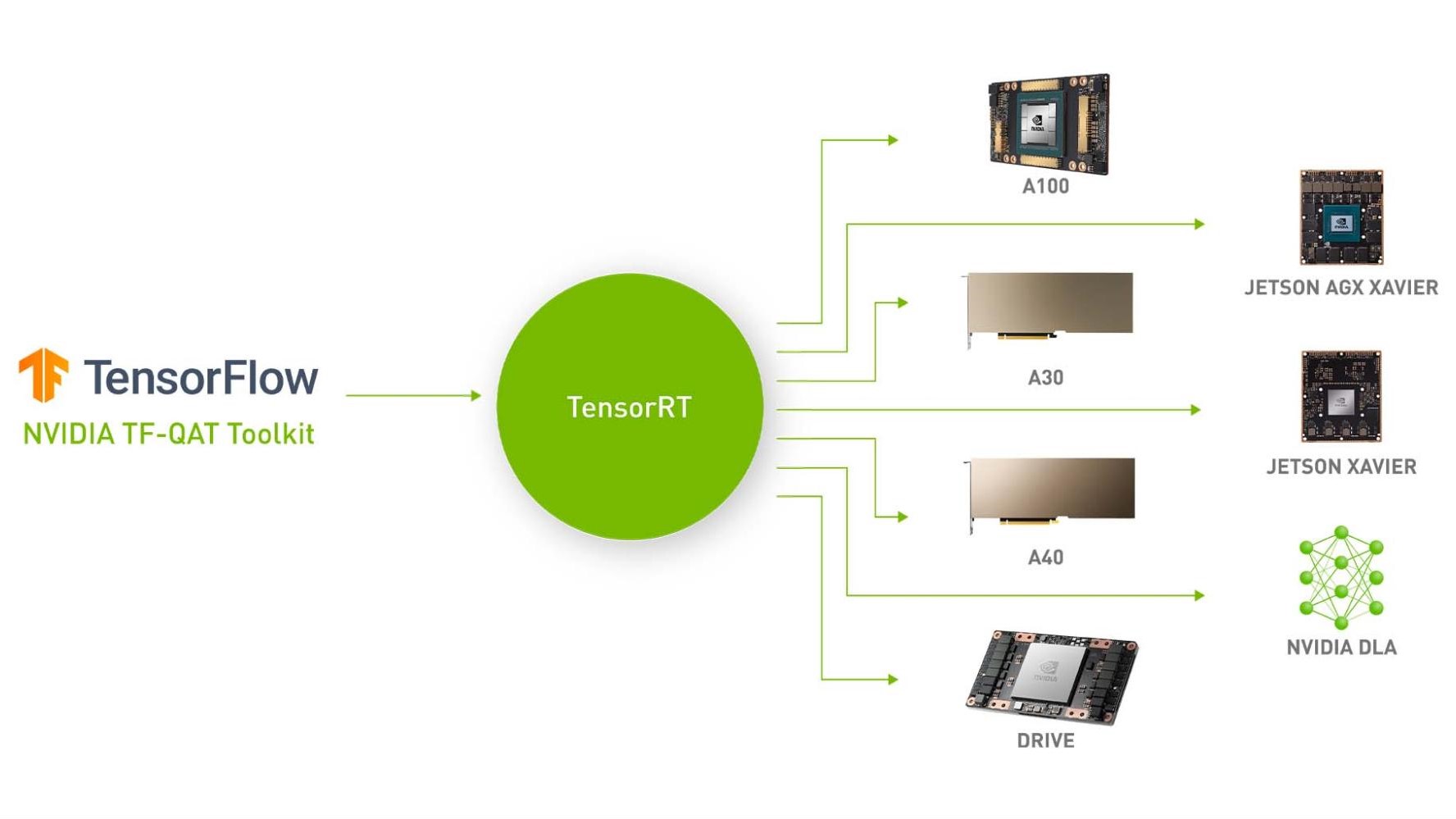
在快速發展的環境中,生成人工智能的發展對加速推理速度的需求仍然是一個緊迫的問題。隨著模型規模和復雜性的指數級增長,對快速生成結果以同時服務于眾多用戶的需求也在持續增長。NVIDIA 平臺站在這一努力的前沿,通過芯片、系統、軟件和算法等全技術堆棧的創新,實現永久的性能飛躍。
NVIDIA 正在擴展其推理產品 NVIDIA TensorRT 模型優化器,一個集成了最先進的后期訓練和環中訓練模型優化技術的綜合庫。這些技術包括量化和稀疏性,旨在降低模型復雜性,以實現更高效的下游推理庫,如 NVIDIA TensorRT LLM,從而更有效地優化深度學習模型的推理速度。
作為 NVIDIA TensorRT 生態系統的一部分,NVIDIA TensorRT 模型優化器(簡稱模型優化器)可用于多種流行的體系結構,包括 NVIDIA Hopper、NVIDIA Ampere 和 NVIDIA Ada Lovelace 等。
模型優化器為 PyTorch 和 ONNX 模型生成模擬量化檢查點。這些量化檢查點已準備好無縫部署到 TensorRTLLM 或 TensorRT,并即將支持其他流行的部署框架。模型優化器 Python API 使開發人員能夠堆疊不同的模型優化技術,以在 TensorRT 中現有的運行時和編譯器優化的基礎上加速推理。
量化技術
訓練后量化(PTQ)是減少內存占用和加速推理的最流行的模型壓縮方法之一。雖然其他一些量化工具包僅支持僅限權重的量化或基本技術,但 Model Optimizer 提供高級校準算法,包括 INT8 SmoothQuant 和 INT4 AWQ(激活感知權重量化)。如果您正在使用 FP8 或更低的精度,例如 TensorRT LLM 中的 INT8 或 INT4,您已經在幕后利用 Model Optimizer 的 PTQ 了。
在過去的一年里,Model Optimizer 的 PTQ 已經讓無數 TensorRT LLM 用戶能夠 在保持模型準確性的同時,為 LLM 實現顯著的推理加速。此外,通過 INT4 AWQ,Falcon 180B 可以安裝在單個 NVIDIA H200 GPU 上。圖 1 展示了用戶可以在 Llama 3 模型上使用 Model Optimizer PTQ 實現的推理加速結果。
