
云計算的出現使我們的數據存儲和利用實踐發生了范式轉變。企業可以通過利用云服務提供商巧妙管理的遠程按需資源,繞過管理自己的計算基礎設施的復雜性。然而,人們對與云共享敏感信息有著明顯的擔憂。
雖然 AES 等傳統加密方法有助于保護數據隱私,但它們扼殺了云對數據進行有意義操作的能力。在加密系統中,一種消息,也稱為明文,使用密鑰轉換為被稱為密文的加擾版本。現有的加密方法可以確保惡意實體在沒有正確密鑰的情況下無法解密消息,也無法訪問其內容。如果沒有解密,密文本質上是荒謬的。
幸運的是,有一個解決方案:全同態加密(FHE),一種復雜而有效的加密技術。無論是在傳輸中、靜止中還是在使用中,它都是數據的全面屏蔽。同態加密是一種獨特的設計,它能夠在保持密文安全的同時對密文執行操作。這種類型的操作修改密文的方式是,解密后,結果與對明文本身執行的操作相同。
FHE 通常被稱為密碼學的最終目標,它可以對密文執行任何計算功能。這項卓越的技術能夠直接在加密數據上運行數千種算法,而不會損害底層明文。它直面與云計算相關的關鍵隱私問題,同時實現復雜的外包計算。
然而,使用 FHE 加密執行的操作往往比使用標準未加密數據執行的操作慢。此外,對于非專業人員來說,這項技術的當前應用可能對有效設置和管理具有一定的挑戰性。
ArctyrEX:加速加密執行
NVIDIA Research 的最近一項努力旨在解決與加密計算相關的效率問題。他們提出的解決方案,ArctyrEX,是一個端到端的框架,使您能夠在 C++ 中使用標準數據類型來指定算法,并自動將此算法轉換為 FHE 表示,該表示可以在任意數量的 GPU 上啟動,以進行有效評估。
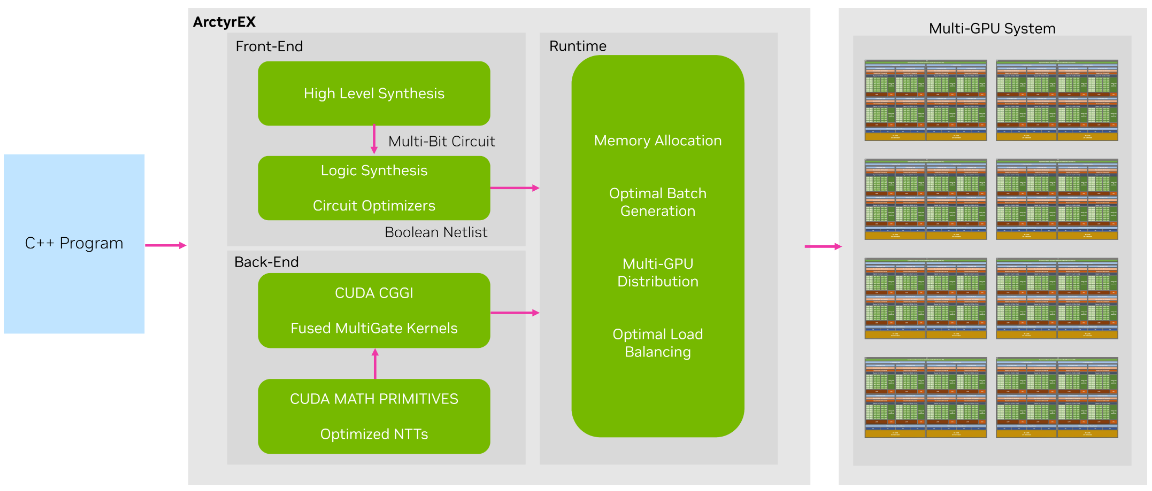
ArctyrEX 由三部分組成:
- 負責將輸入程序轉換到加密域的前端
- 一個運行庫,用于向 GPU 工作者發送加密的工作負載
- 由最先進的 CGGI 密碼系統的實現組成的后端。
CGGI 密碼系統可以對明文的單個比特進行加密,并實現密文之間的加密布爾運算。因此,CGGI 的編程模型類似于構造由邏輯門組成的布爾電路。想要了解更多詳細信息,請參閱 TFHE: Fast Fully Homomorphic Encryption over the Torus 和 TFHE。
前端利用數十年的硬件開發研究,將 C++程序轉換為等效的 Verilog 文件,這些文件提供了高抽象級別的電路描述。然后它將文件轉換為最佳布爾回路。該過程使用高級合成(HLS)和寄存器傳輸級(RTL)或邏輯合成形式的成熟技術。
ArctyrEX 運行庫采用生成的布爾電路,將其劃分為不同的級別,并創建大小大致相同的批以分發給 GPU 工作者。在某些情況下,與中間級別的門的輸出線相對應的密文可能必須在下一級別期間用作分配給不同 GPU 的工作負載的輸入。ArctyrEX 能夠無縫高效地協調這些傳輸。
最后,ArctyrEX 后端由一個優化的 CUDA 內核組成,該內核能夠同時執行多批門,同時最大限度地減少 CPU – GPU 同步。輸出由一組密文組成,這些密文表示指定批次中的門的輸出線。
使用 ArctyrEX 運行程序的速度高達 40 倍
ArctyrEX 通過使用更多 GPU 顯示出強大的可擴展性,主要有兩個原因:
- 大量的基元級并行這是大多數 FHE 操作的自然特征。
- 電路級并行性,這是布爾電路中通常顯示的特性。
為了用布爾 FHE 實現快速評估,電路必須具有寬的電平,這意味著應該有許多門可以同時操作,并且它應該具有最小的臨界路徑。為了說明這一點,將兩個矢量之間的加密點積運算與加密矢量相加運算進行比較。
