壓縮可以在各種用例中提高性能,例如 DL 工作負載、數據庫和通用 HPC 。在 GPU 上,壓縮可以加速協作工作流的 GPU 間通信。它可以通過在數據存儲到全局內存之前壓縮數據來增加單個 GPU 可以處理的數據集的大小。它還可以加速 CPU 和 GPU 之間的數據鏈路。
為了讓這些工作流中的任何一個都變得有用,壓縮和解壓縮必須快速,并且在給定數據集上以足夠高的壓縮比運行,才能發揮作用。然而,不同算法的壓縮比和吞吐量因數據集而異。如果沒有大量關于算法和數據統計的專業知識,可能很難選擇最佳算法。
NVIDIA NVCOMP 庫使您可以在應用程序中結合高性能 GPU 壓縮和解壓縮。該庫提供了一組統一的 API ,允許您快速交換壓縮格式,以在數據集上實現最佳性能,而對代碼的更改最少。
使用 nvCOMP ,您可以快速、輕松地使用不同的算法進行實驗,以找到最適合您的用例的算法。在最近的版本中,我們更新了 nvCOMP 以進一步改進和統一接口。在新發布的 2.2 版本中,我們提供了一個易于使用的、高級的 C ++ API 和一個通用的低級別批量 C API 。在本文中,我們將詳細介紹這兩個接口。你還可以學習如何有效地使用它們,以及何時應該選擇其中一個。
高級 API
高級 API 更易于使用,并抽象了向 GPU 公開并行性的工作。當您必須將連續緩沖區壓縮為連續的壓縮緩沖區時,它最有用。例如,在通過網絡發送緩沖區或將其保存到磁盤之前壓縮緩沖區時,這種方法效果很好。
以下示例使用高通量GDeflate壓縮格式。GDeflate類似于 deflate ,可以有效地映射到數據并行架構,如 GPU 。如果您對使用的壓縮格式沒有限制,那么這是一個很好的起點。
高級接口是基于nvcompManagerBase類層次結構的C++ API。每個派生的Manager類都在nvcomp/include中與其關聯的頭中聲明。例如,本文中使用的GDeflateManager在nvcomp/include/gdeflate.hpp中聲明。
首先,構建所需的Manager類。每個Manager構造函數都有一組唯一的參數;然而,有一些觀點通常是一致的。所有子類都允許使用指定的流 ID 構造用于所有內核和內存傳輸。您還可以指定要使用的設備 ID 。如果不為這兩個參數指定值,則使用默認的流和設備。
另一個常見的輸入是未壓縮的塊大小。這在壓縮過程中用于將緩沖區拆分為獨立的塊進行處理。較大的塊大小通常會導致更高的壓縮比,但代價是暴露在 GPU 中的并行性會降低。一個好的起始數據塊大小是 64KB ,但是可以自由地使用這些值來探索數據集的相關權衡。
Manager類也使用特定于格式的參數構造。您可以查看nvcomp/include中的相關標題,了解Manager類構造函數參數的描述,并了解如何為所選格式構造Manager對象。
const size_t uncomp_chunk_size = 64 * 1024; cudaStream_t stream;
cudaStreamCreate(&stream));
const int gdeflate_algorithm = 0; // Use standard GDeflate
const int device_id = 0; // Use the default device GdeflateManager gdeflate_manager{chunk_size, gdeflate_algorithm, stream, device_id};
nvcompManager需要一個臨時的 scratch 工作區來進行壓縮和解壓縮。根據特定的壓縮格式參數以及壓縮和解壓縮內核的最大占用率,所需的暫存空間大小是固定的。如果對您的用例有意義,您可以在構造后使用set_scratch_buffer為nvcompManager對象提供一個臨時緩沖區。
size_t scratch_buffer_size = gdeflate_manager.get_required_scratch_buffer_size(); uint8_t* scratch_buffer; cudaMalloc(&scratch_buffer, scratch_buffer_size); gdeflate_manager.set_scratch_buffer(scratch_buffer);
手動設置暫存緩沖區可能有助于控制用于此分配的內存分配方案。如果您同意默認設置,我們建議跳過此步驟并啟用nvcompManager對象來處理分配。
此緩沖區可用于nvcompManager執行的所有壓縮和解壓縮操作。如果nvcompManager對象分配了暫存緩沖區,則在銷毀該對象時會釋放該緩沖區。
壓縮
現在可以壓縮緩沖區了。首先,使用configure_compression API 配置壓縮。此異步操作返回CompressionConfig對象。
