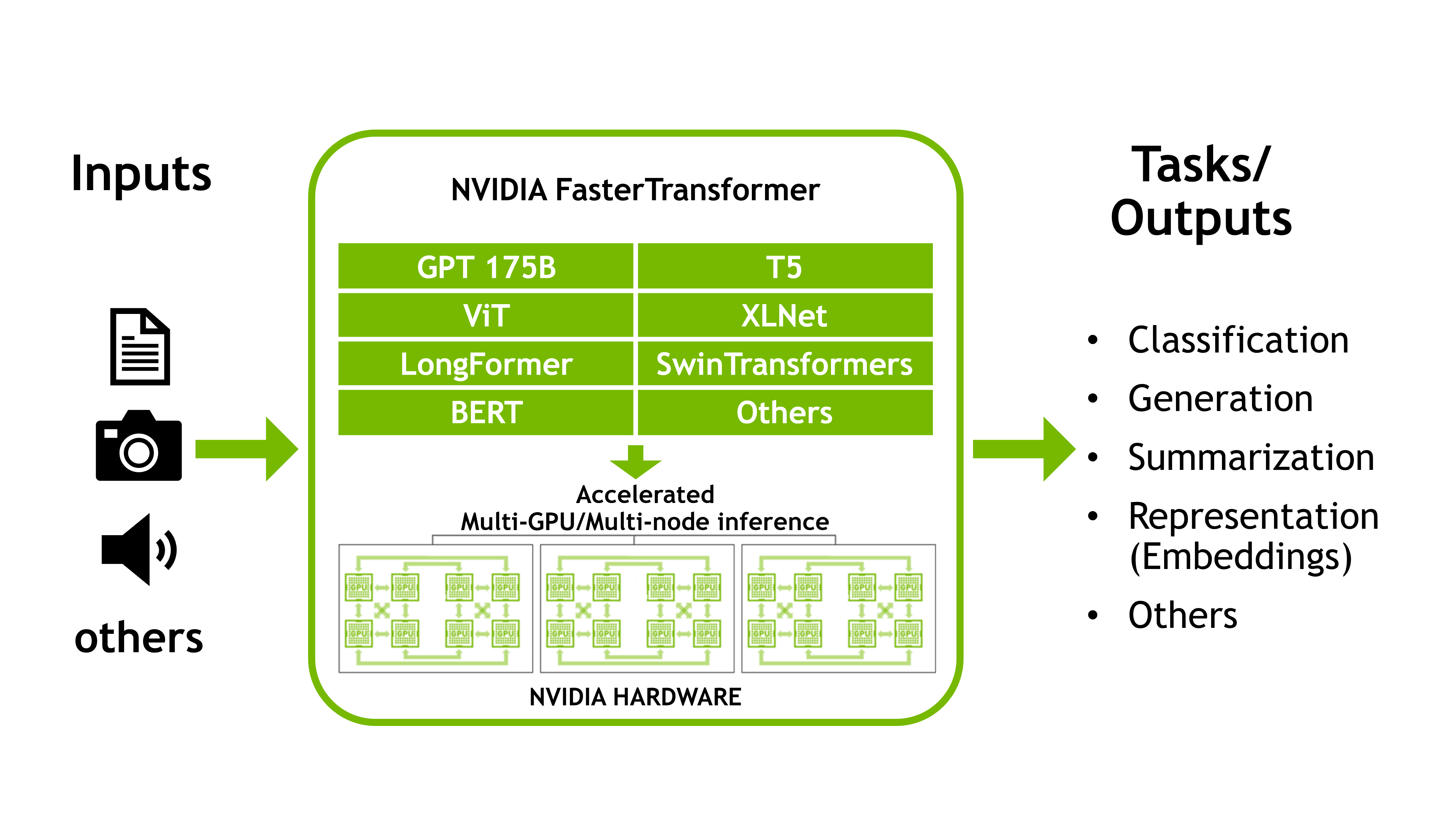
SE(3)-Transformers 是在NeurIPS 2020上推出的多功能圖形神經網絡。 NVIDIA 剛剛發布了一款開源優化實現,它使用的內存比基線正式實施少9倍,速度比基線正式實施快21倍。
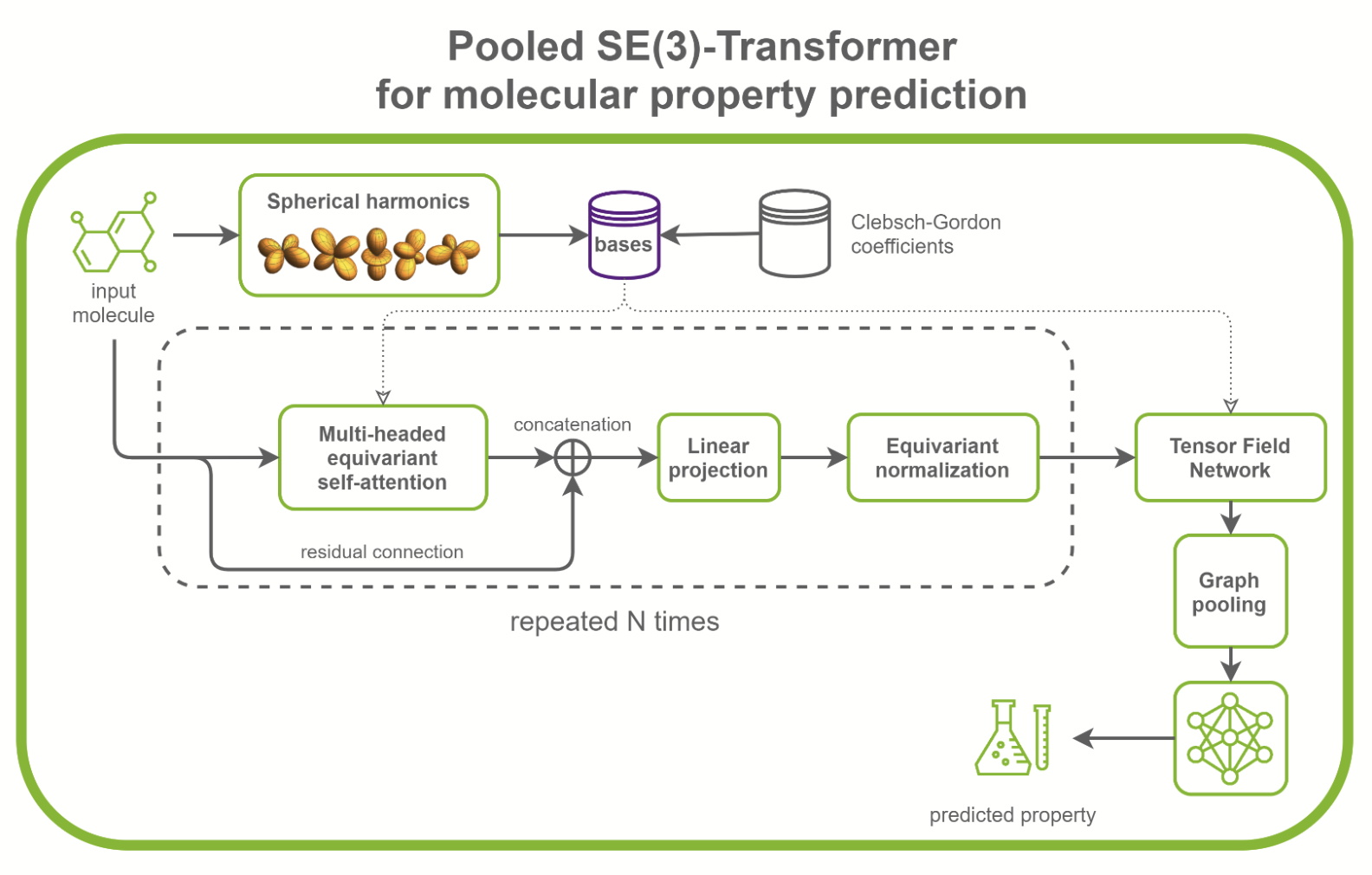
SE(3)-Transformer 在處理幾何對稱性問題時非常有用,如小分子處理、蛋白質精制或點云應用。它們可以是更大的藥物發現模型的一部分,如RoseTTAFold和此 AlphaFold2 的復制。它們也可以用作點云分類和分子性質預測的獨立網絡(圖 1 )。
在/PyTorch/DrugDiscovery/SE3Transformer存儲庫中, NVIDIA 提供了在QM9 數據集上為分子性質預測任務訓練優化模型的方法。 QM9 數據集包含超過 10 萬個有機小分子和相關的量子化學性質。
訓練吞吐量提高 21 倍
與基線實施相比, NVIDIA 實現提供了更快的訓練和推理。該實現對 SE(3)-Transformers 的核心組件,即張量場網絡( TFN )以及圖形中的自我注意機制進行了優化。
考慮到注意力層超參數的某些條件得到滿足,這些優化大多采取操作融合的形式。
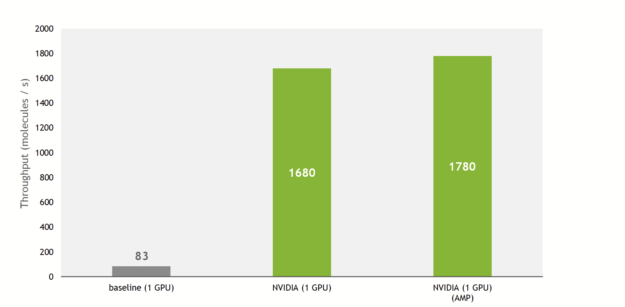
