這篇文章是 加速數據分析?系列文章的一部分:
- Accelerated Data Analytics: Faster Time Series Analysis with RAPIDS cuDF 帶您完成使用 RAPID cuDF 處理時間序列數據的常見步驟。
- 本帖 討論了 pandas 庫如何在 Python 中提供高效、富有表現力的函數。
氣候建模、醫療保健、金融和零售業的數字進步正在產生前所未有的數據量和類型。 IDC 表示,到 2025 年,將有 180 ZB 的數據,而 2020 年為 64 ZB ,這將擴大對數據分析的需求,將所有數據轉化為見解。
- 每天兩次的衛星圖像為 空氣質量 、 淹水 和 太陽耀斑?建模提供信息,以幫助識別自然風險。
- Advanced 基因組學 和 基因測序?提供了用見解編碼的遺傳數據池,可以使我們更接近癌癥的治愈。
- 數字購買 和網絡系統正在產生數 TB 的市場和 行為 數據。
NVIDIA 提供 RAPIDS 開源軟件庫和 API 套件,使數據科學家能夠完全在 GPU 上執行端到端的數據科學和分析管道。這包括使用我們的 DataFrame API : RAPIDS cuDF 進行分析和數據科學的常見數據準備任務。
在典型的數據分析工作流程中,速度高達 40 倍,加速的數據分析為您節省了時間,并增加了可能受到當前分析工具限制的迭代機會。
為了解釋加速數據分析的價值,我們在本文中使用 RAPIDS cuDF 進行了一個簡單的探索性數據分析( EDA )教程。
如果您現在使用 Spark 3.0 來處理大型數據集,請參閱 RAPIDS accelerator for Spark 。如果您現在已經準備好開始使用 RAPIDS ,請參閱 Step-by-Step Guide to Building a Machine Learning Application with RAPIDS 。
為什么 RAPIDS cuDF 適用于 EDA ?
如今,大多數數據科學家使用 pandas ,這是在 Python 之上構建的 popular 開源軟件庫,專門用于 EDA 任務的數據操作和分析。它的 flexible and expressive data structures 旨在使處理關系數據或標記數據變得簡單直觀,尤其是對于 EDA 等開放式工作流。
然而, pandas 被設計為在單核上運行,當數據大小達到 1-2GB 時,速度會開始減慢,這限制了它的適用性。如果數據大小超過 10-20 GB 的范圍,則應考慮使用 Dask 和 Apache Spark 等分布式計算工具。缺點是它們需要重寫代碼,這可能會成為采用的障礙。
對于 2-10 GB 的中間值, RAPIDS cuDF 是 Goldilocks 的解決方案。
RAPIDS cuDF 將計算并行到 GPU 中的多個核心,并抽象為類似 pandas 的API。 cuDF 的功能模仿了 pandas 中許多最流行和標準的操作,[ZBK9的運行方式與[ZBK5類似,但速度更快。將 RAPIDS 視為當前 pandas 工作負載的渦輪增壓按鈕。
帶有 RAPIDS cuDF 的 EDA
這篇文章展示了 cuDF 在采用 EDA 方法時是多么容易。
根據本文所述的操作,與 pandas 相比,我們觀察到使用 cuDF 時的操作速度提高了 15 倍。這種適度的收益可以幫助您在處理多個項目時節省時間。
有關進行時間序列分析的更多信息,請參閱 Exploratory Data Analysis Using cuDF GitHub 存儲庫中的完整筆記本 Exploratory Data Analysis Using cuDF 和 RAPIDS 。在整個工作流程中,觀察到的加速速度增加到了 15 倍。
數據集
Meteonet 是一個天氣數據集,匯集了 2016-2018 年巴黎各地氣象站的讀數。這是一個真實的數據集,有缺失和無效的數據。
分析方法
對于這篇文章,假設你是一名數據科學家,閱讀這些匯總數據并評估其質量。用例是開放式的;這些讀數可以用于報告、天氣預報或土木工程用例。
通過以下步驟構建您的分析以將數據置于情境中:
- 了解變量。
- 識別數據集中的差距。
- 分析變量之間的關系。
步驟 1. 了解變量
首先,導入 cuDF 庫并讀取數據集。要下載并創建 NW.csv ,其中包含西北站 2016 年、 2017 年和 2018 年的數據,請參閱 Exploratory Data Analysis Using cuDF 筆記本。
# Import cuDF and CuPy
import cudf
