
本文是加速數據分析系列文章的一部分。
可視化使數據栩栩如生,通過可訪問的視覺效果揭示隱藏的模式和見解,并使您和您的組織能夠感知無形的事物,做出明智的決策,并充分利用您的數據。
特別是在處理大型數據集時,交互可能會變得非常困難,因為渲染和計算時間變得太長。切換到 RAPIDS cuDF 等庫,支持 GPU 加速,通過熟悉的類似 pandas 的 API 解鎖對數據見解的訪問。這篇文章解釋道:
- 為什么速度對于可視化很重要,尤其是對于大型數據集
- 如何在 RAPIDS 中使用 pandas 類特征進行可視化
- 如何使用 hvPlot 、 datashader 、 cuxfilter 和 Plotly Dash
為什么速度對可視化很重要
雖然數據可視化是在項目結束時解釋數據見解的有效工具,但理想情況下,應在整個數據探索和豐富過程中使用它們。可視化擅長于通過發現純分析方法不容易出現的異常值、異常和模式來增強數據理解,這已經被證明,例如Anscombe’s quartet以及臭名昭著的Datasaurus Dozen。
有效的圖表應遵循數據可視化設計原則,利用先前注意力可視處理,這種可視化風格本質上是大腦快速理解大量信息的一種技巧。然而,過濾、選擇或重新繪制超過7-10秒的點等交互會破壞用戶的短期記憶和思路,從而在分析過程中產生摩擦。想要了解更多信息,請參閱10的冪:用戶體驗中的時間尺度。
將亞秒級的速度與易于集成相結合的RAPIDS一套開源軟件庫非常適合用于補充探索性數據分析(EDA)工作——推動流暢、一致的見解,從而在分析項目中獲得更好的結果。

大型數據分析工作流需要更多的計算能力