配置步驟只需要input-uncompressed緩沖區的大小。您必須分配一個 GPU 可訪問的內存緩沖區,其大小至少為該大小,以用作壓縮例程的結果緩沖區。有了這些信息,可以執行壓縮,如下面的代碼示例所示:
CompressionConfig comp_config = gdeflate_manager.configure_compression(input_buffer_len); uint8_t* comp_buffer; cudaMallocAsync(&comp_buffer, comp_config.max_compressed_buffer_size, stream); gdeflate_manager.compress(uncomp_buffer, comp_buffer, comp_config);
您還可以在 GPU 上排隊進行其他壓縮。
uint8_t* comp_buffer1, comp_buffer2; CompressionConfig comp_config1 = gdeflate_manager.configure_compression(input_buffer_len1); cudaMallocAsync(&comp_buffer1, comp_config1.max_compressed_buffer_size, stream); gdeflate_manager.compress(uncomp_buffer1, comp_buffer1, comp_config1); CompressionConfig comp_config2 = gdeflate_manager.configure_compression(input_buffer_len2); cudaMallocAsync(&comp_buffer2, comp_config2.max_compressed_buffer_size, stream); gdeflate_manager.compress(uncomp_buffer2, comp_buffer2, comp_config2); cudaStreamSynchronize(stream);
減壓
高級接口壓縮產生的緩沖區在壓縮數據之前包含一個頭(圖 1 )。此標題包含有關緩沖區如何壓縮的信息,因此您可以從壓縮的緩沖區構造nvcompManager對象,而不知道它是如何壓縮的。這使您可以在不知道緩沖區是如何壓縮的情況下對其進行解壓縮。

為此,請使用nvcompManagerFactory.hpp中聲明的create_manager API 。這個同步 API 將壓縮的緩沖區以及可選的流和設備 ID 作為輸入。
auto decomp_nvcomp_manager = create_manager(comp_buffer, stream);
如果您已經掌握了有關緩沖區壓縮方式的信息,那么可以使用前面描述的配置構造一個新的管理器。您還可以重用用于壓縮的同一nvcompManager對象來執行解壓縮。這些方法的優點是不需要同步流。
給定一個nvcompManager對象和一個壓縮的緩沖區,解壓的執行與壓縮類似,但有幾個細微的區別。首先,有兩種可能的方式來進行解壓縮配置。如果壓縮使用CompressionConfig對象,則可以完全異步配置解壓縮。
DecompressionConfig decomp_config = gdeflate_manager->configure_decompression(comp_config);
該 API 的一個示例用例是大型神經網絡的訓練。可以使用的神經網絡或訓練集的大小取決于 GPU 的內存容量。使用壓縮,您可以有效地增加此容量,而無需將數據卸載到 CPU 或使用多個 GPU 。
具體來說,基于反向傳播的訓練包括在向前傳球時計算激活圖,然后在向后傳球的計算中重用它們。這些激活映射比較大且相對稀疏,因此非常適合壓縮。使用gdeflate_manager壓縮地圖,并在內存中保存網絡各層的壓縮緩沖區和CompressionConfig對象。這可以實現完全異步的反向傳播,包括解壓縮。
如果沒有使用的CompressionConfig對象,也可以使用壓縮緩沖區配置解壓縮。這是一個同步操作,必須從設備執行cudaMemcpyAsync操作。所有同步都在nvcompManager構造函數中指定的流上,并且不是設備范圍的。
DecompressionConfig decomp_config = gdeflate_manager->configure_decompression(comp_buffer);
與壓縮一樣,在同步流之前,您可以一次將多個解壓縮項目排隊。