import cupy as cp
# Read in the data files into DataFrame placeholders
gdf_2016 = cudf.read_csv('./NW.csv')
查看數據集并了解您正在使用的變量。這有助于您了解 DataFrame 中數據的維度和類型。整個語法與 pandas 有相似之處。
使用. info 命令查看整個 DataFrame 結構,該命令與 pandas 中的命令相同:
GS_cudf.info()
<class 'cudf.core.dataframe.DataFrame'>
RangeIndex: 22034571 entries, 0 to 22034570
Data columns (total 12 columns):
# Column Dtype
--- ------ -----
0 number_sta int64
1 lat float64
2 lon float64
3 height_sta float64
4 date datetime64[ns]
5 dd float64
6 ff float64
7 precip float64
8 hu float64
9 td float64
10 t float64
object
dtypes: datetime64[ns](1), float64(9), int64(1), object(1)
memory usage: 6.5+ GB
從輸出中,觀察到了 12 個變量,您可以看到它們的標題。
要進一步了解數據,請確定 DataFrame 的整體形狀:逐行逐列。
# Checking the DataFrame dimensions. Millions of rows by 12 columns.
GS_cudf.shape
(65826837, 12)
在這一點上,數據集的維度是已知的,但每個變量的數據范圍是未知的。由于有 65826837 行,您無法一次可視化整個數據集。
相反,查看 DataFrame 的前五行,以檢查耗材樣本中的變量輸入:
# Display the first five rows of the DataFrame to examine details
GS_cudf.head()
| ? | number_sta | lat | lon | height_sta | date | dd | ff | precip | hu | td | t | psl |
| 0 | 14066001 | 49.33 | -0.43 | 2.0 | 2016-01-01 | 210.0 | 4.4 | 0.0 | 91.0 | 278.45 | 279.85 | <NA> |
| 1 | 14126001 | 49.15 | 0.04 | 125.0 | 2016-01-01 | <NA> | <NA> | 0.0 | 99.0 | 278.35 | 278.45 | <NA> |
| 2 | 14137001 | 49.18 | -0.46 | 67.0 | 2016-01-01 | 220.0 | 0.6 | 0.0 | 92.0 | 276.45 | 277.65 | 102360.0 |
| 3 | 14216001 | 48.93 | -0.15 | 155.0 | 2016-01-01 | 220.0 | 1.9 | 0.0 | 95.0 | 278.25 | 278.95 | <NA> |
| 4 | 14296001 | 48.80 | -1.03 | 339.0 | 2016-01-01 | <NA> | <NA> | 0.0 | <NA> | <NA> | 278.35 | <NA> |
表 1 。輸出結果
現在,您可以了解每一行包含的內容。有多少數據來源?看看收集所有這些數據的臺站數量:
# How many weather stations are covered in this dataset?
# Call nunique() to count the distinct elements along a specified axis.
number_stations = GS_cudf['number_sta'].nunique()
print("The full dataset is composed of {} unique weather stations.".format(GS_cudf['number_sta'].nunique()))
完整的數據集由 287 個獨特的氣象站組成。這些電臺多久更新一次數據?