pandas 簡化了數據工作,有助于建立強大的 Python 可視化生態系統,例如 Bokeh 、 Plotly 和 Matplotlib 等工具,使更多的人能夠定期使用視覺效果進行數據分析。
但是,當 EDA 工作流處理大于 2GB 的數據,并且需要計算密集型任務時,基于 CPU 的解決方案可以開始約束迭代探索過程。
使用 RAPIDS 加速數據可視化
將基于 CPU 的庫替換為類似 RAPIDS GPU 的加速庫(如 cuDF )意味著,隨著數據大小在 2 到 10 GB 之間的增加,您可以保持 EDA 過程的快速步伐。可視化計算和渲染時間降低到交互速度,從而解鎖發現過程。此外,由于 RAPIDS 庫無縫協作,您可以使用簡單、熟悉的 Python 代碼繪制多種類型的數據(時間序列、地理空間、圖表),以將其納入整個工作流程。
RAPIDS 可視化指南
在 GitHub 上,這個RAPIDS Visualization Guide演示了可視化庫協同工作的功能和好處。基于公開的Divvy bike share 歷史行程數據,筆記本電腦展示了以可視化為重點的 EDA 方法如何使用以下支持 GPU 的庫進行改進:
- hvPlot:一款用于快速可視化的庫。
- Datashader
- cuxfilter
- Plotly Dash
使用 hvPlot 實現簡單的數據交互
hvPlot 是一個類似 pandas 的繪圖 API ,但具有內置的交互性,如圖 1 所示。
df.hvplot.hist(y='duration_min', bins=20, title="Trips Duration Histogram")
