

開放式 VDB 是奧斯卡獎獲獎的稀疏動態卷的行業標準庫。在整個視覺效果行業中,它被用于模擬和渲染水、火、煙、云和大量其他依賴于稀疏體積數據的效果。該庫包括一個分層的、動態的數據結構和一套工具,用于高效地存儲和操作三維網格上離散的稀疏體數據。庫由 學院軟件基金會( ASWF ) 維護。有關詳細信息,請參見 VDB :具有動態拓撲的高分辨率稀疏卷 。
盡管 OpenVDB 提供了性能優勢,但它的設計并沒有考慮到 GPUs 。它對幾個外部庫的依賴使得利用 GPUs 上的 VDB 數據變得很麻煩,這正是本文主題的動機。我們將向您介紹 NanoVDB 庫,并提供一些如何在光線跟蹤和碰撞檢測上下文中使用它的示例。
NanoVDB 簡介
最初在 NVIDIA 開發的 NanoVDB 庫是一個 ASWF OpenVDB 項目的新增功能 。它提供了一個與 OpenVDB 的核心數據結構完全兼容的簡化表示,具有在 NanoVDB 和 OpenVDB 數據結構之間來回轉換、創建和可視化數據的功能。
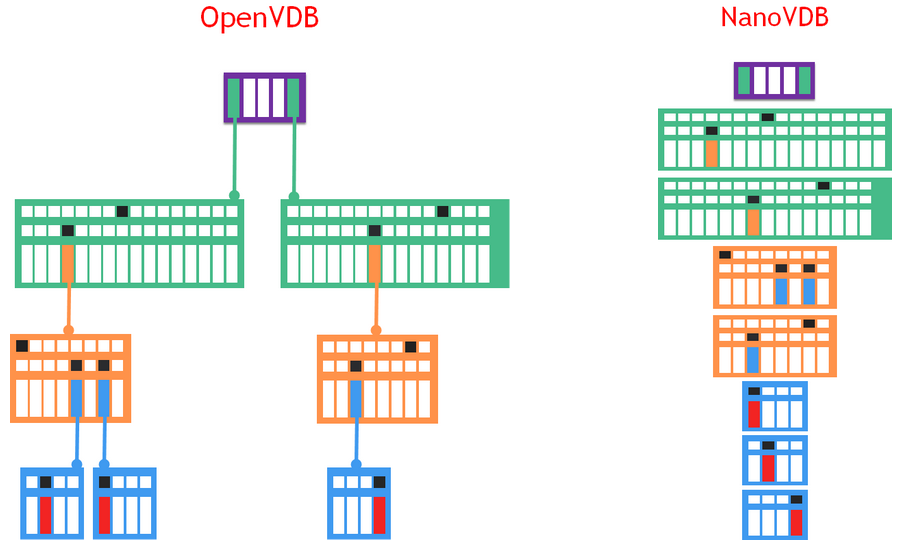
NanoVDB 采用了 VDB 樹結構的壓縮、線性化、只讀表示(圖 1 ),這使得它適合于樹層次結構的快速傳輸和快速、無指針遍歷。為了提高效率,數據流經過調整,可以在 GPUs 和 CPU 上使用。
創建 NanoVDB 網格
盡管 NanoVDB 網格是一種只讀數據結構,但該庫包含生成或加載數據的功能。
所有的 OpenVDB 網格類 – LevelSets 、 FogVolumes 、 PointIndexGrids 和 PointDataGrids ——都支持 NanoVDB 表示,并且可以直接從 OpenVDB 文件(即 . vdb 系統 文件)加載。還可以將數據加載或保存到 NanoVDB 自己的文件格式中或從中保存,該格式本質上是其內存流的一個轉儲,其中包含用于高效檢查的附加元數據。
以下代碼示例從 OpenVDB 文件轉換:
openvdb::io::File file(fileName); auto vdbGrid = file.readGrid(gridName); auto handle = nanovdb::openToNanoVDB(vdbGrid);
雖然從現有的 OpenVDB 數據加載是典型的用例,但是附帶的 網格生成器 工具允許您直接在內存中構建 NanoVDB 網格。提供了一些簡單原語的函數來幫助您入門:
// generate a sparse narrow-band level set (i.e. truncated signed distance field) representation of a sphere. auto handle = nanovdb::createLevelSetSphere(50, nanovdb::Vec3f(0));
下面的示例顯示了如何使用 lambda 函數生成小而密集的體積(圖 2 ):
nanovdb::GridBuilder builder(0);
auto op = [](const nanovdb::Coord& ijk) -> float { return menger(nanovdb::Vec3f(ijk) * 0.01f);
};
builder(op, nanovdb::CoordBBox(nanovdb::Coord(-100), nanovdb::Coord(100)));
// create a FogVolume grid called "menger" with voxel-size 1
auto handle = builder.getHandle<>(1.0, nanovdb::Vec3d(0), "menger", nanovdb::GridClass::FogVolume);