## Investigate the frequency of one specific station's data
## date column is datetime dtype, and the diff() function calculates the delta time
## TimedeltaProperties.seconds can help get the delta seconds between each record, divide by 60 seconds to see the minutes difference.
delta_mins = GS_cudf['date'].diff().dt.seconds.max()/60
print(f"The data is recorded every {delta_mins} minutes")
每 6.0 分鐘記錄一次數據。氣象站每小時產生 10 個記錄。
現在,您了解了以下數據特征:
- 數據類型
- 數據集的維度
- 獲取數據集的來源數量
- 數據集更新頻率
然而,您仍然必須探究這些數據是否存在重大缺口,無論是數據輸入缺失還是無效。這些問題會影響這些數據是否可以單獨用作可靠的來源。
步驟 2. 確定差距
這些氣象站有多個傳感器。任何一個傳感器都可能在一年中出現故障或提供不可靠的讀數。一些缺失的數據是可以接受的,但如果監測站過于頻繁地關閉,這些數據可能會歪曲全年的真實情況。
要了解此數據源的可靠性,請分析數據丟失率和無效輸入的數量。
要評估數據丟失率,請將讀數數量與預期讀數數量進行比較。
數據集包括 271 個獨特的站點,每小時輸入 10 條記錄(每 6 分鐘輸入一條)。假設傳感器沒有停機時間,預計記錄的數據條目數量為 271 x 10 x 24 x 365 = 23739600 。但是,正如前面從. shape 操作中觀察到的那樣,您只有 22034571 行數據。
# Theoretical number of records is...
theoretical_nb_records = number_stations * (60 / delta_mins) * 365 * 24
actual_nb_of_rows = GS_cudf.shape[0]
missing_record_ratio = 1 - (actual_nb_of_rows/theoretical_nb_records)
print("Percentage of missing records of the NW dataset is: {:.1f}%".format(missing_record_ratio * 100))
print("Theoretical total number of values in dataset is: {:d}".format(int(theoretical_nb_records)))
Percentage of missing records of the NW dataset is: 12.7%
當對全年進行上下文分析時, 12.7% 表示每年約有 19.8 周的數據缺失。
你知道,在 36 個月中,大約有 5 個月的數據根本沒有被記錄下來。對于其他數據點,您有一些缺失的數據,其中記錄了一些變量,但沒有記錄其他變量。您在查看數據集的前五行時看到了這一點,其中包含 NA 。
要了解你有多少 NA 數據,首先要確定哪些變量有 NA 讀數。評估每個類別有多少無效讀數。在這部分分析中,將數據集縮減為僅考慮 2018 年的數據。
# Finding which items have NA value(s) during year 2018 NA_sum = GS_cudf[GS_cudf['date'].dt.year==2018].isna().sum() NA_data = NA_sum[NA_sum>0] NA_data.index StringIndex(['dd' 'ff' 'precip' 'hu' 'td' 't' 'psl'], dtype='object') NA_data dd 8605703 ff 8598613 precip 1279127 hu 8783452 td 8786154 t 2893694 psl 17621180 dtype: int64
您可以看到 PSL (海平面壓力)的缺失讀數數量最多。大約 80% 的總讀數沒有被記錄。在低端,降水有約 6% 的無效讀數,這表明傳感器是穩健的。
這兩個指標有助于您了解數據集中存在的差距以及在分析過程中需要依賴哪些參數。有關數據有效性每月變化的綜合分析,請參閱筆記本。
現在你已經很好地掌握了數據的樣子及其差距,你可以看看可能影響統計分析的變量之間的關系。
步驟 3. 分析變量之間的關系