uint8_t* res_decomp_buffer1, res_decomp_buffer2; DecompressionConfig decomp_config1 = gdeflate_manager->configure_decompression(comp_config1); DecompressionConfig decomp_config2 = gdeflate_manager->configure_decompression(comp_config2); cudaMallocAsync(&res_decomp_buffer1, decomp_config1.decomp_data_size, stream); cudaMallocAsync(&res_decomp_buffer2, decomp_config2.decomp_data_size, stream); gdeflate_manager->decompress(res_decomp_buffer1, comp_buffer1, decomp_config1); gdeflate_manager->decompress(res_decomp_buffer2, comp_buffer2, decomp_config2); cudaStreamSynchronize(stream));
最后,在高級 API 中有兩種類型的錯誤檢查:std::runtime_error異常和檢查nvcompStatus_t值。
如果任何 CUDA API 失敗,就會引發std::runtime_error異常。您可以在應用程序中捕獲這些錯誤,也可以不處理它們,在這種情況下,您的應用程序會失敗,并顯示一條描述錯誤的消息。例如,如果您提供的輸出緩沖區大小不足或無法在 GPU 上訪問,就會發生這種情況。
錯誤檢查的第二種形式是檢查CompressionConfig或DecompressionConfig對象中的nvcompStatus_t值。此狀態在相關的內核調用期間設置。損壞的輸入緩沖區和其他錯誤會觸發它。
低級 API
低級 API 為更高級的工作流提供了 C API 。低級 API 同時壓縮和解壓縮您提供的一批獨立塊。這取決于您對數據進行分塊,并提供足夠數量的分塊來利用 GPU 的并行處理能力。
如果有許多獨立的、不連續的緩沖區,這是處理數據最有效的方法。低級 API 避免了將生成的壓縮塊打包到單個連續的壓縮緩沖區的工作量。它還避免了與在高級 API 中保存有關緩沖區如何壓縮的信息相關的壓縮比開銷。
該工作流非常適合數據庫應用程序,例如,在這些應用程序中,往往需要壓縮或解壓縮許多獨立的列。這個 API 用于 RAPIDS 和 NVIDIA Spark 實現。
壓縮
對于低級 API 中的壓縮,必須分配一個臨時暫存緩沖區。臨時緩沖區與高級 API 中描述的類似。然而,緩沖區大小取決于輸入緩沖區的大小,因此必須重新定義它,并可能與每一組新的用戶輸入一起重新分配。
size_t temp_bytes; nvcompBatchedGdeflateCompressGetTempSize(batch_size, chunk_size, nvcompBatchedGdeflateDefaultOpts, &temp_bytes); void* device_temp_ptr; cudaMalloc(&device_temp_ptr, temp_bytes);
接下來,應該計算批處理中壓縮塊的最大大小。這允許您分配一組結果緩沖區。在下面的示例中,batch_size是要處理的塊數。結果指針的設備數組在復制到設備之前在固定的主機內存中構造。
size_t max_out_bytes;
nvcompBatchedGdeflateCompressGetMaxOutputChunkSize(chunk_size, nvcompBatchedGdeflateDefaultOpts, &max_out_bytes); // Allocate output space on the device
void ** host_compressed_ptrs;
cudaMallocHost((void**)&host_compressed_ptrs, sizeof(size_t) * batch_size);
for(size_t ix_chunk = 0; ix_chunk < batch_size; ++ix_chunk) { cudaMalloc(&host_compressed_ptrs[ix_chunk], max_out_bytes);
} void** device_compressed_ptrs;
cudaMalloc(&device_compressed_ptrs, sizeof(size_t) * batch_size);
cudaMemcpy( device_compressed_ptrs, host_compressed_ptrs, sizeof(size_t) * batch_size,cudaMemcpyHostToDevice);
