with GROMACS和Heterogeneous parallelization and acceleration of molecular dynamics simulations in GROMACS(以及其中的參考文獻)。
出身背景
GROMACS 之旅的最新一步是使用 CUDA 圖來進一步提高性能。此功能在 2023 年的新版本中可用。這項聯合設計工作不僅包括應用程序級專家,還包括 NVIDIA CUDA 軟件開發團隊。將 GROMACS 與尖端的 CUDA Graphs 技術相結合進行改進,最終將使其他應用受益。
CUDA 圖
本節以 GROMACS 友好的方式對 CUDA 圖形進行了非常簡要的概述。請參閱上一篇文章,Getting Started with CUDA Graphs,以全面介紹 CUDA 圖形。
圖 1 描述了許多 GPU 活動的計劃和執行。對于傳統的流模型(左),每個 GPU 活動都由 CPU API 調用單獨調度。使用 CUDA Graphs (右),單個 API 調用可以調度整個 GPU 活動集
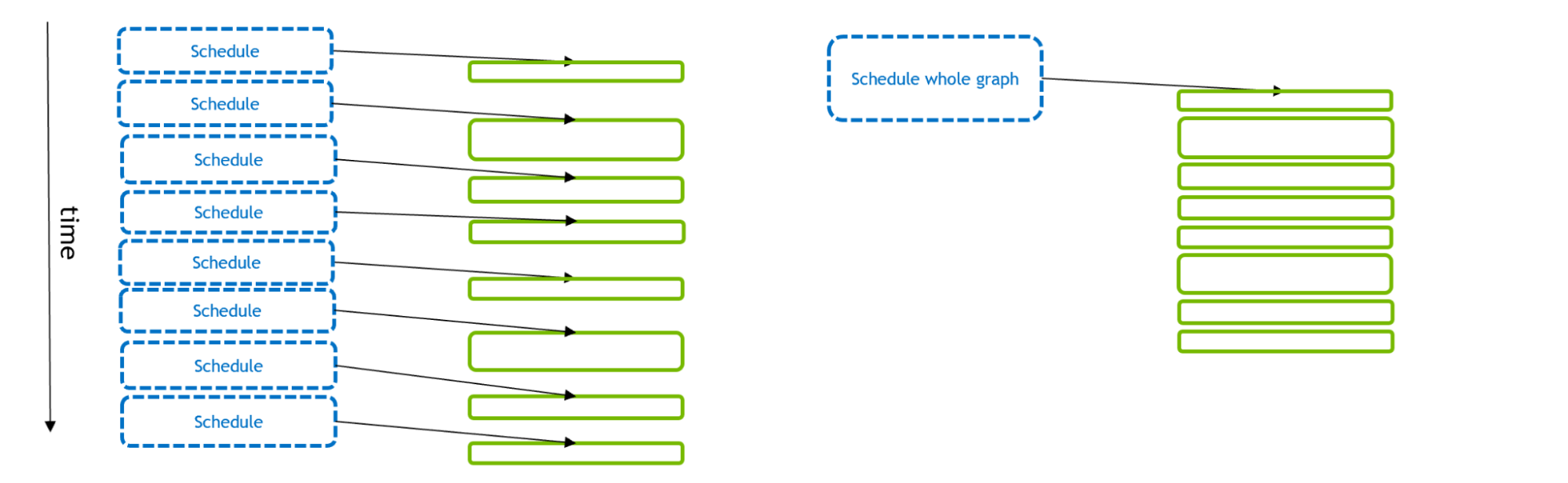
如果 GPU 活動很小,那么計劃可能需要比執行更多的時間。這使 GPU (在內核之間留下間隙)變得匱乏,總體執行效果不佳。但是,如果在單個 CUDA 圖中調度多個- GPU 活動,則可以減少 CPU API時間,從而實現更優化的 GPU 執行。此外,通過Graphs, CUDA 驅動程序具有關于工作流的額外信息,可以利用這些信息來優化圖本身的 GPU 執行。
