隨著 AI 、 ML 和 HPC 應用程序的計算從 CPU 轉移到更快的 GPU ,輸入輸出 GPU 的 IO 可能成為整體應用程序性能的主要瓶頸。
NVIDIA 創建了 Magnum IO GPU 直接存儲( GDS ),以簡化存儲和 GPU 內存之間的數據移動,并消除平臺中的性能瓶頸,例如被迫通過 CPU 內存中的緩沖區存儲和轉發數據。
GDS 通過在本地 NVMe 存儲或 NIC 后面的遠程存儲和 GPU 內存之間啟用直接內存訪問( DMA ),提高了帶寬,減少了延遲,減輕了 CPU 利用率的負擔。從 DGX 平臺上的 GDS 本身的深度學習推理、數據分析可視化和視頻分析中分別觀察到 2 . 5x 、 8x 和 9x 的性能優勢。

要在部署的平臺范圍內加速各種各樣的客戶應用程序和框架,需要一系列合作關系。我們的目標是實現整個豐富的數據存儲生態系統,該生態系統由近 180 家軟件和硬件供應商以及 2500 多個貢獻者組成。有關更多信息,請參閱SNIA網站。
本文概述了 GDS 合作生態系統,并分享了我們合作伙伴的最新成果。
GDS 生態系統
NVIDIA 尋求一個開放的生態系統,與供應商、框架開發人員和最終客戶建立越來越多的合作伙伴關系。自 GPU Direct Storage 的 1 . 0 產品發布以來,合作伙伴供應商的生態系統已經發展,如表 1 所示。
每個類別中的項目按時間順序排列。尚未發布的項目和正在開發的項目均為斜體。以黃色突出顯示的項目具有自本系列最后一篇 GDS 文章發布以來的新數據。
| Vendor partners | Frameworks and applications | Systems software |
| File systems – DDN EXAScaler – Weka FS – VAST NFSoRDMA – EXT4 via NVMe or NVMoF drivers from MLNX_OFED – IBM Spectrum Scale (GPFS) – DELL Technologies PowerScale – NetApp/SFW/BeeGFS – NetApp/NFS – HPE Cray ClusterStor Lustre Block systems – Excelero – ScaleFlux smart storage |
Storage -HDF5 – ADIOS – OMPIO Deep learning – PyTorch – MXNet Data analytics – cuDF – DALI – Spark – cuSIM/Clara – NVTabular Databases – HeteroDB for PostgreSQL acceleration Visualization – IndeX |
– Ubuntu 18.04 – Ubuntu 20.04 – RHEL 8.3 – RHEL 8.4 – DGX BaseOS Compatibility mode only: – Debian 10 – RHEL7.9 – CentOS 7.9 – Ubuntu 18.04 (desktop) – Ubuntu 20.04 (desktop) – SLES 15.2 – OpenSUSE 15.2 |
| Contributions to a repo | Systems vendors | Media vendors |