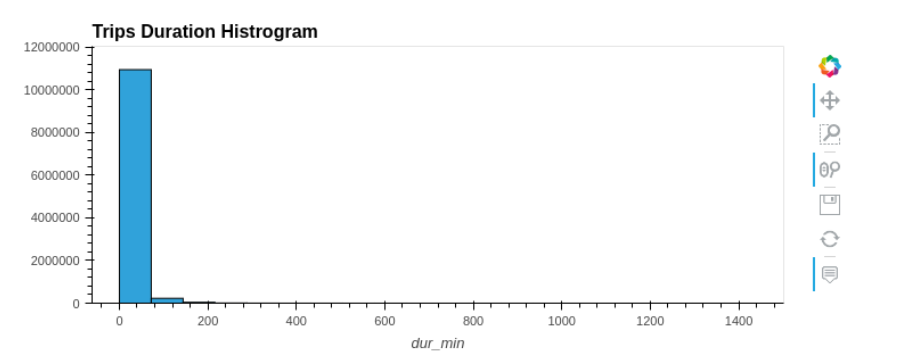
在這種情況下,絕大多數的自行車旅行時間都在 20 分鐘以內。由于能夠放大,您還可以在不創建其他查詢的情況下檢查持續時間的長尾。使用 RAPIDS cuSpatial 對數據進行擴充以快速計算距離,也表明大多數行程相對較短。
一些 hvPlot 附加功能
hvPlot 中的圖表可以使用 Bokeh 和 Plotly 擴展進行交互顯示,也可以使用 Matplotlib 擴展進行靜態顯示。多個圖表可以使用*運算符共享軸,也可以使用+運算符進行并行基本布局。可以使用HoloViz Panel創建更復雜的儀表板布局。
您還可以自動添加簡單的小部件。例如,當通過操作使用內置組時:
df.hvplot.heatmap(x='day_of_week', y='hour', C='count', groupby='month', widget_location='left_top')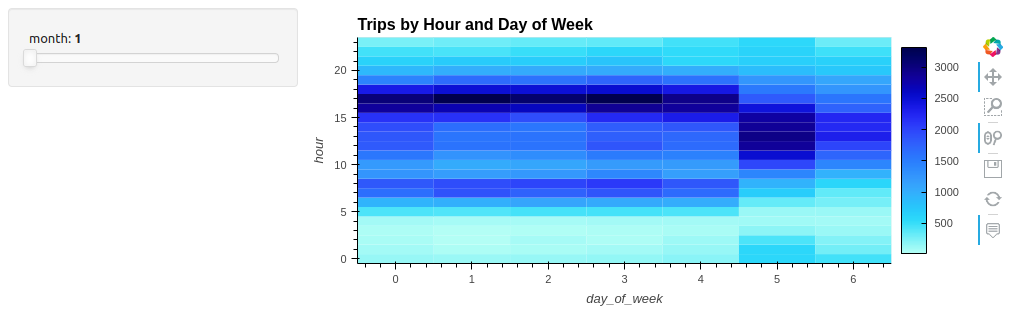
添加一個用于交互的小部件可以在幾個月內搜索一整年的模式(圖 2 )。在可視化中,“一個滑塊值一千個查詢”,或者在本例中是 12 。
輕松繪制地理空間
可以通過簡單地指定geo=True來使用具有多個選項的地理空間圖底層瓦片地圖:
df.hvplot.hexbin(x='start_lng', y='start_lat', geo=True, tiles="OSM")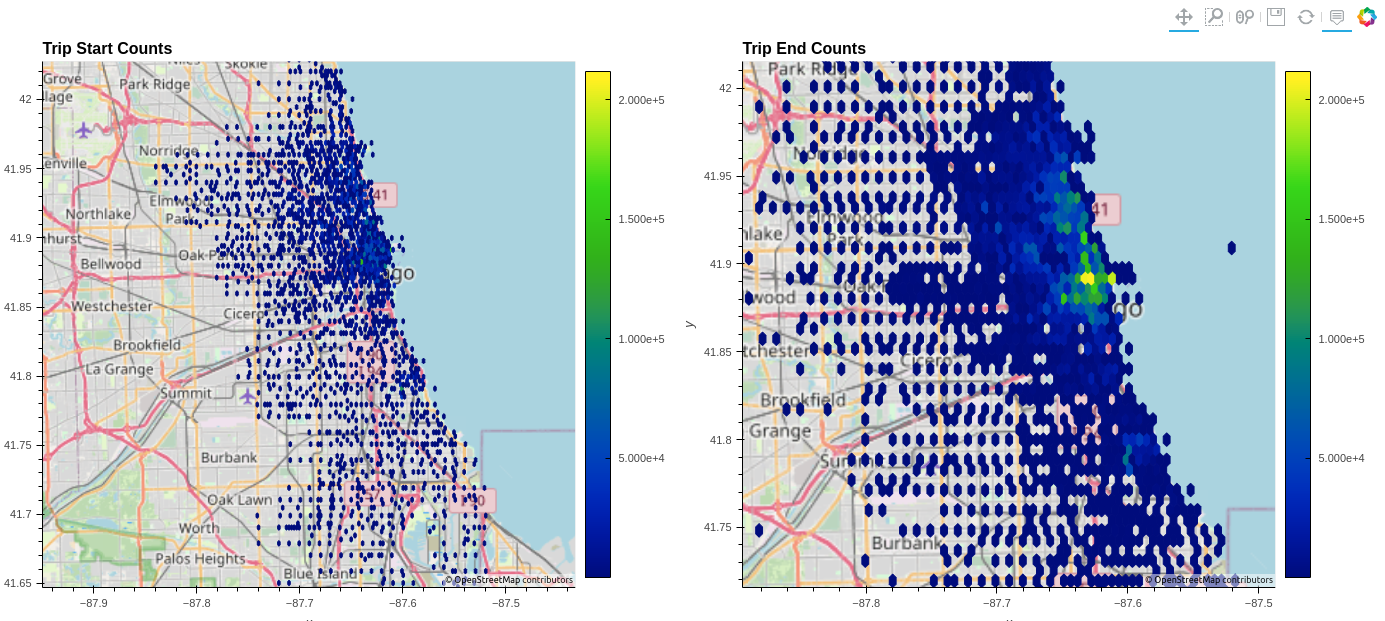