由于這些,與基線實施相比,訓練吞吐量增加了 21 倍,利用了最近 GPU NVIDIA 上的張量核。
此外, NVIDIA 實現允許使用多個 GPU 以數據并行方式訓練模型,充分利用 DGX A100 ( 8x A100 80GB )的計算能力。
把所有東西放在一起,在 NVIDIA DGX A100 上, SE(3)-Transformer現在可以在 QM9 數據集上在 27 分鐘內進行訓練。作為比較,原始論文的作者指出,培訓在硬件上花費了 2 . 5 天( NVIDIA GeForce GTX 1080 Ti )。
更快的培訓使您能夠在搜索最佳體系結構的過程中快速迭代。隨著內存使用率的降低,您現在可以訓練具有更多注意層或隱藏通道的更大模型,并向模型提供更大的輸入。
內存占用率降低 9 倍
SE(3)-Transformer 是已知的記憶重模型,這意味著喂養大輸入,如大蛋白質或許多分批小分子是一項挑戰。對于 GPU 內存有限的用戶來說,這是一個瓶頸。
這一點在DeepLearningExamples上的 NVIDIA 實現中已經改變。圖 3 顯示,由于 NVIDIA 優化和對混合精度的支持,與基線實現相比,訓練內存使用減少了 9 倍。
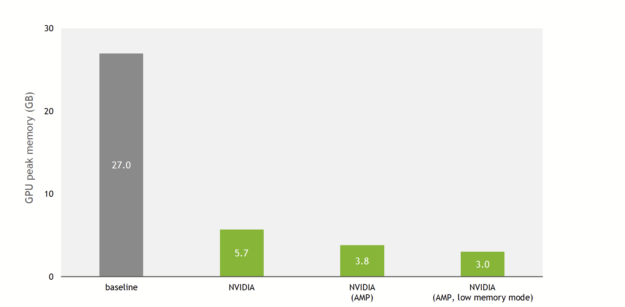