| Readers – Serial HDF5 – IOR Containers – PyTorch/DALI Samples – Transparent threading – Buffer agnostic |
– Dell – Hitachi – HPE – IBM – Liqid – Pavilion |
– Kioxia – Micron – Samsung – Western Digital |
供應商合作伙伴
我們有幾種不同類型的供應商合作伙伴,他們的產品具有不同的成熟度。供應商合作伙伴分為兩類:直接參與 GDS 軟件支持的合作伙伴和提供系統和組件解決方案的合作伙伴。
GDS 支持合作伙伴全面提供
本節涵蓋了那些積極地使英偉達 GPU 直接存儲到他們擁有的軟件棧中的合作伙伴,滿足 NVIDIA 基本功能和性能標準,并將其集成到一般可用性的生產解決方案中。

- DDN 將 GDS 集成到基于 Lustre 的 EXAScaler 并行文件系統中。他們正在與社區合作,將 GDS 支持上游到開源發行版。
- Dell Power Scale 是 NFS 的優化實現。
- IBM Spectrum Scale ,以前稱為 GPFS ,是 HPC 、數據和 AI 中廣泛使用的分布式并行文件系統。
- 龐大的并行分布式文件系統開創了通過 RDMA ( NFSoRDMA )提供多路徑 NFS 的先河。 VAST 還使 nconnect 中 NFSoRDMA 中的 GDS 在將來的上游版本中可用。
- Weka 將 GDS 集成到自己的 Weka FS 并行分布式文件系統中。
解決方案和組件提供商全面提供
一些供應商對 GDS 的支持處于通用可用性級別。一些供應商提供軟件解決方案,對代碼進行更改以啟用 GDS ,而其他供應商則是已經或將要使用 GDS 的組件或系統供應商。
提供硬件或 GDS 特性數據的供應商
NVIDIA 與我們的 NPN 和 GPU 直接存儲合作伙伴密切合作,以鑒定 GDS 的全部功能。他們還使用硬件和軟件解決方案,結合 NVIDIA 帶來的最佳 GPU 加速技術,量化測量的性能增益。這些措施包括:。
使用其他支持 GDS 的解決方案(如 MLNX _ OFED 中提供的解決方案)提供完整端到端解決方案的系統供應商合作伙伴包括:

- 數字數據網
- 戴爾科技
- 惠普企業
- 國際商用機器公司
- 亭閣
- 巨大的
與我們合作最密切的組件供應商包括:

- 基奧西亞
- 微米
- 桑孫
- 標度通量
表達興趣的供應商
對 GDS 表示強烈興趣的其他供應商包括:
- 日立
- 輕盈
- 西部數字
開發中的 GDS 支持合作伙伴
有些合作伙伴的產品可供您評估,但尚未達到全面可用的成熟期:

- BeeGFS 并行分布式文件系統是 HPC 中常用的文件系統。 System Fabric Works 一直在與 NetApp 合作為 BeeGFS 啟用 GDS 。
- Excelero NVMesh 將任何網絡上的 NVMe 驅動器轉換為支持任何本地或分布式文件系統的企業級受保護共享存儲。
- HPE 促成了 Cray ClusterStor E1000 Storage System中使用的支持 GDS 的 Lustre 并行分布式文件系統代碼的升級。
- NetApp 目前正在致力于啟用服務器端 NFSoRDMA ,因此他們可以利用其他人在客戶端啟用 NFS 的 GDS 。