如中所述Getting Started with CUDA Graphs,將現有的基于流的代碼調整為使用圖是相對簡單的。該功能通過一些額外的 CUDA API 調用將流執行“捕獲”到一個圖中。我們利用這一功能,使預先存在的 GROMACS 代碼能夠使用圖形而不是流來執行。
格羅馬克
GROMACS 是了解重要生物過程的關鍵工具,包括新冠肺炎等潛在流行病。每次 GROMACS 模擬都使用牛頓運動方程,通過重復更新來演化許多粒子的系統,其中粒子間的力決定粒子的運動
盡管物理原理相當簡單,但要通過多個級別的并行化和加速來實現非常高的性能,實現(必然)極其復雜。因此,每個模擬時間步長都涉及一個高度復雜的(通常是微秒級的)任務調度
圖 2 從左到右顯示了 GROMACS 是如何進化成為分子動力學的異步 GPU 引擎的。
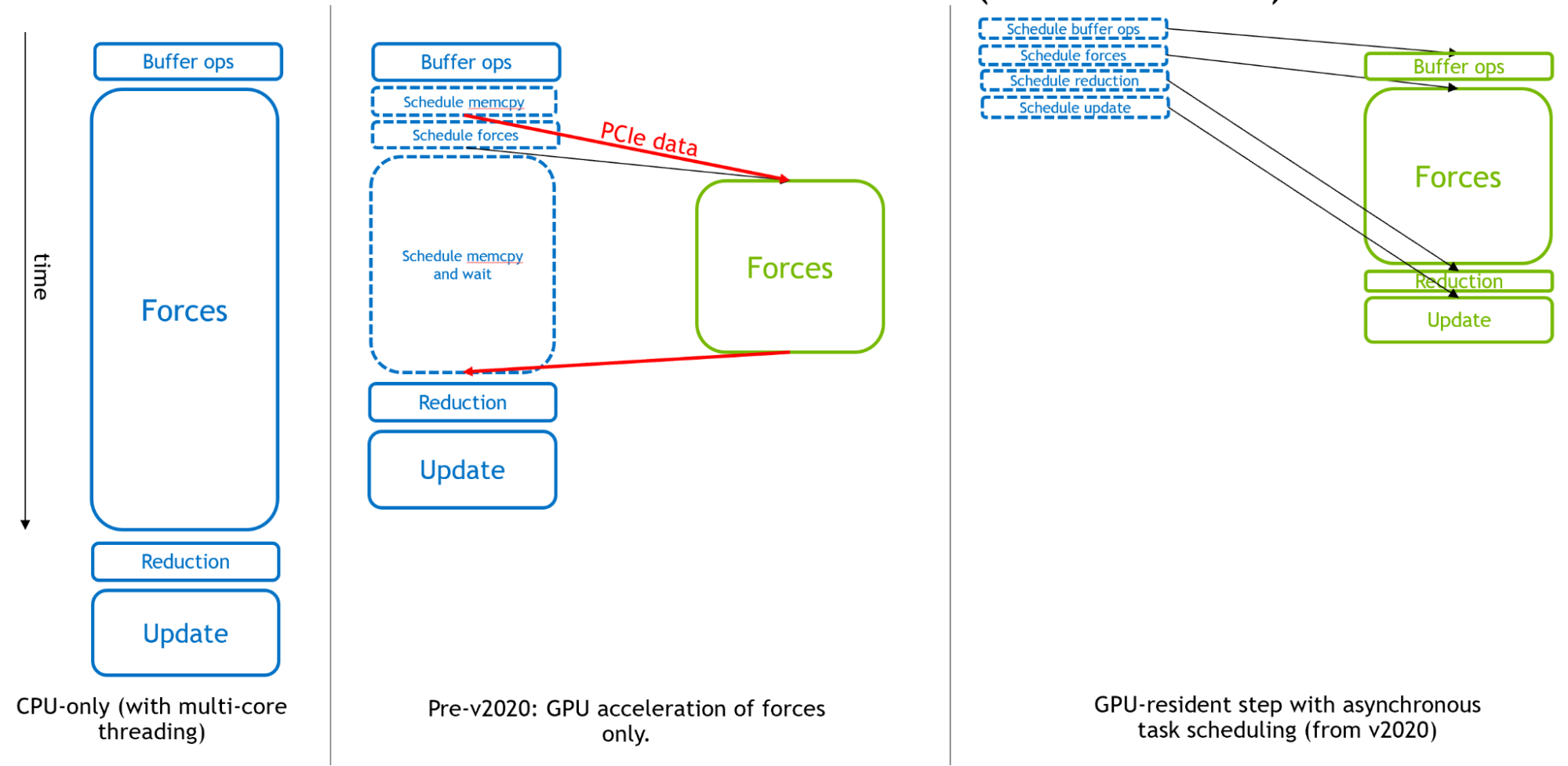
最初, CPU 用于整個模擬時間步長。然后,在 GPU 計算的早期,為了獲得有效的整體加速度,昂貴的力計算被轉移到GPU。
最后,為了支持極快的現代 GPU ,從GROMACS版本2020開始,所有其他組件都可以卸載,以啟用“GPU駐留模式”,在這種模式下,模擬狀態在 GPU 上保持多次迭代, CPU 主要負責調度在 GPU 上異步執行的活動。要了解更多信息,請參閱Creating Faster Molecular Dynamics Simulations with GROMACS 2020.
