Python 對數據科學家來說并不陌生。它是最流行的計算機語言,廣泛用于各種任務。盡管 Python 在運行時解釋代碼時速度非常慢,但對于某些數據科學工作,許多流行的庫使其在 GPU 上高效運行。例如,TensorFlow和PyTorch等流行的深度學習框架可以幫助 AI 研究人員高效地運行實驗。然而,在某些領域,如投資組合優化,沒有 Python 庫可以輕松加速計算工作。開發人員必須從頭開始實現算法,才能在 GPU 上加速。
在這篇文章中,我們將展示如何使用 Numba 和Dask將投資組合構建算法加速 800x ,如以前的博客中介紹的那樣。
介紹工具+用例
Numba 是一個 cuDF 庫,它簡化了 GPU 算法與 Python 的實現。 Python GPU 內核可以編譯為在 GPU 上運行。它使 CUDA 的編寫更易于 Python 開發人員使用。對于不適合單個 GPU 的較大問題,我們使用Dask在 GPU 的集群中進行分布式計算。 Dask 與 Python 、 pandas 、 cuDF 、 CuPy 等 Python 庫集成良好。它使用相同的 API 和數據結構,因此 Python 開發人員可以輕松地選擇它。
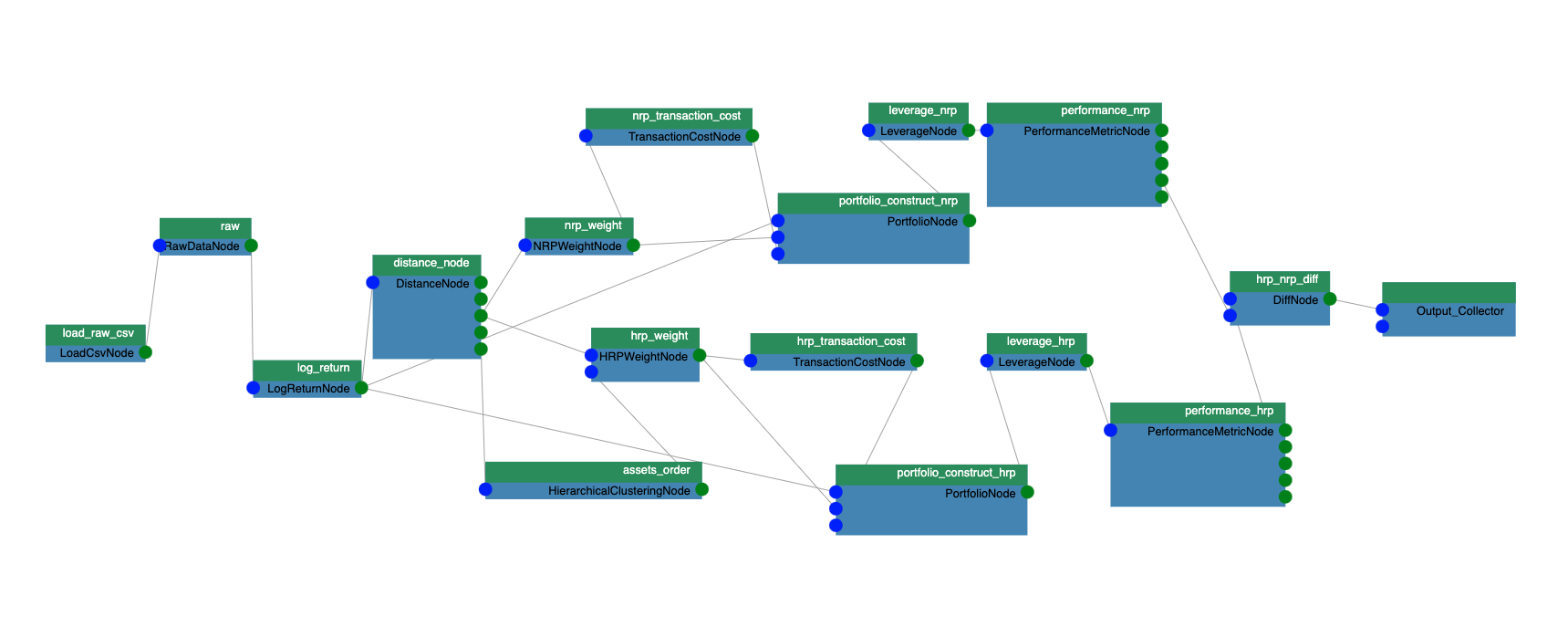
投資組合構建算法用于計算構建投資組合的最佳權重。這是基金經理管理資產必須執行的最重要步驟之一。如圖 1 所示,以前的博客中的用例包括以下步驟:加載資產每日價格的 csv 數據
- 運行 block bootstrap 生成 100k 個不同的場景。
- 計算每個場景的日志返回。
- 計算資產距離以運行分層聚類和資產的分層風險平價( HRP )權重
- 根據天真的風險平價( NRP )方法計算資產的權重。
- 根據重新平衡日的權重調整計算交易成本。
- 在每個再平衡日期,計算投資組合杠桿以達到波動率目標。
- 計算這兩種方法( HRP-NRP )的平均年回報率、標準回報率、夏普比、最大資金回挫和平靜比績效指標。
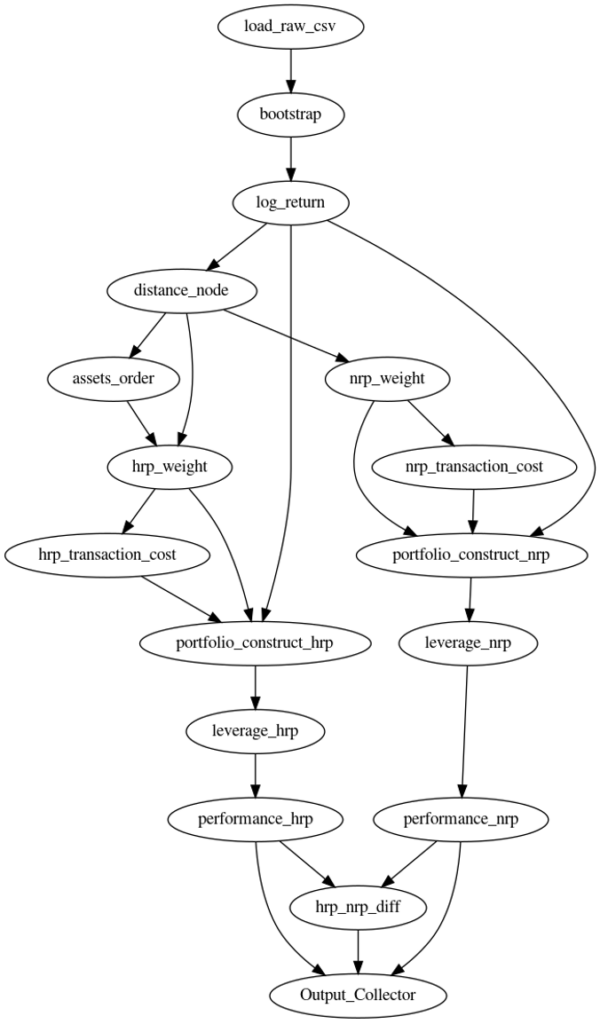
圖 1 :投資組合構造算法的計算圖。
前面的計算涉及很多步驟。為了在 GPU 上加速它們,我們需要確定的最重要的事情是并行的粒度。
有些步驟,如HRP 算法,本質上是串行的。它重新組織股票回報的協方差矩陣,以便將類似的投資放在一起。然后,基于聚類協方差通過遞歸二分法進行分配。我們 MIG ht 能夠對 HRP 算法的幾個步驟進行矢量化,但是,由于只使用了較少數量的并行線程,因此速度提升將是最小的。
由于生成的場景彼此獨立且數量龐大,因此在場景級別應該有一種更好的并行方法。使用多個 GPU 線程計算不同的場景。我們將詳細描述如何在 Numba GPU 內核中執行塊引導計算。
Bootstrapped 數據集用于解釋時間序列未來收益的非平穩性。通過使用替換塊對數據塊進行采樣來重構與原始時間序列長度相同的時間序列,從而構建新的收益時間序列。每個區塊都有一個固定的長度,但從期貨收益時間序列中定義了一個隨機的時間起點。我們選擇使用 60 個工作日的區塊。這種區塊長度是由基于規則的動態策略的典型月度或季度再平衡頻率以及在此時間尺度上發生的經驗市場動態所驅動。Papenbrock 和 Schwendner( 2015 )發現多資產相關性模式以幾個月的典型頻率變化。