具有 GDS 的供應商證明點
自 NVIDIA 發布last GDS post以來,已有幾項新數據的開發。我們在這篇文章中分享了其中的一個示例,作為證明 GPU 直接存儲的好處和通用性的證據。
配置
GDS 可以通過跳過各種平臺上的 CPU 跳出緩沖區來增加價值,無論是 NVIDIA 的 DGX 系統還是第三方 OEM 平臺。如前一篇文章Accelerating IO in the Modern Data Center: Magnum IO Storage所述,當 NIC PCIe 交換機 – GPU 數據路徑不經過 CPU 就可用時, GDS 可用的理論峰值帶寬有 2 倍的差異,盡管實際增益可能要大得多。
在 DGX 中,某些 NIC 插槽的數據路徑必須經過 CPU ,而對于其他插槽,直接 NIC PCIe 交換機 GPU 路徑可繞過 CPU 。圖 2 顯示了 DGX A100 背面的標記圖片。
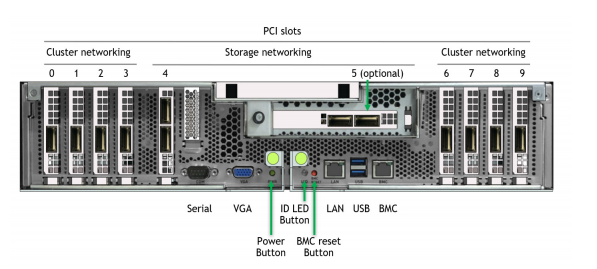
有兩種配置可以在 DGX A100 上評估存儲性能。經批準的標準配置在插槽 4 和 5 中專用于連接到用戶管理平面和外部存儲平面的兩個“南北”(朝向數據中心邊緣) NIC ,以及在插槽 0-3 和 6-9 中專用于連接到節點間計算平面的八個“東西”(集群內) NIC 。
我們正朝著使用八個東西方 NIC 訪問高帶寬存儲的方向發展,從而在完成 QoS 評估之前創建一個聚合計算存儲平面。現在,我們稱之為實驗的配置
以前提供的合作伙伴數據
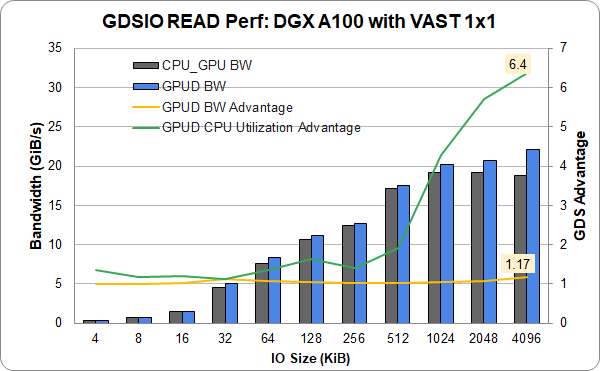
自從第一次發布 GDS 后, NVIDIA 已經公開了其他供應商的數據。其中包括來自 DDN EXAScaler 、 Pavilion NFSoRDMA 、 VAST NFSoRDMA 和 Weka FS 的數字。使用 DGX A100 上的實驗性 8-NIC 配置,我們已經看到供應商提供的帶寬范圍為 152 到 178 GiB ( 186 GB / s )的 GDS 。如果沒有 GDS ,他們報告的帶寬范圍為 40-103 GiB / s 。
今后, NVIDIA 要求任何合作伙伴的 DGX 系統性能報告(包括 8-NIC 數據)也應包括兩個南北 NIC 的特性描述。這些數據還沒有全部出來,所以這里沒有介紹。我們的政策是不在供應商合作伙伴之間進行直接性能比較。
以太網上的海量數據
以前在 InfiniBand 上報告了海量數據通用存儲。他們提供了一個單一(插槽 4 ) NIC 和 DGX A100 中的 1 GPU 的新結果,該 DGX A100 具有龐大的入門級 1 × 1 配置,使用以太網而不是 InfiniBand 。以太網顯示了完整的功能和相當的性能。從單個鏈路實現超過 22 GiB / s 的速度接近最高性能。這表明,除了 InfiniBand 之外, GDS 同樣適用于以太網。
IBM 頻譜規模
IBM Spectrum Scale (前身為 GPFS )的 GA 產品最近有了一個條目。在他們的配置中,一個運行 IBM Spectrum Scale 5 . 1 . 1 的 ESS 3200 存儲文件服務器提供了 71 GiB / s ( 77 GB / s )。它通過 4 個 HDR NIC 的 NIC 插槽 4 和 5 連接到兩個采用傳統存儲網絡配置的 DGX A100 。 IO 大小為 1MB 。通常情況下,絕對性能隨著使用的線程數的增加而提高(圖 4 )。與沒有 GDS 的情況相比, GDS 的相對改進在線程數量方面仍然相當穩定,但在線程數量較少的情況下顯然是最好的。