通過計算所有這些輸入,您現在可以異步進行壓縮,如圖所示。
nvcompStatus_t comp_res = nvcompBatchedGdeflateCompressAsync( device_uncompressed_ptrs, device_uncompressed_bytes, chunk_size, batch_size, device_temp_ptr, temp_bytes, device_compressed_ptrs, device_compressed_bytes, nvcompBatchedGdeflateDefaultOpts,
減壓
要開始解壓,請根據壓縮的緩沖區預計算解壓的大小。如果您已經有此信息,請跳過此步驟。
nvcompBatchedGdeflateGetDecompressSizeAsync( device_compressed_ptrs, device_compressed_bytes, device_uncompressed_bytes, batch_size, stream);
與壓縮類似,您還必須計算所需的臨時大小,并分配臨時暫存緩沖區。
size_t decomp_temp_bytes; nvcompBatchedGdeflateDecompressGetTempSize(batch_size, chunk_size, &decomp_temp_bytes); void * device_decomp_temp; cudaMalloc(&device_decomp_temp, decomp_temp_bytes);
最后,可以進行異步解壓縮。
nvcompStatus_t decomp_res = nvcompBatchedGdeflateDecompressAsync( device_compressed_ptrs, device_compressed_bytes, device_uncompressed_bytes, device_actual_uncompressed_bytes, batch_size, device_decomp_temp, decomp_temp_bytes, device_uncompressed_ptrs, device_statuses, stream);
標桿管理
nvCOMP 為低級和高級格式的每種格式提供了一組基準。圖 2 比較了在幾個不同的數據集上使用大型連續緩沖區時高級和低級的性能。使用 A100 GPU 收集結果。
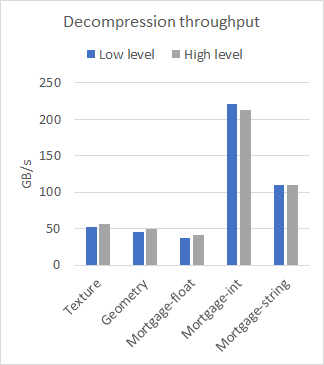
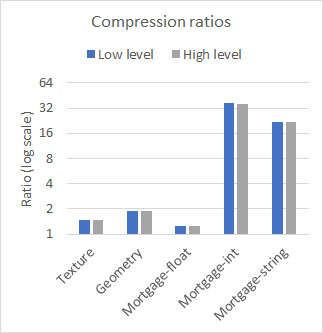
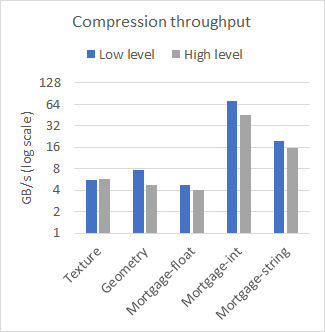
從結果中可以看出,在使用大型連續緩沖區時,低級和高級 API 之間的性能差異可以忽略不計。使用哪一個取決于您的用例。如果有許多小緩沖區,請使用低級 API ,或者避免與高級 API 相關的內存占用。
圖 3 顯示了日志規模下不同緩沖區大小的性能。為了產生這些結果,圖 2 中顯示的 mortgage int 數據集被分成許多批batchSize,如圖所示。該文件超過 314 MB 。對于 1 MB 的批量大小,執行 315 次壓縮和解壓縮操作。批量大小為 400 MB 時,執行單個壓縮和解壓縮操作。
以這種方式批處理數據不會影響低級批處理 API 。
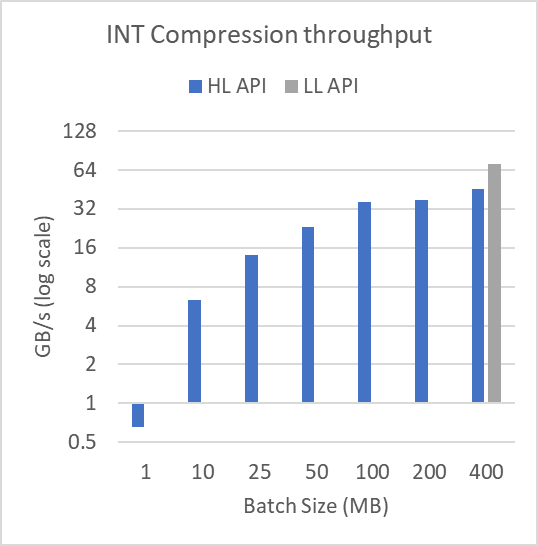
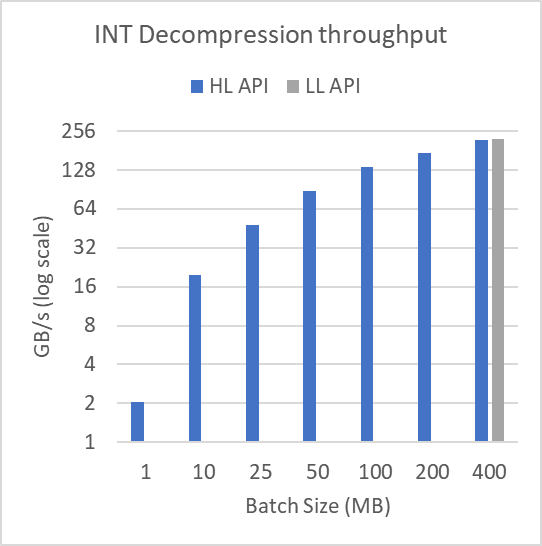
正如所證明的,對于小批量,高級接口的性能會嚴重下降。這顯示了在壓縮或解壓縮許多較小的緩沖區時使用低級批處理 API 的實用性。低級批處理 API 可以使用更少、占用率更高的內核來完成操作,而高級 API 需要許多具有相關尾部效應和占用率問題的小型內核啟動。
我們在庫中加入了基準測試應用程序,以便您可以嘗試不同的壓縮格式,并查看哪種格式對您的數據最有效。提供的基準是benchmark_hlif和benchmark_<format>_chunked。有關更多信息,請參閱 nvCOMP README 。
總結
現在,您已經了解了如何使用高級 nvCOMP API 來輕松壓縮和解壓縮。您已經了解了何時使用低級 API 更好,以及如何使用它。
有關更多信息,請參閱 NVIDIA/nvcomp GitHub 回購協議的最新版本。有關可以適應您的用例的完整工作、可編譯的示例,請參閱 lowlevel_c_quickstart.md 和 highlevel_cpp_quickstart.md 演練以及相關的示例文件。
如果您有任何問題,請在下面評論。你也可以在 聯系專家: nvCOMP:GPU 壓縮/解壓縮 GTC 會議將于 3 月 21 日星期一上午 10 點舉行。
?