圖 2 的右側部分顯示了 GPU 計算,如果它們足夠大,將如何形成執行的“關鍵路徑”,從而使這些組件的性能決定整體模擬性能
然而,隨著 GPU 性能的不斷提高,小的情況可能會受到 CPU 調度開銷的限制,而不是如前一節中所述的GPU執行。當并行使用多個 GPU 來執行單個GROMACS模擬時,尤其如此
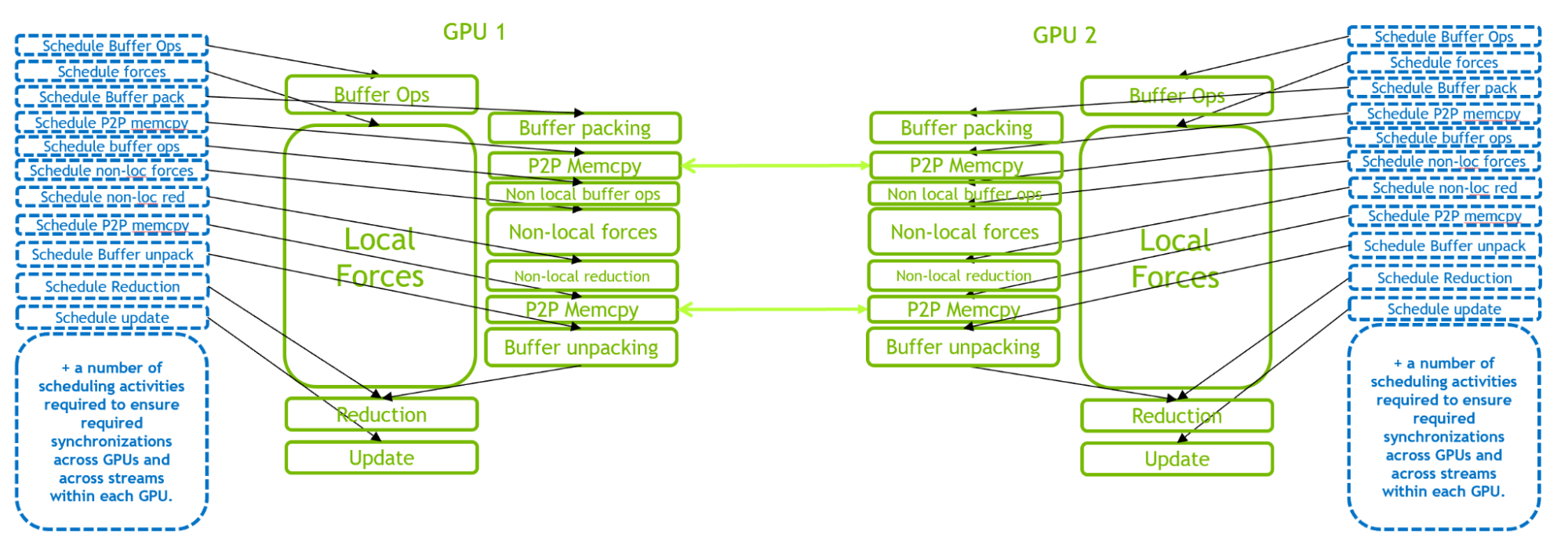
圖3說明了2- GPU 情況下的 GPU -駐留模式。由于 GPU 內部和內部的復混合編程互,與單個GPU情況相比,這種情況下的 CPU 調度工作負載要求更高。當引入更多 GPU 時,調度工作負載的要求甚至更高。
因此,在許多小情況下,性能瓶頸是 CPU 調度開銷,而不是 GPU 執行。這促使在 GROMACS 中引入 CUDA 圖,以使多個活動能夠作為單個圖進行調度,如以下部分所述。
在 GROMACS 中實現 CUDA 圖
本節介紹了 CUDA 圖在 GROMACS 中的引入。在高層,圖形捕獲和回放功能的使用方式與中提供的示例類似Getting Started with CUDA Graphs.