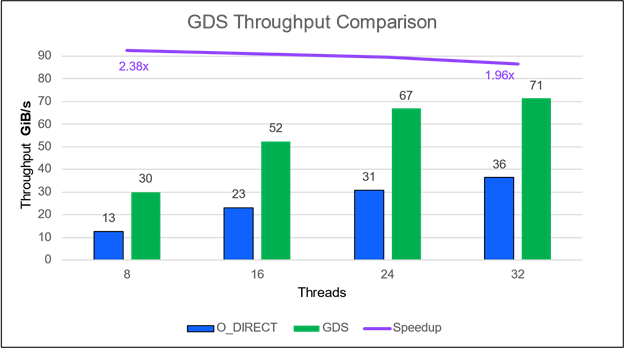
展館數據結果
Pavilion 為分布式并行文件系統、塊和對象接口提供存儲解決方案。它使用 NFSoRDMA 啟用 GDS 。 Pavilion Data 提供占用四個機架單元( RU )的存儲節點,提供足夠的帶寬,其中兩個節點可以使四個 DGX A100 上的兩個 NIC 或單個 DGX A100 上的八個 NIC 達到飽和。圖 5 中的結果僅來自實驗配置, Pavilion 軟件版本 2 執行文件訪問。
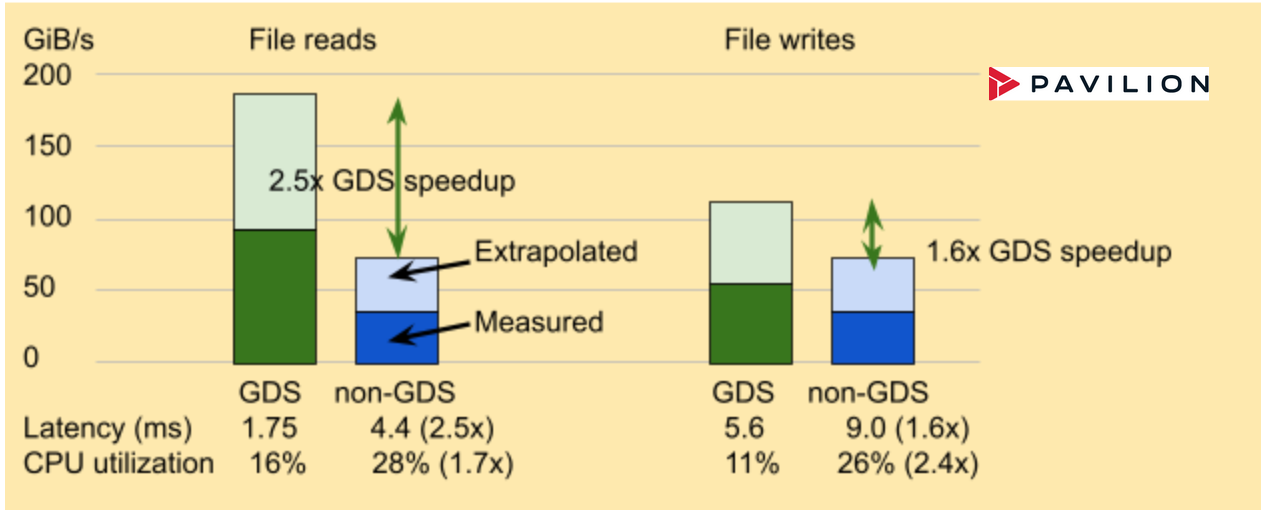
Liqid 結果
最近在 Liqid 系統上測量的性能表明,基于 PCIe 的 P2P 路徑比基于以太網/ InfiniBand 的 NVMe 更快。 GPU 和與 GDS 集成的 SSD 之間的 P2P 通信達到 2900K IOPS ,吞吐量提高了 16 倍。與非 GDS 路徑相比,延遲從 712 us 提高了 1 . 86 倍至 112 us (圖 6 )。
GPU 到 SSD 且禁用 P2P
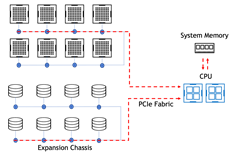
IOPS 潛伏期: 712 us
GPU 到 SSD ,帶啟用 GDS 的 P2P
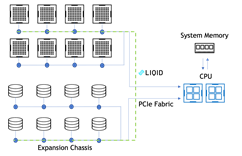
IOPS 潛伏期: 112 us
收集了三種不同配置的數據:
- 配置 1 : GPU – 到 NVMe 。使用 Liqid 結構連接同一 PCIe 結構上的所有設備。
- 配置# 2 : GPU – 到 – CPU – 到 NVMe 。將 GPU 和 NVMe 驅動器直接連接到 CPU 主板。
- 配置# 3 : GPU – 到的 NIC NVMe 。使用 GPU 到( CX-5 )的 NVMe 通過網絡訪問遠程 NVMe 。
以下是配置的詳細信息:
- 主板: AsROCK 機架 ROME8D-2T ,配備 AMD Epyc 7702p 、 512GB DDR4 2933
- 系統軟件: Ubuntu 服務器 20 . 04 . 2 , NVIDIA 驅動程序版本 470 . 63 . 01 , CUDA 11 . 4
- Liqid QD4500 配備 Phison E16 800GB 、 Gen4 PCIe 、運行 Liqid v3 . 0 的 24 端口 Gen4 數據交換機( Astek )的 24 端口管理交換機( TOR )
- NVIDIA A100 40GB , PCIe Gen4 與 LQS4500 位于同一 PCIe 交換機上
- BIOS 設置 ACS = Off ,在 Liqid 中啟用 P2P 。
圖 6 。 GPU 和 SSD (或 NVMe 驅動器)之間的點對點( P2P )通信通過 GPU 直接存儲實現了幾個數量級的 IOPS 改進.GPU Liqid Matrix 擴展機箱中的直接存儲支持 GPU 和 SSD 之間的直接 P2P 通信,實現了高達 1620% 的 IOPS 加速和 86% 的延遲改善.