網格控制柄
網格句柄 是一個簡單的類,它擁有它分配的緩沖區的所有權,允許網格的范圍劃分( RAII )。
它還用于封裝不透明的網格數據。盡管網格數據本身是以數據類型(如 浮動 為模板的),但句柄提供了一種方便的方法來訪問網格的元數據,而不必知道網格的數據類型 MIG 是什么。這很有用,因為您可以純粹從句柄確定 GridType 。
下面的代碼示例驗證是否有包含級別集函數的 32 位浮點網格:
const nanovdb::GridMetaData* metadata = handle.gridMetaData();
if (!metadata->isLevelSet() || !metadata->gridType() == GridType::Float) throw std::runtime_error("Not the right stuff!");
網格緩沖區
NanoVDB 被設計成支持許多不同的平臺, CPU , CUDA 甚至圖形 api 。為了實現這一點,數據結構被存儲在一個平坦的連續內存緩沖區中。
使這個緩沖區駐留在 CUDA 設備上很簡單。為了完全控制,您可以使用 CUDA api 分配設備內存,然后將句柄的數據上載到其中。
void* d_gridData; cudaMalloc(&d_gridData, handle.size()); cudaMemcpy(d_gridData, handle.data(), handle.size(), cudaMemcpyHostToDevice); const nanovdb::FloatGrid* d_grid = reinterpret_cast<const nanovdb::FloatGrid*>(d_gridData);
NanoVDB 的 GridHandle 模板化在緩沖區類型上,緩沖區類型是其內存分配的包裝器。它默認為使用主機系統內存的 主機緩沖區 ;然而, NanoVDB 還提供了 CUDA 緩沖器 ,以便輕松創建 CUDA 設備緩沖區。
auto handle = nanovdb::openToNanoVDB<nanovdb::CudaDeviceBuffer>(vdbGrid); handle->deviceUpload(); const nanovdb::FloatGrid* grid = handle->deviceGrid<float>();
將數據流解釋為納米網格類型后,可以使用這些方法訪問網格中的數據。有關更多詳細信息,請參閱相關 API 的文檔。本質上,它反映了 OpenVDB 中只讀方法的基本子集。
auto hostOrDeviceOp = [grid] __host__ __device__ (nanovdb::Coord ijk) -> float { ? ? // Note that ReadAccessor (see below) should be used for performance. ? ? return grid->tree().getValue(ijk); };
可以構造自定義緩沖區來處理不同的內存空間。有關創建可與圖形 API 交互操作的緩沖區的示例的更多信息,請參閱存儲庫中的示例。
致使

由于 NanoVDB 網格提供了一個緊湊的只讀 VDB 樹,因此它們很適合渲染任務。光線將 VDB 網格跟蹤到圖像中。使用每線程一條光線,并使用一個自定義的 雷吉諾 functor 生成光線,該函數接受像素偏移并創建世界空間光線。完整的代碼在存儲庫示例中可用。
考慮到沿射線采樣具有空間相干性這一事實,可以使用 讀寫器 來加速采樣。當光線向前移動時,這會緩存樹遍歷堆棧,從而允許自底向上的樹遍歷,這比傳統的自上而下遍歷要快得多,后者涉及相對較慢的無界根節點。