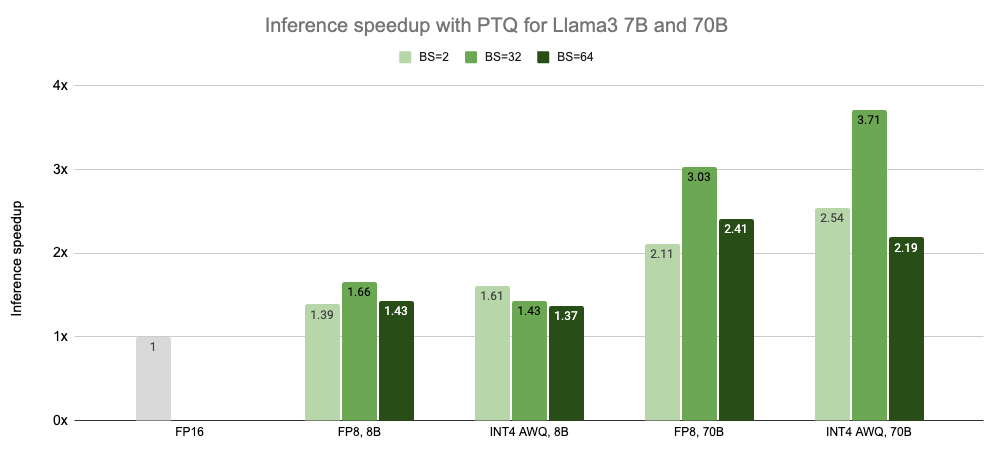
在不使用批處理的情況下測量的延遲,速度標準化為每個 GPU 的計數。
在沒有量化的情況下,即使在 NVIDIA A100 Tensor Core GPU 上,模型的計算速度仍然會影響最終用戶的體驗。幸運的是,來自 Model Optimizer 的領先的 8 位(INT8 和 FP8)后訓練量化技術已經在 TensorRT 的框架下使用擴散部署管道 和 Stable Diffusion XL NIM,以加快圖像生成。
在最新的 MLPerf 推理 v4.0 中,模型優化器進一步增強了 TensorRT,使 Stable Diffusion XL 的性能高于所有替代方法。通過這項 8 位量化功能,許多生成型人工智能公司能夠在保持模型質量的情況下,以更快的推理速度提供用戶體驗。
要查看 FP8 和 INT8 的端到端示例,請訪問 NVIDIA/TensorRT-Model-Optimizer 和NVIDIA/TensorRT 在 GitHub 上。根據校準數據集的大小,擴散模型的校準過程通常只需幾分鐘。對于 FP8,我們在 RTX 6000 Ada 上觀察到 1.45 倍的加速,而在沒有 FP8 MHA 的 L40S 上觀察到 1.35 倍的速度提升。表 1 顯示了 INT8 和 FP8 量化的補充基準結果。
| GPU | INT8 延遲(ms) | FP8 延遲(ms) | 加速(INT8 與 FP16) | 加速(FP8 與 FP16) |
| RTX 6000 Ada | 2, 479 | 2, 441 | 1.43 倍 | 1.45 倍 |
| RTX 4090 | 2, 058 | 2, 161 | 1.20 倍 | 1.14 倍 |
| L40S | 2, 339 | 2, 168 | 1.25 倍 | 1.35 倍 |
| H100 80GB HBM3 | 1, 209 | 1, 216 | 1.08 倍 | 1.07 倍 |
配置:穩定擴散 XL 1.0 基本型號。圖像分辨率為 1024×1024 像素;30 步。TensorRT v9.3。批量大小為 1

為下一代平臺實現超低精度推理?