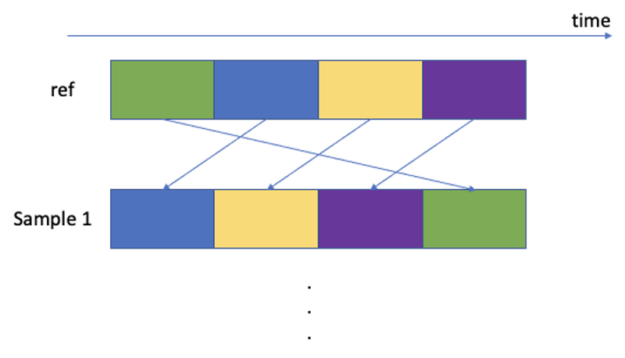
下面是從參考價格矩陣中采樣塊的 Numba 內核。請注意“@ CUDA . jit ” decorator ,它告訴 Numba 及時編譯boot_strap內核。
@cuda.jit
def boot_strap(result, ref, block_size, num_positions, positions):
sample, assets, length = result.shape
i = cuda.threadIdx.x
sample_id = cuda.blockIdx.x // num_positions
position_id = cuda.blockIdx.x % num_positions
sample_at = positions[cuda.blockIdx.x]
for k in range(i, block_size*assets, cuda.blockDim.x):
asset_id = k // block_size
loc = k % block_size
if (position_id * block_size + loc + 1 < length):
result[sample_id, asset_id, position_id * block_size +
loc + 1] = ref[asset_id, sample_at + loc]
由于股票價格是非平穩的,股票價格時間序列數據首先轉換為對數收益。它用作參考矩陣,我們在其中對隨機塊進行采樣。它是核函數中的’ ref ‘參數,其維度為[assets , time]。“ result ”參數是引導抽樣的結果,其維度為[sample , assets , time]。“ block _ size ”定義了塊的大小,該大小為 60 個工作日` num _ positions `是覆蓋整個時間長度所需的塊數。其計算公式為:
num_positions = (length - 2) // block_size + 1` sample _ positions `是范圍為[0 , length – block _ size]的隨機時間數組,表示塊的隨機采樣開始時間` sample _ positions ‘的大小為’ samples * num _ positions ‘。對于每個樣本,我們需要對塊的’ num _ positions ‘進行采樣以覆蓋整個時間長度,因此每個塊都可以通過一個元組( sample _ id , position _ id )進行標識,其中 position _ id 在[0 , num _ positions]范圍內。
我們將每個 GPU 線程塊映射到由元組( sample _ id , position _ id )標識的不同采樣時間塊。下面是將線程塊 id CUDA . blockIdx . x 映射到塊 id 元組(示例 id 、位置 id )的公式。
sample_id = cuda.blockIdx.x // num_positions
position_id = cuda.blockIdx.x % num_positions線程塊內的線程用于將數據元素移動到結果矩陣。需要移動的數據元素有兩個維度:資源和塊內的時間位置。下面是將線程 id 映射到資源 id 和時間位置的公式。