GROMACS 實現中存在許多與 GROMACS 可以在不同步驟上執行的不同類型的任務有關的復雜性,以及與管理多 GPU 任務和域分解有關的復雜性。請繼續閱讀以獲得簡要概述。有關完整的技術細節,請參閱 GitLab Issue ,Implement CUDA Graph Functionality and Perform Associated Refactoring,以及其中鏈接的合并請求
請注意, GROMACS 執行不同類型的模擬步驟:“常規”步驟加上不頻繁的“不規則”步驟,其中包括必須偶爾執行的額外活動(壓力耦合、溫度耦合、鄰居列表更新、域分解和許多其他)。我們已經通過每一步使用一個單獨的圖將 CUDA 圖引入 GROMACS ,并且到目前為止只支持在自然界中完全 GPU 存在的常規步驟
在每個模擬時間步長上:
- 檢查此步驟是否可以支持 CUDA Graphs 。如果是:
- 檢查是否已經存在合適的圖形。如果是:
- 執行該圖
- 否則:捕獲、實例化和保存新圖形
- 檢查是否已經存在合適的圖形。如果是:
- 否則:使用傳統流執行步驟
這使得可以在絕大多數步驟中使用 CUDA 圖來執行。有必要為每個鄰居列表或域分解步驟(通常每 100-400 個步驟)重新捕獲并創建一個可執行的新圖,這是非常罕見的,因此開銷最小
對于多個 GPU ,在所有 GPU 中使用單個圖形。到目前為止,這只支持thread-MPI,其中,多 GPU 圖是通過利用 CUDA 的自然能力來定義的,該能力可以在同一進程內(使用基于事件的 GPU – 側同步)在不同的 GPU 之間分叉和連接流,并將這些工作流自動捕獲到單個圖中。