要在 ArctyrEX 中實現這些程序,您可以以直觀的方式編寫高級 C++ 代碼。在這里,pragma 是在 HLS 傳遞之前展開循環所必需的 XLS,其目標是使數字設計更易于接近和高效。XLS 提供了一種在比傳統硬件描述語言(如 Verilog 或 VHDL)更高級別(如 C++)指定數字邏輯的方法,使整個過程更簡單、更高效。
例如,觀察兩個矢量之間的加密點積和加密矢量相加之間的差異。要在 ArctyrEX 中實現這些程序,您可以通過以下方式直觀地編寫高級 C++代碼,其中需要 pragma 在 Google XLS 處理的 HLS 傳遞之前展開循環:
void vector_addition(int x[500], int y[500], int z[500]) { #pragma hls_unroll yes for (int i =0; i < 500; i++) z[i] = x[i] + y[i];}short dot_product(short x[500], short y[500]) { short product = 0; #pragma hls_unroll yes for (int i = 0; i < 500; i++) Product = product + x[i] * y[i]; return product; } |
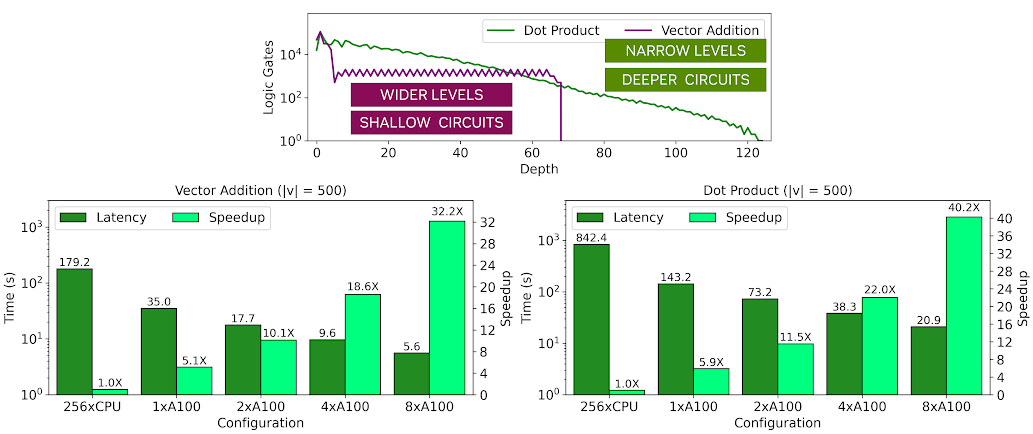
圖 3 顯示了兩個電路的特性,特別是電路每一級的邏輯門數量。在圖表中,|v|表示向量長度,M 表示矩陣的維數。你可以看到,兩個矢量的點積具有更高的臨界路徑,深度約為 120 個電平,隨后電平的寬度逐漸減小,限制了電路后期可能利用的并行性。
另一方面,矢量加法的臨界路徑比點積短大約 2 倍,并且每個級別的寬度保持相對恒定。因此,矢量相加的速度比點積快約 4 倍,盡管兩者在具有多個 GPU 的平行 CPU 基線上都表現出高加速。這些有趣的性能趨勢顯示在前面的拓撲圖中。淺綠色條顯示相對于 256 線程 CPU 基線的加速,而深綠色條顯示同態應用程序的執行時間。
總結
總之,ArctyrEX 代表了一個跨各種應用程序的加密計算的綜合解決方案,利用 GPU 加速的力量,并實現了高效 FHE 算法執行的創新技術。神經網絡推理等任務隨著 GPU 的增加而表現出線性加速,這歸因于固有的電路級并行性、新引入的調度范式以及 CUDA 加速的 CGGI 后端所利用的廣泛的原始級并行性。
想要獲取詳細信息,請參閱 “Accelerated Encrypted Execution of General-Purpose Applications” 論文,以及 NVIDIA GTC 2023 的現場演示 “ArctyrEX: Accelerated Encrypted Execution of General-Purpose Applications on GPUs”。
鳴謝
我們感謝 ArctyrEX 的所有作者的貢獻,特別是 Charles Gouert(博士候選人)和特拉華大學的 Nektarios Georgios Tsoutsos 教授。我們還要感謝 Zama、CryptoLab、谷歌和 Duality Tech 的成員進行的富有洞察力的討論,特別是 Ilaria Chillotti、Jung Hee Cheon、Ahmad Al Badawi、Yuri Polyakov、David Cousins、Shruti Gorantala 和 Eric Astor。
?