auto renderTransmittanceOp = [image, grid, w, h, rayGenOp, imageOp, dt] __host__ __device__ (int i) { nanovdb::Ray<float> wRay = rayGenOp(i, w, h); // transform the ray to the grid's index-space... nanovdb::Ray<float> iRay = wRay.worldToIndexF(*grid); // clip to bounds. if (iRay.clip(grid->tree().bbox()) == false) { imageOp(image, i, w, h, 1.0f); return; } // get an accessor. auto acc = grid->tree().getAccessor(); // integrate along ray interval... float transmittance = 1.0f; for (float t = iRay.t0(); t < iRay.t1(); t+=dt) { float sigma = acc.getValue(nanovdb::Coord::Floor(iRay(t))); transmittance *= 1.0f - sigma * dt; } imageOp(image, i, w, h, transmittance ); };

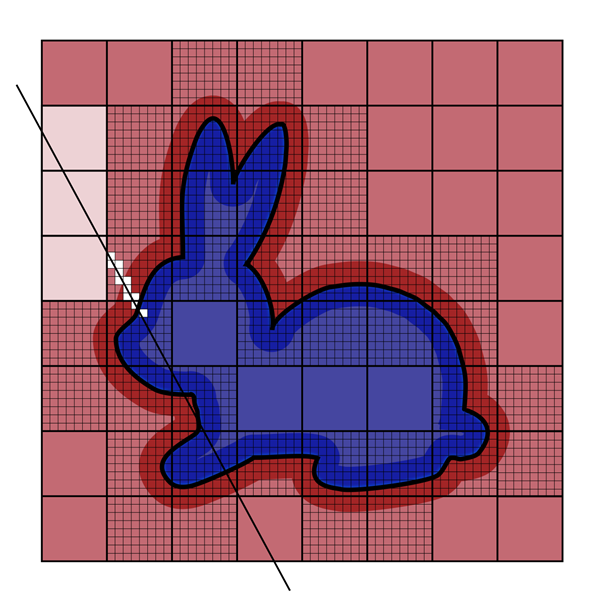
由于光線與水平集網格相交是一項常見任務, NanoVDB 實現了一個零交叉功能,并使用分層 DDA ( HDDA )作為沿光線的根搜索的一部分來清空空間跳躍(圖 5 )。有關 HDDA 的更多信息,請參閱 OpenVDB 中高效光線行進的分層數字微分分析儀 。下面是代碼示例:
... auto acc = grid->tree().getAccessor(); // intersect with zero level-set... float iT0; nanovdb::Coord ijk; float v; if (nanovdb::ZeroCrossing(iRay, acc, ijk, v, iT0)) { // convert intersection distance (iT0) to world-space float wT0 = iT0 * grid->voxelSize(); imageOp(image, i, w, h, wT0); } else { imageOp(image, i, w, h, 0.0f); } ...
碰撞檢測
碰撞檢測和解決是 NanoVDB 的另一項任務,因為它們通常需要有效地查找實體碰撞對象的有符號距離值。窄帶電平集表示非常理想,因為它們用符號對內部/外部拓撲信息(碰撞檢測所需)進行了緊湊編碼。此外,最近點變換(沖突解決所需的)很容易從水平集函數的梯度計算。
下面的代碼示例是一個用于處理沖突的函數。使用 讀寫器 是很有用的,因為用于沖突解決的梯度計算涉及到同一空間附近的多個提取。