我們在 GROMACS 中創建了一個新類來管理所有必需的功能。對于 multi-GPU ,這包括額外的基于事件的分叉和連接操作,以使單個圖能夠在多個 GPU 上定義和執行。
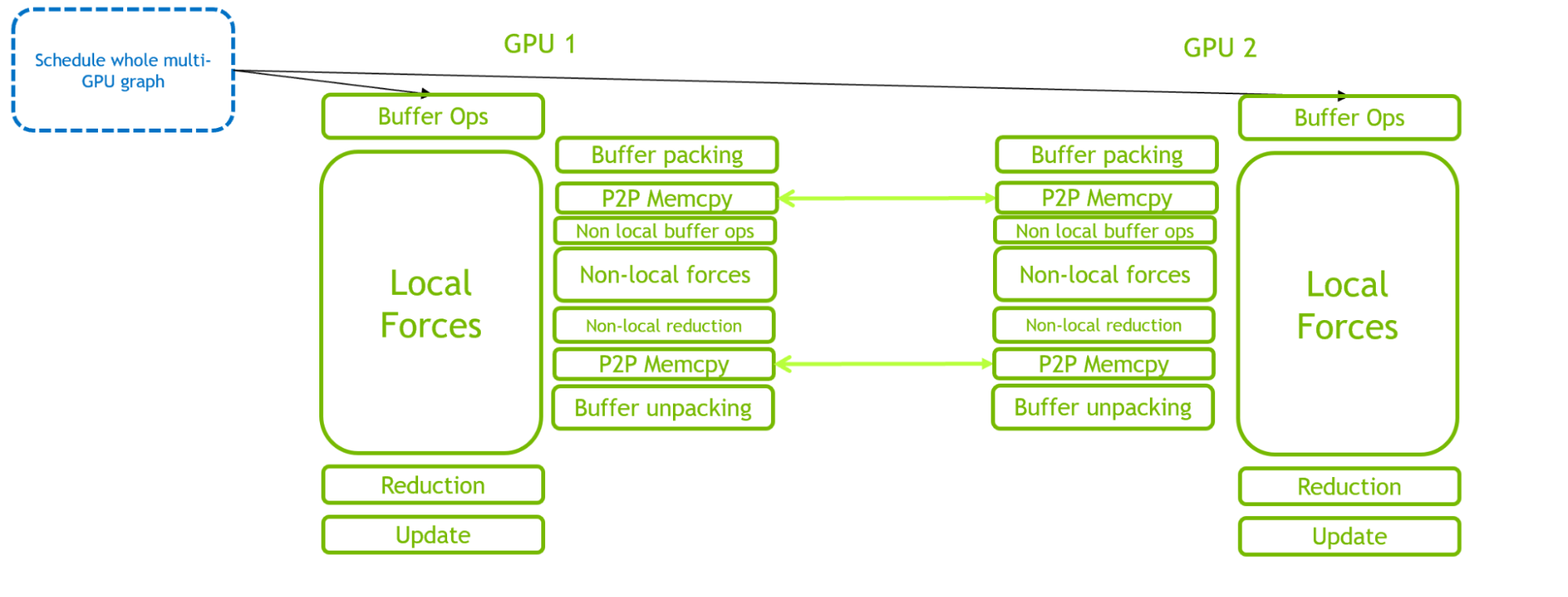
通過比較圖 3 和圖 4 ,可以清楚地看到 CUDA 圖在減少 CPU 側開銷方面的優勢。關鍵路徑從 CPU 調度開銷轉移到 GPU 計算。
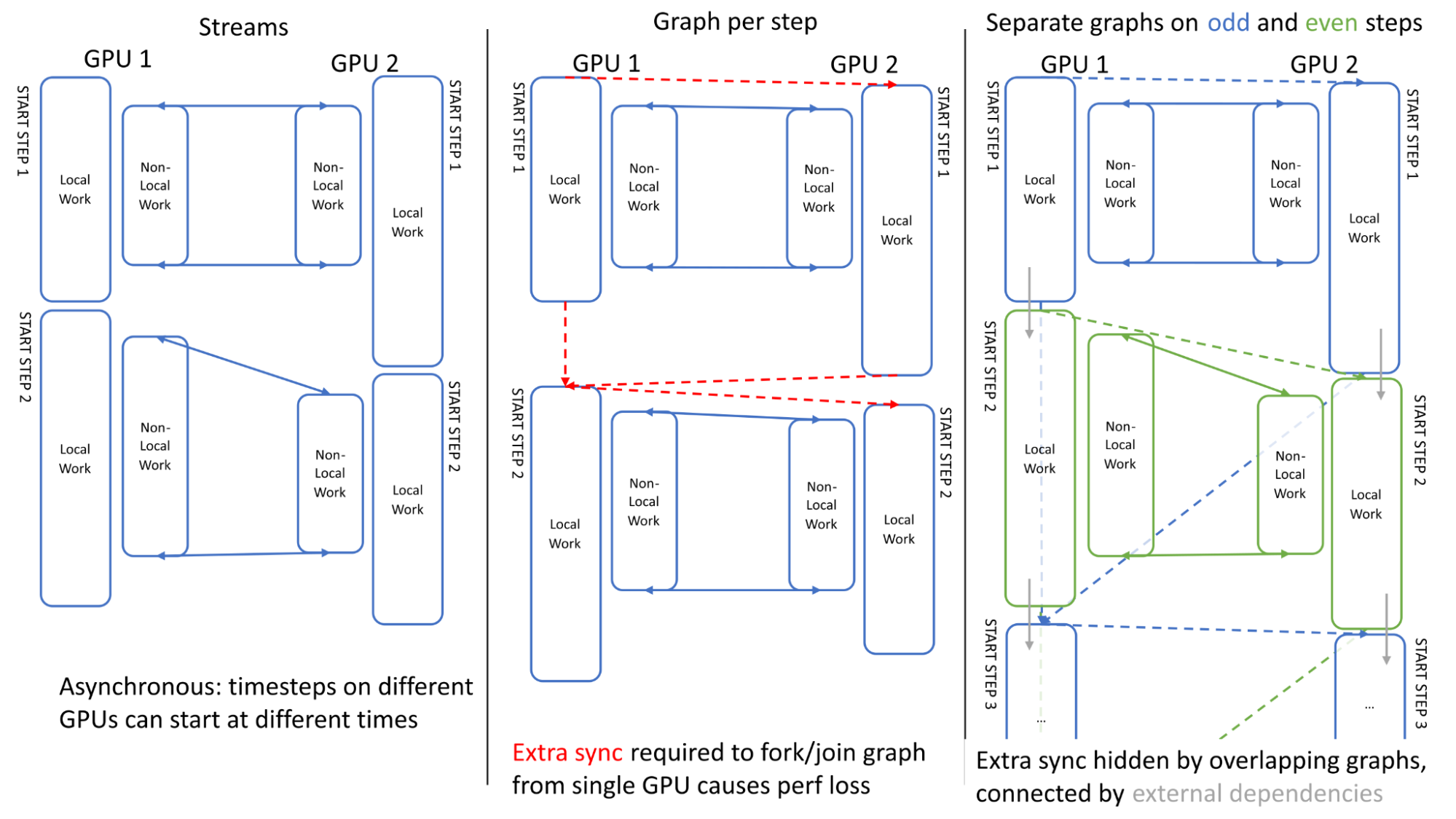
為了最大限度地提高多個 GPU 的性能,在鏈接多個模擬時間步長時,確保GPU之間的異步是很重要的。圖5展示了兩個步驟中的 GPU 活動。可以看出,當使用傳統流時, GPU 之間的執行是異步的: GPU 1可以在 GPU 2完成其第一步之前開始第二步(左)
我們第一次嘗試使用單個圖進行調度時遇到了一個問題:定義圖所需的額外同步(在單個 GPU 上分叉/連接到起點/終點)失去了這種異步性,導致了開銷(中心)
我們通過在奇數和偶數步驟上使用單獨的圖(右)來克服這個問題,其中這些步驟使用“外部” CUDA 事件進行鏈接,這些事件可以記錄在一個圖中,并在另一個圖內排隊(用灰色箭頭表示),有效地重疊了額外的同步。
圖 6 顯示了典型 4- GPU 配置的規則時間步長產生的真實圖形。我們不打算描述細節,但包括這張圖,以提供所涉及的許多活動和依賴關系的可視化,以及 CUDA Graphs 如何能夠如此有效地處理這種復雜性。
CUDA Graphs 技術本身的開發受到 GROMACS 要求的指導,包括支持與多線程圖形捕獲相結合的圖形更新,以及圖形中的流優先級支持。這些增強功能最終也將使其他應用程序受益。
性能結果