除了對單精度和混合精度進行改進外,還提供了低內存模式。啟用此標志后,模型在 TF32 ( NVIDIA 安培體系結構)或 FP16 ( NVIDIA 安培體系結構、 NVIDIA 圖靈體系結構和 NVIDIA 伏特體系結構)精度上運行,模型將切換到以吞吐量換取額外內存節省的模式。
實際上,在具有 V100 32-GB GPU 的 QM9 數據集上,基線實現可以在內存耗盡之前擴展到 100 的批大小。 NVIDIA 實現每批最多可容納 1000 個分子(混合精度,低內存模式)。
對于處理以氨基酸殘基為節點的蛋白質的研究人員來說,這意味著你可以輸入更長的序列并增加每個殘基的感受野。
SE(3)-Transformers 優化
與基線相比, NVIDIA 實現提供了一些優化。有關更多信息,請參閱/PyTorch/DrugDiscovery/SE3Transformer存儲庫中的源代碼和文檔。
融合鍵與值計算
在“自我注意”層中,將計算關鍵幀、查詢和值張量。查詢是圖形節點特征,是輸入特征的線性投影。另一方面,鍵和值是圖形邊緣特征。它們是使用 TFN 層計算的。這是 SE(3)-Transformer 中大多數計算發生的地方,也是大多數參數存在的地方。
基線實現使用兩個獨立的 TFN 層來計算鍵和值。在 NVIDIA 實現中,這些被融合在一個 TFN 中,通道數量增加了一倍。這將啟動的小型 CUDA 內核數量減少一半,并更好地利用 GPU 并行性。徑向輪廓是 TFN 內部完全連接的網絡,也與此優化融合。概覽如圖 4 所示。