圖 3 顯示了六角圖,該圖將行程開始和結束位置聚合到可管理的數量,驗證了數據是否與共享單車系統地圖準確無誤。與加號運營商并排設置兩張圖表說明了自行車網絡的輻射性質。
對大數據和高精度圖表使用 Datashader
Datashader 庫直接支持 cuDF ,可以快速渲染數百萬個聚合點。您可以單獨使用它來渲染各種精確和高密度的圖表類型。通過指定datashade=True:
df.hvplot.points(x='start_lng', y='start_lat', geo=True, tiles="CartoDark", datashade=True, dynspread=True)
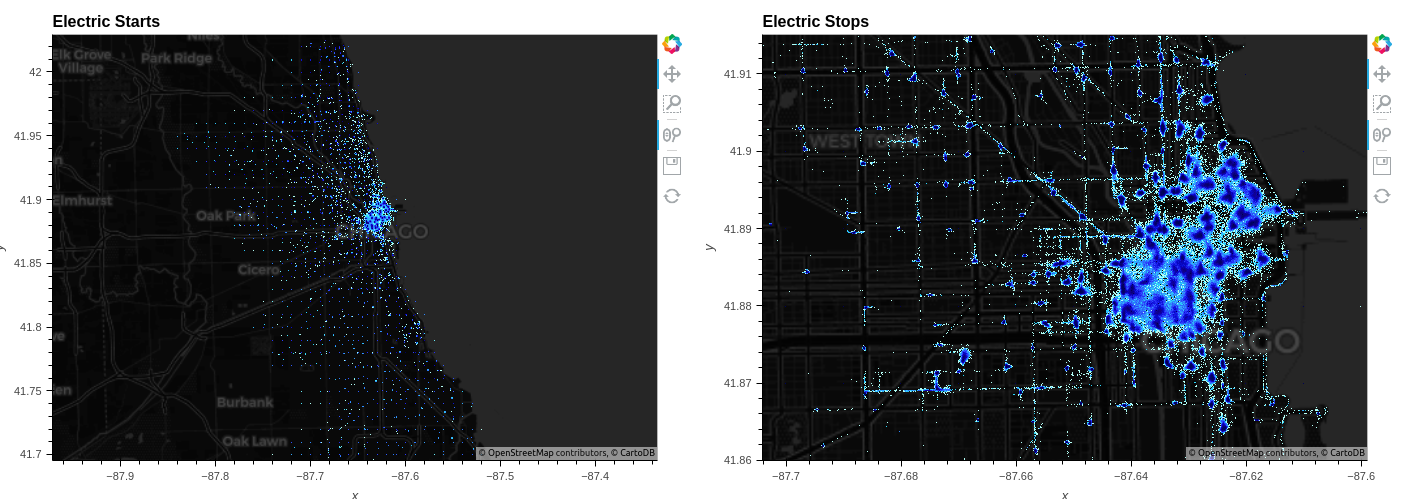
顯示高分辨率圖案的數據點渲染正是 Datashader 的設計初衷。在圖 4 中,它清楚地表明,雖然自行車往往會聚集在一起,但不能保證自行車會在指定的車站開始或結束旅程。
將 cuxfilter 用于加速交叉過濾的儀表板
cuxfilter 儀表板可以簡單地交叉鏈接多個圖表,以快速查找模式或異常,而不是創建幾個單獨的分組和查詢操作(圖 5 )。
只需幾行代碼即可啟動并運行儀表板:
cux_df = cuxfilter.DataFrame.from_dataframe(df)
# Specify charts
charts = [
cuxfilter.charts.bar('dist_m', data_points=20 , title='Distance in M'),
cuxfilter.charts.bar('dur_min', data_points=20 , title='Duration in Min'),