我們使用了Water Box一組基準測試來展示 GROMACS 中 CUDA 圖的優勢。這組基準可在gromacs.org benchmark repository它具有提供多個原子計數的優點,能夠評估性能行為如何隨系統大小而擴展
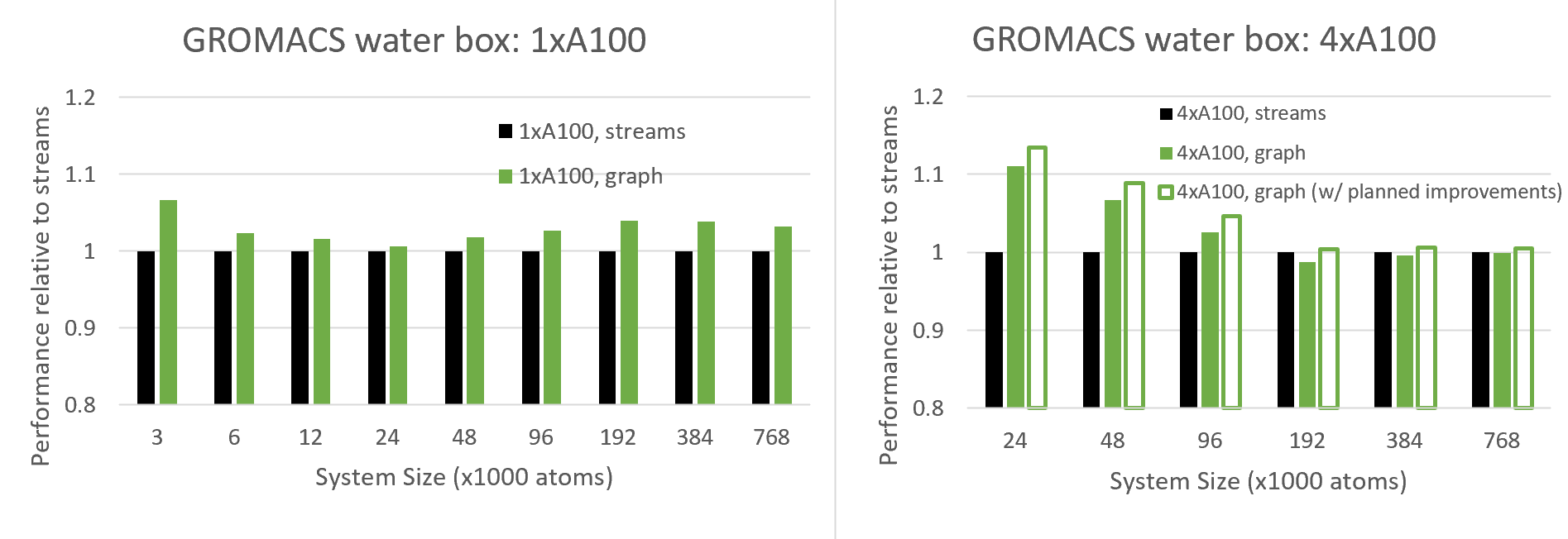
圖7比較了新的 CUDA Graphs功能與傳統流在不同系統大小下的性能,包括單次- GPU 和4-GPU運行
由于 CUDA 圖旨在減少 CPU API 開銷,這在小情況下最為顯著,我們預計在小系統規模下會看到越來越多的好處,我們確實在多 GPU 情況下看到了這種行為,在單 GPU 24K 原子及以下情況下也看到了這種行為
有趣的是,對于 24K 原子以上的單 – CUDA 情況,隨著系統尺寸達到 100K 原子左右,其益處實際上會增加。可以看出,與各種系統尺寸相比,圖形提供了顯著的性能優勢。這種行為需要更多的研究,但我們預計這是由于 GPU 圖增加了 GPU 方面的好處,其中當使用圖時, CUDA 可以更有效地跨多個內核調度線程塊。
對于多 GPU 情況,圖的好處更為深刻,因為(如上所述)由于其復雜的調度,該配置對 CPU API 開銷更為敏感。在目前的版本中,我們看到了高達 100K 原子的好處(在這種情況下),超過這個數字我們會看到輕微的退化
然而,我們也顯示了計劃改進的預期結果,這減少了與重復重新構建圖相關的開銷。這種改進需要在 CUDA 驅動程序的未來版本中提供支持,該驅動程序目前正在與 GROMACS 共同設計中進行改進。通常,我們建議用戶針對自己的情況嘗試 CUDA Graphs ,并在有利的情況下啟用該功能(請參閱下一節)。
