
模擬或 合成數據 生成是人工智能工具發展的一個重要趨勢。傳統上,這些數據集可用于解決低數據問題或邊緣情況場景,而或許現在存在于可用的實際數據集中。
合成數據的新興應用包括建立模型性能水平、量化適用領域,以及下一代系統工程,其中人工智能模型和傳感器是串聯設計的。

Blender 是生成這些數據集的一個常用且引人注目的工具。它是免費使用和開源的,但同樣重要的是,它可以通過強大的 Python API 完全擴展。 Blender 的這一特性使其成為視覺圖像渲染的一個有吸引力的選擇。因此,它已被廣泛用于此目的,有 18 +渲染引擎選項可供選擇。
集成到 Blender 中的渲染引擎(如 Cycles )通常具有緊密集成的 GPU 支持,包括最先進的 NVIDIA RTX 支持。但是,如果在可視化渲染引擎之外需要高性能級別,例如合成 SAR 圖像的渲染,那么 Python 環境對于實際應用程序來說可能過于遲緩。加速這段代碼的一個選擇是使用流行的 Numba 包將 Python 代碼的部分預編譯成 C 。然而,這仍有改進的余地,特別是在采用領先的 GPU 體系結構進行科學計算方面。
GPU 科學計算功能可直接從 Blender 中獲得,允許使用簡單的統一工具,利用 Blender 強大的幾何體創建功能以及尖端計算環境。對于 blender2 . 83 +的最新變化,可以使用 CuPy (一個專門用于數組計算的 GPU 加速 Python 庫)直接從 Python 腳本中完成。
根據這些想法,下面的教程將比較兩種不同的加速矩陣乘法的方法。第一種方法使用 Python 的 Numba 編譯器,而第二種方法使用 NVIDIA GPU-compute API, CUDA 。這些方法的實現可以在 rleonard1224/matmul GitHub repo 中找到,還有一個 Dockerfile ,它設置了 anaconda 環境,從中可以運行 CUDA – 加速的 Blender Python 腳本。
矩陣乘法算法
作為討論用于加速矩陣乘法的不同方法的前奏,我們簡要回顧了矩陣乘法本身。
對于兩個矩陣的乘積![[A \cdot B]](https://s0.wp.com/latex.php?latex=%5BA+%5Ccdot+B%5D&bg=ffffff&fg=000&s=0&c=20201002)
![[A]](https://s0.wp.com/latex.php?latex=%5BA%5D&bg=ffffff&fg=000&s=0&c=20201002)
![[B]](https://s0.wp.com/latex.php?latex=%5BB%5D&bg=ffffff&fg=000&s=0&c=20201002)
行和
列,即
matrix.
matrix.
- 產品
結果是
matrix.
如果![[C]](https://s0.wp.com/latex.php?latex=%5BC%5D&bg=ffffff&fg=000&s=0&c=20201002)
![[C[i,j]]](https://s0.wp.com/latex.php?latex=%5BC%5Bi%2Cj%5D%5D&bg=ffffff&fg=000&s=0&c=20201002)
![[C[i,j] = \Sigma_{r = 1}^{n} A[i,r] \cdot B[r,j]]](https://s0.wp.com/latex.php?latex=%5BC%5Bi%2Cj%5D+%3D+%5CSigma_%7Br+%3D+1%7D%5E%7Bn%7D+A%5Bi%2Cr%5D+%5Ccdot+B%5Br%2Cj%5D%5D&bg=ffffff&fg=000&s=0&c=20201002)
麻木加速度
通過使用 Numba . jit decorator ,可以將 Numba 編譯器應用于 Python 腳本中的函數。通過預編譯到 C 中,在 Python 代碼中使用 numba . jit decorator 可以顯著減少循環的運行時間。由于直接轉換為代碼的矩陣乘法需要嵌套 for 循環,因此使用 numba . jit decorator 可以顯著減少用 Python 編寫的矩陣乘法函數的運行時間。 matmulnumba.py Python 腳本實現矩陣乘法并使用 numba . jit decorator 。
CUDA 加速度
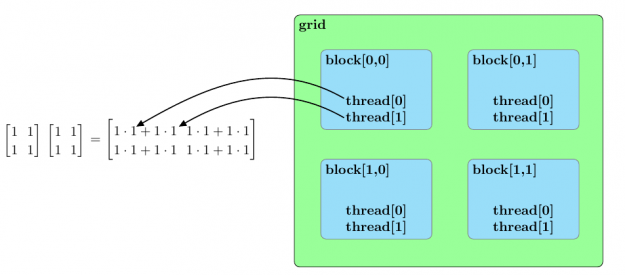
在討論使用 CUDA 加速矩陣乘法的方法之前,我們應該大致概述 CUDA 內核的并行結構。內核啟動中的所有并行進程都屬于一個網格。網格由塊數組組成,每個塊由線程數組組成。網格中的線程組成了由 CUDA 內核啟動的基本并行進程。圖 2 概述了這類并行結構的示例。

既然已經詳細說明了 CUDA 內核啟動的并行結構,那么在 matmulcuda.py Python 腳本中用于并行化矩陣乘法的方法可以描述如下。
假設以下由一個由塊的二維數組組成的 CUDA 內核網格計算,每個塊由線程的一維數組組成:
- 矩陣積
此外,進一步假設如下:
- 網格 x 維中的塊數 (
) 大于或等于
).
- 網格 y 維中的塊數 (
) 大于或等于
(
).,
- 每個塊中的線程數 (
) 大于或等于
).