asset_id = k // block_size
loc = k % block_size要啟動 Numba 內核,我們可以使用以下 Python 方法:
boot_strap[(number_of_blocks,), (number_of_threads,)](output,
ref,
block_size,
num_positions,
sample_positions)將學到的經驗教訓應用到管道的其余部分
其余的計算步驟遵循與塊引導步驟類似的模式。例如,在計算協方差距離時,我們確定每個再平衡時間段彼此獨立。因此,并行的粒度處于引導場景和重新平衡間隔的級別。我們將線程塊 id 映射到樣本 id 和重新平衡時間。線程塊中的線程用于移動數據元素和進行并行計算(并行 CUDA 求和、排序等)。要查看實施的詳細信息,請參閱 github 回購協議:https://github.com/NVIDIA/fsi-samples/tree/main/gQuant/plugins/hrp_plugin
Numba適用于在單個 GPU 中加速算法。我們可以在單個V100 32G GPU 中并行運行4096個場景。但是,要運行10萬個場景,它無法在單個 GPU 中運行。Dask是一個 Python 庫,可用于加速 GPU 群中的算法。如前所示,我們已經實現了一個函數,該函數在 GPU CuPy數組中輸出與 NumPy 數組類似的采樣場景。首先,我們使用RAPIDS cuDF 庫以零拷貝方式將其轉換為 GPU 數據幀。Dask提供了一個“Dask.delayed”method,可以對該函數進行注釋,以便將其構造成Dask計算圖。通過調用這個延遲函數100k/4096次,我們可以通過’dask.DataFrame.from_delayed’方法將結果作為dask_ZBK9]數據幀。注意,這只會延遲地構造Dask計算圖,計算由“compute”或“persist”方法觸發。以下步驟將此dask_ZBK9]數據幀作為輸入,并使用“dask.map_partition”方法對每個數據幀分區進行計算,就像它們正在處理單個 cuDF 數據幀一樣。Dask可以智能地調度 GPU 資源,以并行完成所有計算。
結論
在這篇文章中,我們描述了如何用 Numba / Dask 實現一個投資組合構造算法。此方法在 GPU 上提供高達 800 倍的速度提升,這對慕尼黑再保險公司產生了重大的業務影響。我們使用了類似的 Numba / Dask 方法來加速 GPU 上的回溯測試算法,這幫助我們贏得了STAC A3 基準。希望這篇文章能啟發您重新審視現有代碼,并開始思考如何在 GPU 上加速它。
參照
- http://numba.pydata.org/
- https://dask.org/
- https://papers.ssrn.com/sol3/papers.cfm?abstract_id=2254272
- STAC 報告:在 NVIDIA DGX-2 上使用 Python | STAC – I NSight 對算法企業| STAC 進行 STAC-A3 (回溯測試)( stacsearch . com )
?