最近宣布的 NVIDIA Blackwell 平臺 憑借其 4 位浮點人工智能推理能力,為計算新時代提供動力。模型優化器在保證模型質量的同時,在實現 4 位推理方面發揮著關鍵作用。當模型轉向 4 位推理時,訓練后量化通常會導致模型精度的顯著下降。
為了解決這一問題,模型優化器為開發人員提供量化感知訓練(QAT),以在不影響準確性的情況下以 4 位的速度完全解鎖推理。通過在訓練過程中計算縮放因子,并將模擬的量化損失納入微調過程,QAT 使神經網絡對量化更有彈性。
Model Optimizer QAT 工作流程旨在與領先的培訓框架集成,包括 NVIDIA NeMo、Megatron-LM 和 Hugging Face transformers API。這為開發人員提供了在各種框架中利用 NVIDIA 平臺功能的選項。如果您想在 NVIDIA Blackwell 平臺可用之前開始使用 QAT,請 遵循 INT4 QAT 示例,并與 Hugging Face transformers API 進行集成。
我們的研究表明,即使 QAT 僅應用于監督微調(SFT)階段而不是預訓練階段,QAT 也可以在低精度下獲得比 PTQ 更好的性能。這意味著 QAT 可以以低訓練成本應用,使對精度下降敏感的生成人工智能應用程序能夠在不久的將來保持精度,即使在超低精度下,其中權重和激活都是 4 位。
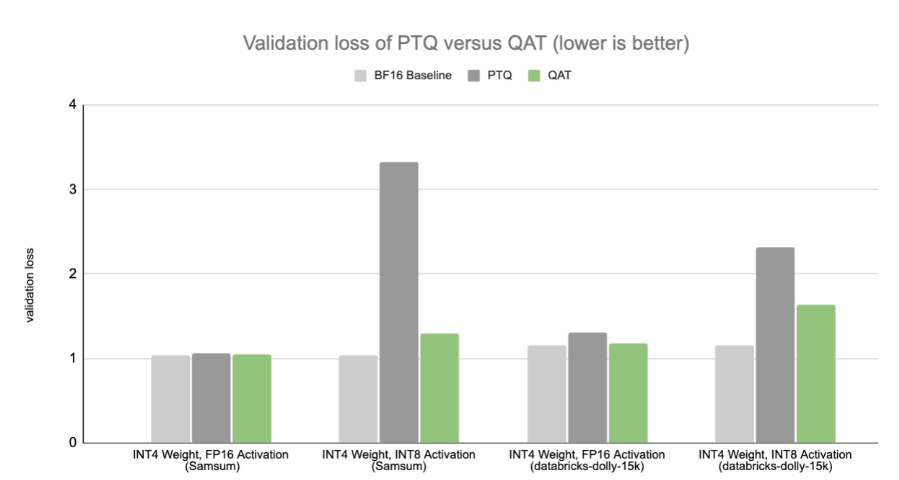
基線模型在目標數據集上進行了微調。請注意,我們在此基準測試中使用 INT4 來演示量化感知訓練(QAT)。隨著 NVIDIA Blackwell 平臺的全面發布,4 位結果將變得可用。
具有稀疏性的模型壓縮?