如何在 GROMACS 中使用 CUDA 圖
如上所述,這種新的 CUDA Graphs功能可用于 GPU 駐留步驟,當所有力和更新計算通過以下方式卸載到GPU 時,通常會調用這些步驟mdrun選項:
-nb gpu -bonded gpu -pme gpu -update gpu當與多個任務一起運行以并行啟用多個 GPU 時, GROMACS 應該使用其內部線程 MPI 庫而不是外部 MPI 來構建 (-DGMX_MPI=OFF) ; GPU 應通過設置以下環境變量來指定直接通信:
export GMX_ENABLE_DIRECT_GPU_COMM=1單個 PME GPU 應指定-npme 1.
然后,可以使用以下內容觸發 CUDA 圖:
export GMX_CUDA_GRAPH=1我們建議在任何特定情況下進行實驗,如果可以提供性能優勢,則選擇使用圖形。請注意,這仍然是一個實驗性特征,測試有限,因此應注意確保結果如預期(例如,通過比較有圖和無圖的科學結果子集)。我們歡迎在GROMACS GitLab地點
總結
這篇文章描述了我們如何將 CUDA 圖集成到 GROMACS 中。這使得 CPU 能夠在單個計算圖中調度多個 GPU 活動,這比傳統的流編程模型更優化。我們展示了這些好處,包括在并行運行多個 GPU 時。這項工作是我們不斷努力的重要組成部分,旨在通過基于圖形的任務調度使 GROMACS 現代化,以幫助開發日益復雜的硬件來解決日益復雜的科學問題
要開始,請按照本文中提供的說明,嘗試為您自己的 GROMACS 案例激活 CUDA Graphs
想了解更多信息嗎?加入GROMACS forum.
?