矩陣積的元素
您可以通過將指定給要執行的塊的每個線程來獲得進一步的并行增強
為了避免競爭條件,這些atomicAdd 函數處理。 atomicAdd 函數簽名由作為第一個輸入的指針和作為第二個輸入的數值組成。該定義將輸入的數值與第一個輸入所指向的值相加,然后將該和存儲在第一個輸入所指向的位置。
假設![[\textrm{tid}(i,j)]](https://s0.wp.com/latex.php?latex=%5B%5Ctextrm%7Btid%7D%28i%2Cj%29%5D&bg=ffffff&fg=000&s=0&c=20201002)
![[[i,j]]](https://s0.wp.com/latex.php?latex=%5B%5Bi%2Cj%5D%5D&bg=ffffff&fg=000&s=0&c=20201002)
![[C[i,j] = \textrm{atomicAdd}(C[i,j], A[i, \textrm{tid}(i,j)] \cdot B[\textrm{tid}(i,j), j])]](https://s0.wp.com/latex.php?latex=%5BC%5Bi%2Cj%5D+%3D+%5Ctextrm%7BatomicAdd%7D%28C%5Bi%2Cj%5D%2C+A%5Bi%2C+%5Ctextrm%7Btid%7D%28i%2Cj%29%5D+%5Ccdot+B%5B%5Ctextrm%7Btid%7D%28i%2Cj%29%2C+j%5D%29%5D&bg=ffffff&fg=000&s=0&c=20201002)
圖 3 總結了兩個樣本矩陣乘法的并行排列![[2 \times 2]](https://s0.wp.com/latex.php?latex=%5B2+%5Ctimes+2%5D&bg=ffffff&fg=000&s=0&c=20201002)
提速
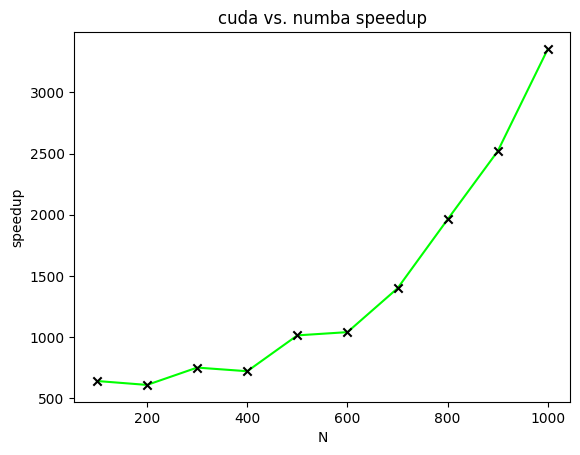
圖 4 顯示了 CUDA 加速矩陣乘法相對于不同大小矩陣的 Numba 加速矩陣乘法的加速比。在該圖中,繪制了加速比以計算兩個![[N \times N]](https://s0.wp.com/latex.php?latex=%5BN+%5Ctimes+N%5D&bg=ffffff&fg=000&s=0&c=20201002)
![[N]](https://s0.wp.com/latex.php?latex=%5BN%5D&bg=ffffff&fg=000&s=0&c=20201002)
今后的工作
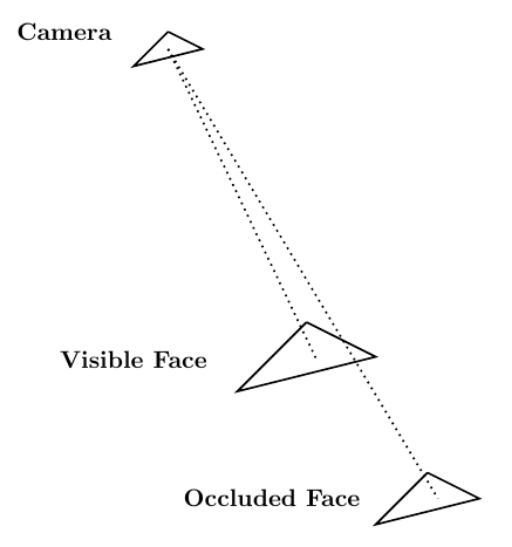
考慮到 Blender 作為計算機圖形工具的作用,一個適用于 CUDA 加速的相關應用領域涉及到通過光線跟蹤解決可見性問題。可見性問題可以概括如下: 相機存在于空間的某個點上,并且正在觀察由三角形元素組成的網格。可見性問題的目標是確定哪些網格元素對攝影機可見,哪些網格元素被其他網格元素遮擋。
光線跟蹤可以用來解決可見性問題。您試圖確定其可見性的網格由
每條光線在不同的網格元素上都有一個端點。如果光線到達其端點時未被其他網格元素遮擋,則可以從攝影機中看到端點網格元素。圖 5 顯示了這個過程。
使用光線跟蹤來解決可見性問題的本質使其成為![[\mathcal{O}(N^{2})]](https://s0.wp.com/latex.php?latex=%5B%5Cmathcal%7BO%7D%28N%5E%7B2%7D%29%5D&bg=ffffff&fg=000&s=0&c=20201002)
概括
這篇文章描述了兩種不同的加速矩陣乘法的方法。第一種方法使用 Numba 編譯器來減少 Python 代碼中與循環相關的開銷。第二種方法使用 CUDA 并行化矩陣乘法。速度比較證明了 CUDA 在加速矩陣乘法方面的有效性。
因為前面描述的 CUDA 加速代碼可以作為 Blender Python 腳本運行,所以可以在 Blender Python 環境中使用 CUDA 加速任意數量的算法。這大大提高了 blenderpython 作為科學計算工具的有效性。
如果您有任何問題或意見,請在下面發表意見或聯系我們 info @ rendered . ai .