傳統上,深度學習模型過于密集和參數化。這推動了對另一類模型優化技術的需求。稀疏性通過選擇性地鼓勵模型參數中的零值來進一步減小模型的大小,這些零值然后可以從存儲或計算中丟棄。
基于 Llama 2 70B 的 FP8 量化,模型優化器訓練后的稀疏性在批量大小為 32 的情況下提供了額外的 1.62x 加速。這是通過使用 NVIDIA H100 GPU 實現的,該 GPU 采用 NVIDIA Ampere 架構中引入的專有 NVIDIA 2:4 稀疏性。要了解更多信息,請參閱 使用 NVIDIA Ampere 架構和 NVIDIA TensorRT 加速稀疏推理。
在 MLPerf 推理 v4.0 中,TensorRT LLM 利用模型優化器訓練后的稀疏性將 Llama 2 70B 模型壓縮了 37%。這使得模型和 KV 緩存能夠適應單個 H100 GPU 的 GPU 內存,從而將張量并行度從 2 降低到 1。在 MLPerf 中的這一特定摘要任務中,模型優化器成功地保留了稀疏模型的質量,滿足了 MLPerf 閉除法設置的 Rouge 分數 99.9% 的準確率目標。
| 模型 | 批量大小 | 推理加速 (與相同批量的 FP8 密集型相比) |
稀疏 Llama 2 70B |
32 | 1.62 倍 |
| 64 | 1.52 倍 | |
| 128 | 1.35 倍 | |
| 896 | 1.30 倍 |
FP8:TP=1,PP=1 適用于所有稀疏化模型。由于權重尺寸較大,密集模型需要 TP=2
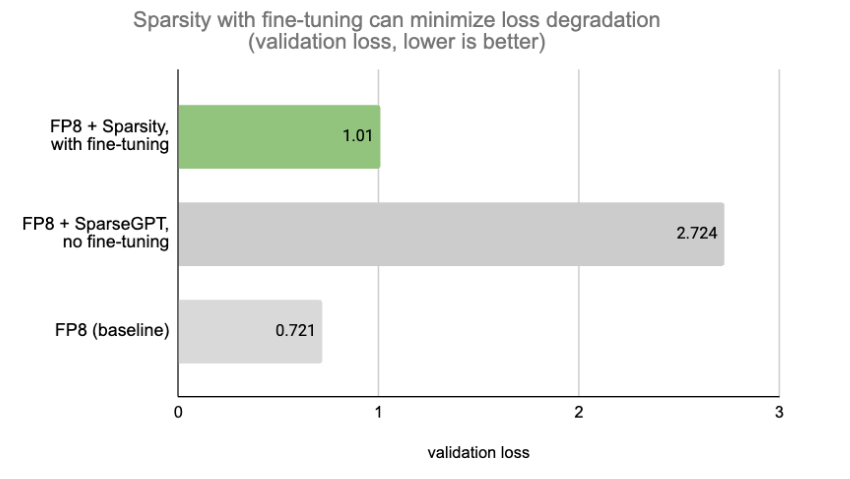
雖然 MLPerf 設置幾乎沒有精度下降,但在大多數情況下,將稀疏性與微調相結合以保持模型質量是一種常見的做法。Model Optimizer 提供了用于稀疏性感知微調的 API,這些 API 與包括 FSDP 在內的流行并行技術兼容。圖 4 顯示,使用帶有微調的 SparseGPT 可以最大限度地減少損耗退化。
可組合模型優化 API
在模型上應用不同的優化技術,如量化和稀疏性,傳統上需要一種非平凡的多級方法。為了解決這一痛點,Model Optimizer 為開發人員提供了可組合的 API,以堆疊多個優化步驟。圖 5 中的代碼片段演示了如何將稀疏性和量化與 Model Optimizer 可組合 API 相結合。
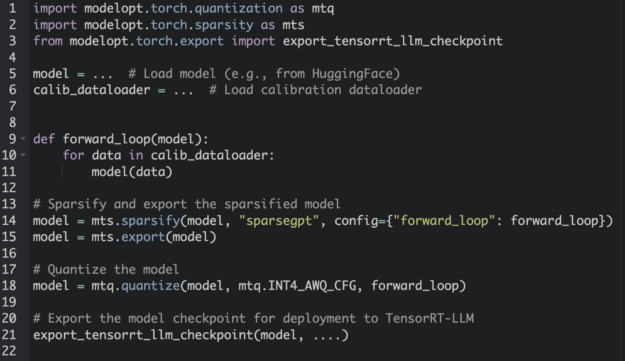
此外,Model Optimizer 還提供了各種有用的功能,如單行 API,用于檢索模型狀態信息,并為任何需要完全再現性的實驗完全恢復模型修改。
開始?
現在,您可以在 NVIDIA PyPI 上安裝 NVIDIA TensorRT Model Optimizer 作為 nvidia-modelopt。要訪問推理優化的示例腳本和配方,請訪問 NVIDIA/TensorRT-Model-Optimizer 在 GitHub 上。有關更多詳細信息,請參閱 TensorRT 模型優化器文檔,以獲取更深入的了解。
鳴謝?
特別感謝 TensorRT 模型優化器開發背后的敬業工程師,包括 Asma Kuriparambil Thekkumpate、Kai Xu、Lucas Liebenwein、Zhiyu Cheng、Riyad Islam、Ajinkya Rasane、Jingyu Xin、Wei Ming Chen、Shengliang Xu、Meng Xin、Ye Yu、Chen Han Yu、Keval Morabia、Asha Anoosheh 和 James Shen。(名單順序不反映貢獻水平。)
?
?