InfiniBand 和以太網
雖然 Infiniband 在傳統 HPC 系統中很受歡迎,但以太網在企業數據中心中有著廣泛的應用。 GDS 在以太網和 IB 上無處不在。關鍵要求是底層系統和遠程文件管理器支持 RDMA 。這在 RoCE 中是可能的。
那么,兩者之間的比較如何呢?以下是初步調查的一些結果。對通過擴展網絡訪問存儲的全面分析不在本文討論范圍之內,但對于那些希望就其網絡設計做出數據驅動決策的人來說,這是值得鼓勵的。
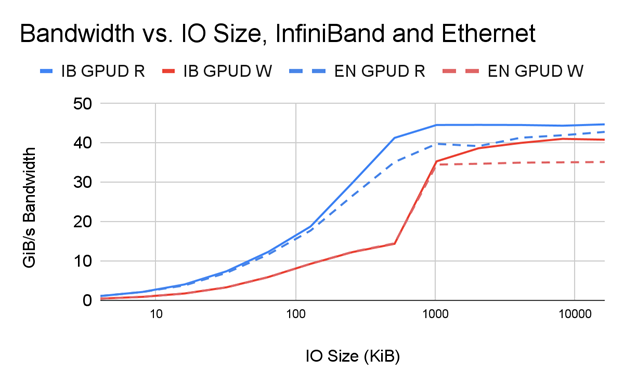
圖 7 顯示了在以下條件下帶寬隨 IO 大小變化的并排比較:
- 單個 PCIe 樹中的兩個 NIC 使用 InfiniBand 連接到一個 DDN AI400x 文件服務器
- 單個 PCIe 樹中的兩個 NIC 使用以太網連接到同一 DDN AI400x 文件服務器
如您所見, IB 和帶有 GDS 的以太網的性能相當, GDS 顯然是建立在 GPU 直接 RDMA 之上的。 IB 比以太網具有高達 1 . 17 倍的性能優勢,尤其是在性能最高且網絡速度差異最大的更大 IO 尺寸下。
社區光澤
不同的供應商為 Lustre 的社區版本增加了自己的價值。但我們的一些客戶僅限于使用 OSS 社區 Lustre 。他們還能在非專有解決方案中享受 GDS 的好處嗎?答案是肯定的!
與不使用 GDS 相比, GDS 的帶寬、延遲和 CPU 利用率增益都與其他啟用 GDS 的實現類似。可下載版本 2 . 15 的每個發行版本。今天就試試吧!