所有 ML 應用程序都依賴于統計建模以及許多分析應用程序。對于任何用例,都要注意高度相關的變量,因為它們可能會扭曲結果。
對于這篇文章來說,分析氣象類別的讀數是最相關的。為整個 3 年數據集生成一個相關矩陣,以評估需要注意的任何依賴關系。
# Only analyze meteorological columns Meteo_series = ['dd', 'ff', 'precip' ,'hu', 'td', 't', 'psl'] Meteo_df = cudf.DataFrame(GS_cudf,columns=Meteo_series) Meteo_corr = Meteo_df.dropna().corr() # Check the items with correlation value > 0.7 Meteo_corr[Meteo_corr>0.7]
| ? | dd | ff | precip | hu | td | t | psl |
| dd | 1.0 | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> |
| ff | <NA> | 1.0 | <NA> | <NA> | <NA> | <NA> | <NA> |
| precip | <NA> | <NA> | 1.0 | <NA> | <NA> | <NA> | <NA> |
| hu | <NA> | <NA> | <NA> | 1.0 | <NA> | <NA> | <NA> |
| td | <NA> | <NA> | <NA> | <NA> | 1.0 | 0.840558357 | <NA> |
| t | <NA> | <NA> | <NA> | <NA> | 0.840558357 | 1.0 | <NA> |
| psl | <NA> | <NA> | <NA> | <NA> | <NA> | <NA> | ? |
在矩陣中,td(露點)和t(溫度)之間存在顯著的相關性。如果您正在使用任何假設變量是獨立的未來算法,如 linear regression ,請考慮這一點。你可以回到無效數據分析,看看其中一個是否比另一個有更多的缺失讀數作為選擇的指標。
經過基本的探索,您現在了解了數據的維度和變量,并查看了變量相關矩陣。還有更多的 EDA 技術,但本文中的方法是通用的,有一組任何數據科學家都熟悉的典型起點。正如您在整個教程中看到的那樣, cuDF 與 pandas 語法幾乎相同。
EDA 基準 RAPIDS cuDF
如前所述,這篇文章是完整筆記本中完整工作流程的簡化演練。在這篇文章中,我們觀察到了 9.55 倍的加速。這些結果是在 NVIDIA A6000 GPU 上實現的。
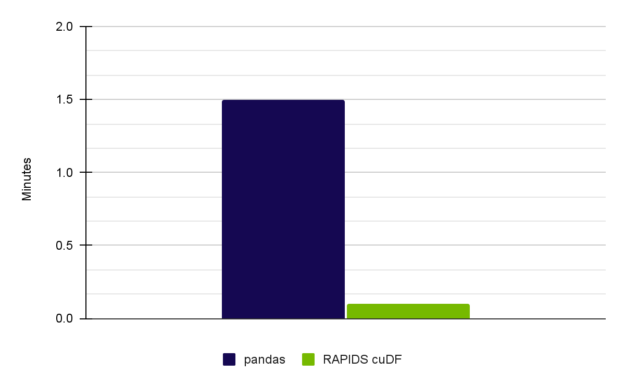
表 3 顯示了一個性能比較,包括本帖和完整筆記本的結果。
|
Full Notebook (15x speed-up) |
Pandas on CPU (Intel Core i7-7800X CPU) |
user 1 min 15 sec sys: 14.3 sec total: 1 min 30 sec |
|
RAPIDS cuDF on NVIDIA A6000 |
user 3.92 sec sys: 2.03 sec total: 5.95 sec |
表 3 。在 NVIDIA RTX A6000 GPU 上使用 RAPID cuDF 執行的 EDA 實現了 15 倍的加速
主要收獲
來自真實來源的真實數據存在差距、信息缺失和相關性,在對其進行建模以發展見解之前,必須解決這些問題。
通過觀察到的 15 倍的加速,您可以推斷出為更長、更復雜的工作負載節省的時間。如果運行 EDA 步驟需要 1 小時,那么您可以在 4 分鐘內完成這項工作。這讓您有 56 分鐘的時間來解決數據中不可預見的問題,完成數據處理,向該集合中再添加一年的數據以最大限度地減少差距,并開始設計數據集以適應您的用例。最棒的是,你可以重新控制自己的時間。
為了在探索性數據分析中進一步研究 cuDF ,請查閱完整的筆記本, Exploratory Data Analysis Using cuDF 。 Register for NVIDIA GTC 2023 for free ,并于 3 月 20-23 日加入我們的相關 data science sessions 。
要查看 cuDF 與時間序列數據的作用,請參見 Accelerated Data Analytics: Faster Time Series Analysis with RAPIDS cuDF 。
鳴謝
彭美然、 David Taubenheim 、 Sheng Luo 和 Jay Rodge 對此帖子做出了貢獻。
?