cuxfilter.charts.bar('day_of_week', title='Day of Week'),
cuxfilter.charts.bar('hour', title='Trips per Hour'),
cuxfilter.charts.bar('day', title='Trips per Day'),
cuxfilter.charts.bar('month', title='Trips per Month')
]
# Specify side panel widgets
widgets = [
cuxfilter.charts.multi_select('year')
]
# Generate the dashboard and select a layout
d = cux_df.dashboard(charts, sidebar=widgets, layout=cuxfilter.layouts.two_by_three, theme=cuxfilter.themes.rapids, title='Bike Trips Dashboard')
# Update the yaxis ticker to an easily readable format
for i in charts:
if hasattr(i.chart, 'yaxis'):
i.chart.yaxis.formatter = NumeralTickFormatter(format="0,0")
# Show generates a full dashboard in another browser tab
d.show()
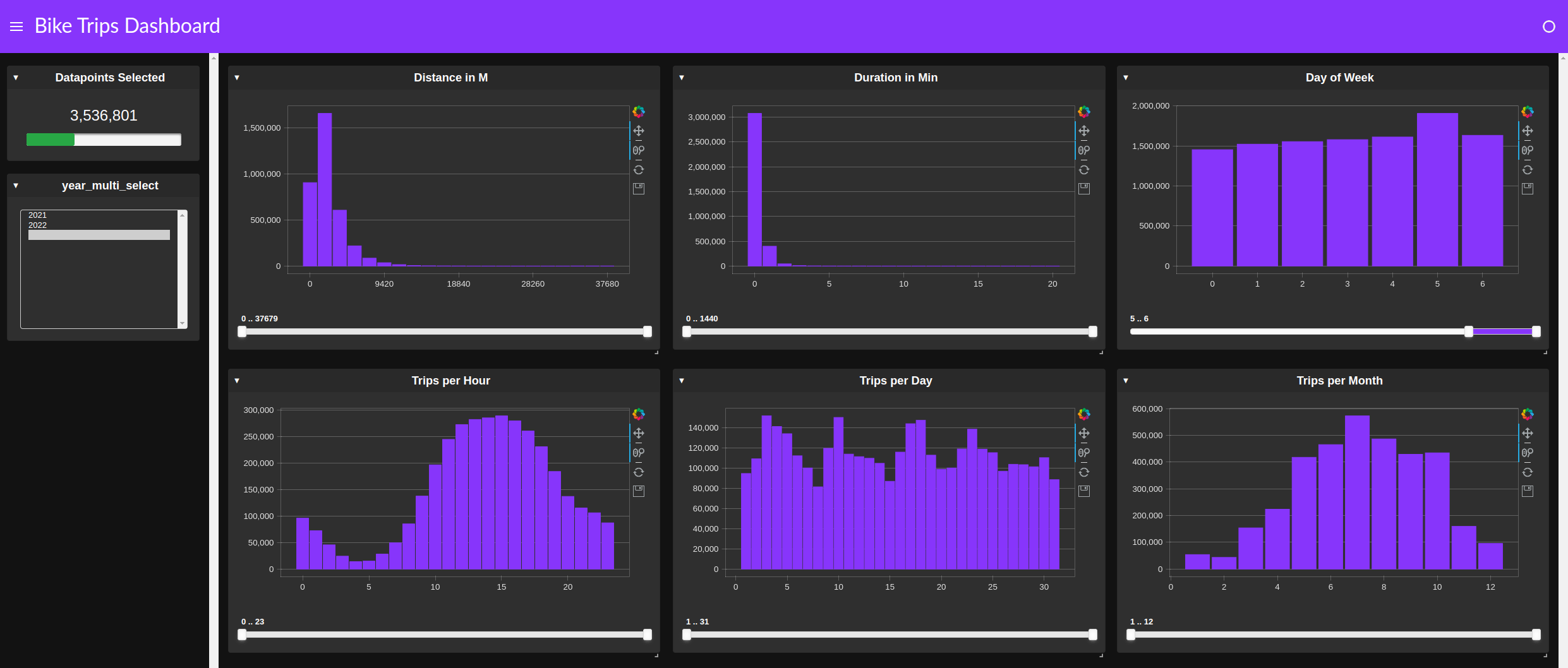
使用 cuxfilter 進行快速、基于交叉濾波器的探索是另一種可以節省時間的技術。這種方法用 GUI 工具代替了數據幀查詢。如圖 5 所示,在工作日和周末旅行之間,以及白天和晚上之間,出現了一種明顯的模式。
使用 Plotly Dash 構建強大的分析應用程序
在通過 EDA 流程對數據進行正確格式化和增強后,使其能夠更廣泛地被您的組織訪問和理解可能是一個挑戰。 Plotly Dash 使數據科學家能夠將復雜的數據機器學習工作流重新構建為更易于訪問的 web 應用程序。
因此,這款筆記本的發現被封裝在一個簡單易用、可訪問和可部署的 Plotly Dash 應用程序中。該應用程序使用 RAPIDS 提供的強大分析功能,但通過簡單的 GUI 進行控制。
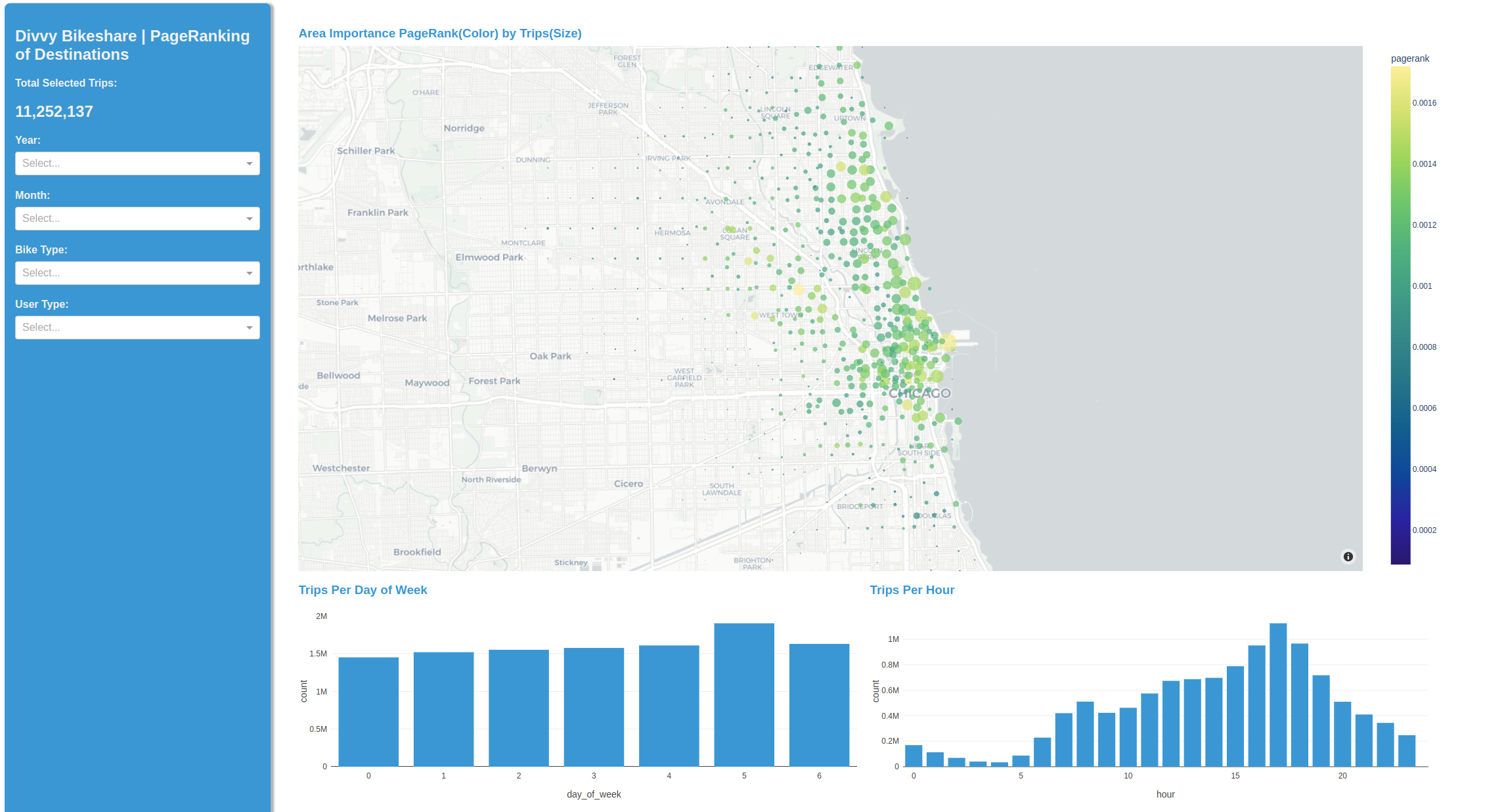
該實例使用 cuML K-means 將自行車起點和終點聚類為節點,并使用 cuGraph 的 PageRank 顯示每個節點的相對重要性。后者是針對每個周末工作日和之前發現的晝夜模式實時計算的。我們從原始的使用模式開始,現在提供了對特定用戶類型及其首選城市區域的交互式見解。
300M +人口普查數據點與 Plotly Dash 的亞秒交互