auto collisionOp = [grid, positions, velocities, dt] __host__ __device__ (int i) { nanovdb::Vec3f wPos = positions[i]; nanovdb::Vec3f wVel = velocities[i]; nanovdb::Vec3f wNextPos = wPos + wVel * dt; // transform the position to a custom space... nanovdb::Vec3f iNextPos = grid.worldToIndexF(wNextPos); // the grid index coordinate. nanovdb::Coord ijk = nanovdb::Coord::Floor(iNextPos); // get an accessor. auto acc = grid->tree().getAccessor(); if (tree.isActive(ijk)) { // are you inside the narrow band? float wDistance = acc.getValue(ijk); if (wDistance <= 0) { // are you inside the levelset? // get the normal for collision resolution. nanovdb::Vec3f normal(wDistance); ijk[0] += 1; normal[0] += acc.getValue(ijk); ijk[0] -= 1; ijk[1] += 1; normal[1] += acc.getValue(ijk); ijk[1] -= 1; ijk[2] += 1; normal[2] += acc.getValue(ijk); normal.normalize(); // handle collision response with the surface. collisionResponse(wPos, wNextPos, normal, wDistance, wNextPos, wNextVel); } } positions[i] = wNextPos; velocities[i] = wNextVel; };
同樣,完整的代碼可以在存儲庫中找到。
基準
NanoVDB 被開發成在主機和設備上同樣運行良好。使用 modernCUDA 中的擴展 lambda 支持,您可以輕松地在兩個平臺上運行相同的代碼。
本節包括比較英特爾線程構建塊和 CPU CUDA 上光線跟蹤和碰撞檢測性能的基準測試。計時以毫秒為單位,與 NVIDIA NVIDIA 8000 相比,是在 Xeon E5-2696 v4 x2 –( 88 個 CPU 線程)上生成的。使用的 FogVolume 是兔子云, LevelSet 是 dragon 數據集。兩者都可以從 OpenVDB 網站下載。渲染的分辨率為 1024×1024 。這次碰撞試驗模擬了一億顆彈道粒子。
雖然基準測試(圖 6 和下表)顯示了 NanoVDB 高效表示加速 CPU 上 OpenVDB 的好處,但它真正突出了使用 GPU 對 VDB 數據進行只讀訪問以進行碰撞檢測和光線跟蹤的好處。
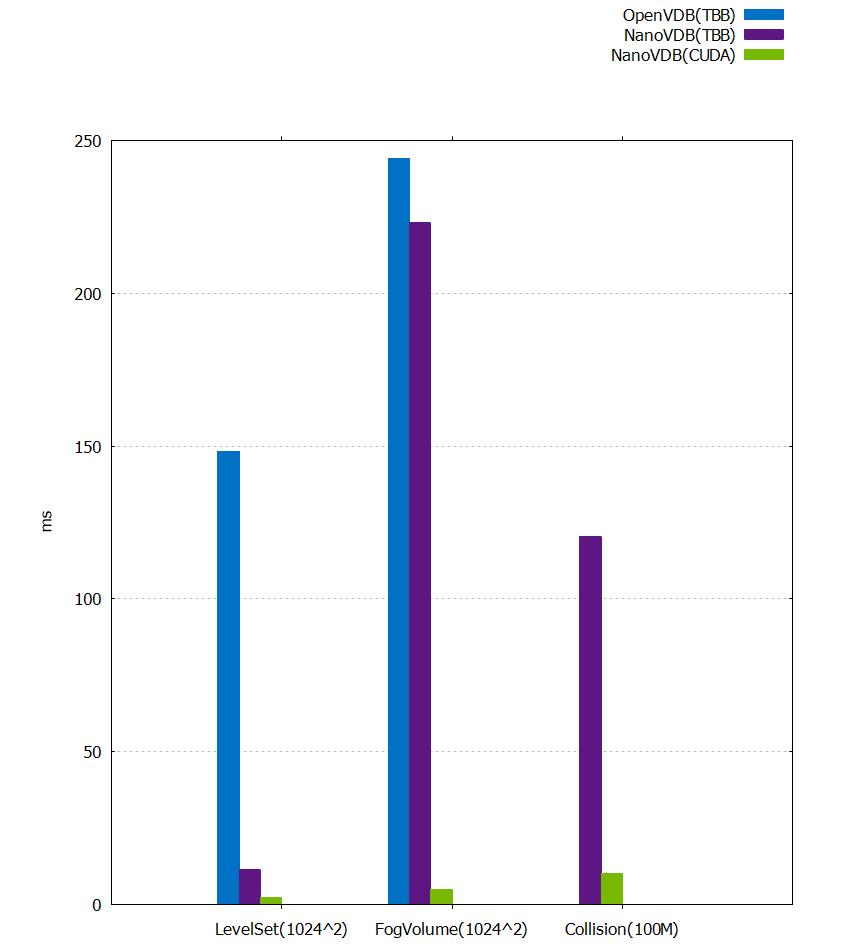
| ? | OpenVDB (TBB) | NanoVDB (TBB) | NanoVDB (CUDA) | CUDA Speed-up |
| LevelSet | 148.182 | ?11.554 | 2.427 | 5X |
| FogVolume | 243.985 | 223.195 | 4.971 | 44X |
| Collision | – | 120.324 | 10.131 | 12X |
結論
NanoVDB 是一個小而強大的庫,它通過使用 GPUs 來加速某些 OpenVDB 應用程序。開源存儲庫現在可用了!要下載源代碼、構建示例并體驗 GPU – 加速 NanoVDB 可以為稀疏卷工作流提供的強大功能,請參見 納米 VDB 。