混搭
我們在 NVIDIA 有一個實驗集群,我們稱之為 ForMIO (用于 Magnum IO ),因為它用于評估和審查與 Magnum IO ( MIO )相關的各種技術。 DDN 和 Pavilion 慷慨地讓我們使用他們的設備進行文件管理。媒體供應商 Kioxia 、 Micron 和 Samsung 慷慨捐贈了驅動器來填充其中一些文件服務器。我們很興奮,因為這加快了對 DL 框架和使用 GDS 的客戶應用程序的評估。
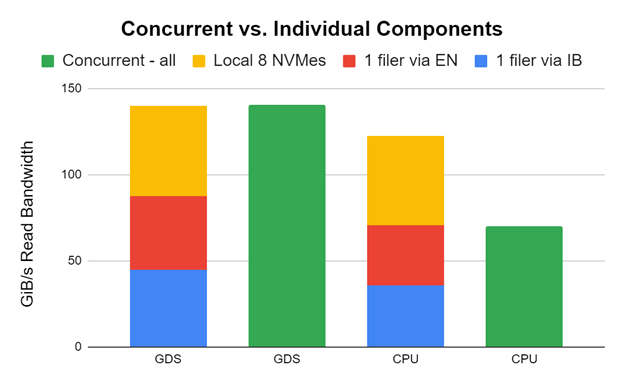
我們做了一些瘋狂的嘗試,結果成功了!我們使用兩個 HDR 200 NIC 將一個 DDN AI400x 與 InfiniBand 連接起來,一個 DDN AI400s 與兩個 HDR 200 NIC 的以太網連接起來,八個本地 NVME 與一個 DGX A100 連接起來。我們使用 GDSIO 性能評估工具對所有客戶進行了測試。
圖 8 中的早期和未調整的結果顯示,存儲帶寬可以跨這些應用程序組合,以向應用程序提供帶寬。雖然我們在實踐中不一定推薦這一點,但知道這是可能的還是很酷的。感謝 DDN 支持實現這一點。
在單個 DGX A100 上分別(紅色、藍色、黃色)和同時(綠色)測量帶有 InfiniBand 的一個 DDN AI400x (使用兩個 HDR 200 NIC )、帶有以太網的一個 DDN AI400s (使用兩個 HDR 200 NIC )和八個本地 NVME 的性能。單個組件堆疊在每對的左側。當它們都同時運行時,綠色條顯示性能。
在 GDS 的情況下,性能完全匹配,因為 GPU 目標被仔細選擇為無干擾。在 CPU 中使用跳出緩沖區的非 GDS 情況下,進出 CPU 的擁塞會抑制并發性能。這是一個巨大的不同。
摘要
我們鼓勵您基于目前通用的產品部署生產解決方案,并考慮將新出現的解決方案納入下一代系統。 GPU Direct Storage 現已在 v1 . 0 版中全面提供,更多的供應商合作伙伴正在將支持 GDS 的產品轉移到 GA 狀態。還有一系列案例研究,涵蓋存儲框架、深度學習、地震、數據分析和數據庫。
在 GDS 上合作
NVIDIA 鼓勵與供應商合作伙伴和客戶接觸,并提供清晰的使用案例。如果您感興趣,reach out to our team。我們希望更多地了解您即將推出的支持 GDS 的端到端擴展存儲解決方案。我們向準備使用 GDS 啟用存儲驅動程序的供應商合作伙伴推薦以下資源:
- 有關最終客戶和 OEM ,請參閱NVIDIA GPUDirect Storage Design Guide。
- 有關最終客戶、 OEM 和合作伙伴,請參閱NVIDIA GPUDirect Storage Overview Guide。
- 有關使用 GDS 編程的更多信息,請參閱cuFile API Reference Guide。
- 有關在存儲系統中啟用 GDS 或通過供應商合作伙伴支持工作的更多信息,請參閱NVIDIA GPUDirect Storage O_DIRECT Requirements Guide。
- 有關一般信息,請參閱NVIDIA GPUDirect Storage文檔。
- 有關視頻說明,請參閱Accelerating Storage with Magnum IO and GPUDirect Storage GTC 2020 課程。
我們希望您能加入即將到來的 SC21 鳥類功能會話Accelerating Storage IO to GPUs。
為 GDS 做出貢獻
這里描述的 GDS 內核驅動程序nvidia-fs.ko是開源的。在MagnumIO/tree/main/gds GitHub repo 中,有一些代碼簽入主線或作為社區已開始貢獻的請求提供,以加速開發并提高社區范圍內的性能。來加入社區,關注新的開發空間吧!
致謝
感謝以下授予或出借設備進行評估的供應商,或向 NVIDIA 提供其 OEM 平臺或其組件上的性能表征數據的供應商: DELL Technologies 、 DDN 、 Excelero 、 IBM 、 Kioxia 、 Micron 、 Pavilion 、三星、 ScaleFlux 、 VAST 和 Weka 。
?