為了獲得更全面的 Plotly Dash 示例,我們使用 2020 年和移民數據更新了流行的人口普查可視化。圖 7 顯示了使用 cuDF 而不是 pandas 在數百萬個數據點上的交互性能優勢。要查看示例演示,請訪問 Google Colab 上的 Census 2020 可視化(使用 Plotly-Dash + RAPIDS)。要觀看完整的 3 億多數據集交互,請觀看 使用 RAPIDS cuDF 和 Plotly Dash 可視化人口普查數據。
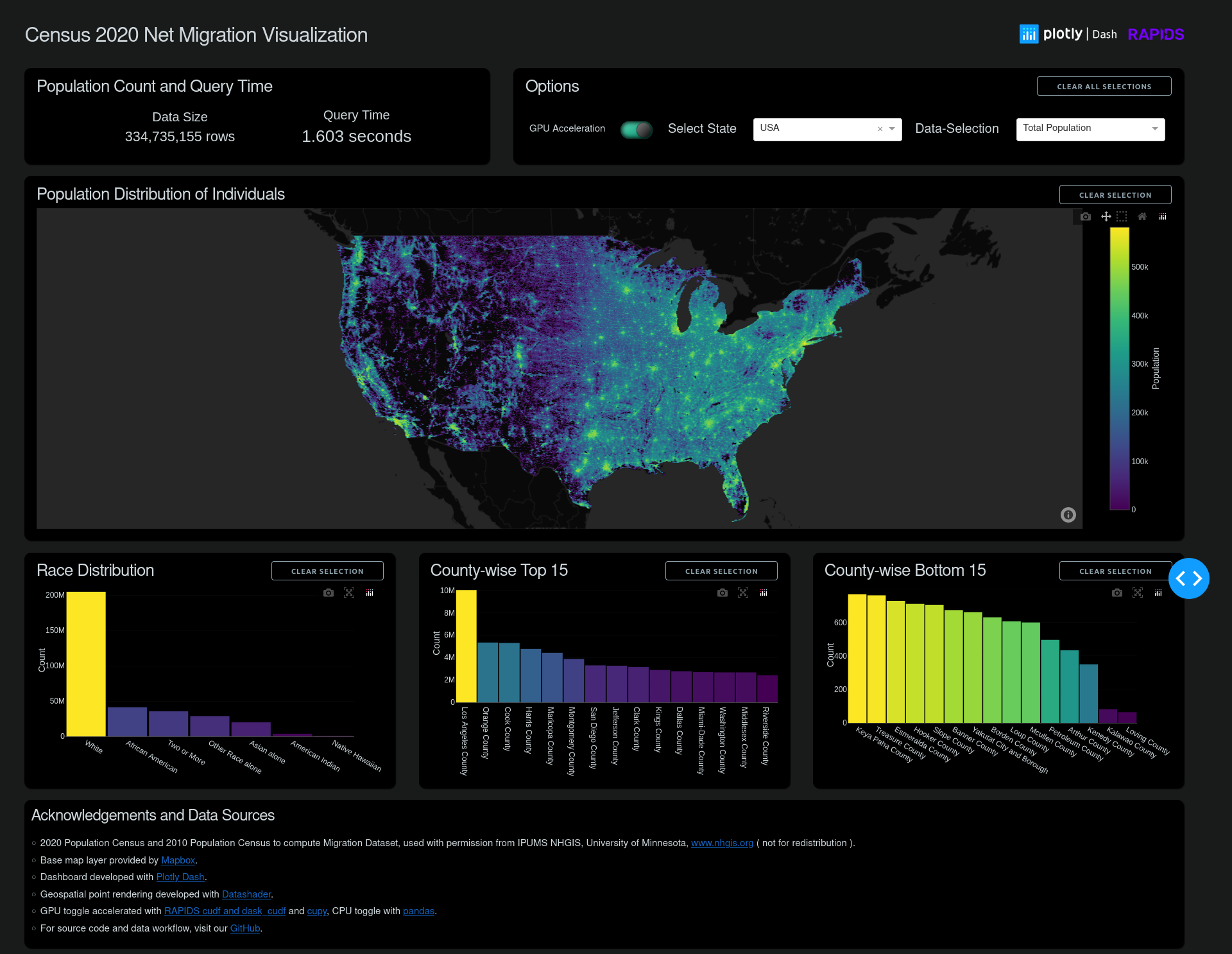
2020 年和 2010 年的人口普查數據來源于IPUMS NHGIS,明尼蘇達大學。為了更準確地反映美國全國人口的分布,將塊級數據擴展為隨機放置在其塊區域內的每個點,并進行計算以匹配塊級分布。表中列出了這些數據的幾種觀點,包括總人口和凈移民值。更多關于格式化數據的詳細信息,請訪問Plotly-Dash + RAPIDS Census 2020 Visualization GitHub 頁面。
使用強大的可視化功能,您可以忘記該工具,沉浸在探索數據中。在這種情況下出現了一些有趣的模式:
- 人口普查區塊邊界發生了變化,導致大型道路有自己的獨立區塊。這可能是一項新的努力的結果,以更好地反映未被使用的人口。
- 除了一些熱點地區外,東部各州的總體移民人數遠低于中西部和西部各州。
- 新的發展,特別是大型發展,特別容易發現,可以作為影響增長、土地利用和人口密度的區域政策之間的快速視覺比較。
以思維速度實現數據可視化
通過用 cuDF 等 RAPIDS 框架取代 pandas ,并利用其簡單性集成加速可視化框架,數據分析工作流程可以變得更快、更具洞察力、更高效,(只是可能)更令人愉快。
要了解有關加快數據科學工作流程的更多信息,請查看以下資源:
?