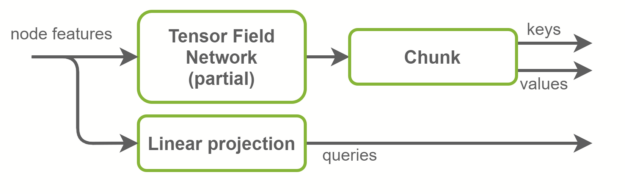
TFN 合并
SE(3)-Transformer 內部的功能除了其通道數量外,還有一個degree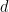


對于輸入為 4 度、輸出為 4 度的圖層,將考慮所有度的組合:理論上,必須計算 4 × 4 = 16 個子圖層。
這些子層稱為成對 TFN 卷積。圖 5 顯示了所涉及的子層的概述,以及每個子層的輸入和輸出維度。對給定輸出度(列)的貢獻相加,以獲得最終特征。
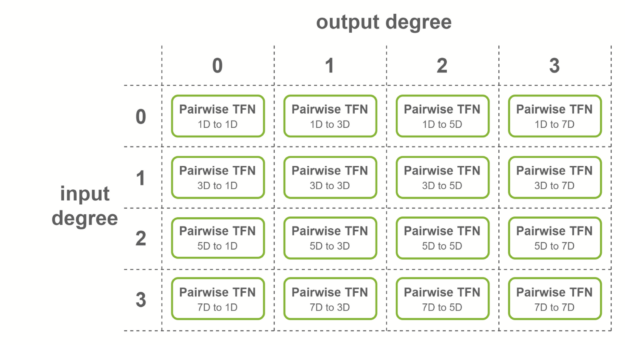
NVIDIA 在滿足 TFN 層上的某些條件時,提供多級融合以加速這些卷積。通過創建尺寸為 16 倍的形狀,熔合層可以更有效地使用張量核。以下是應用熔合卷積的三種情況:
- 輸出功能具有相同數量的通道
- 輸入功能具有相同數量的通道
- 這兩種情況都是正確的
第一種情況是,所有輸出特征具有相同數量的通道,并且輸出度數的范圍從 0 到最大度數。在這種情況下,使用輸出融合特征的融合卷積。該融合層用于 SE(3)-Transformers 的第一個 TFN 層。
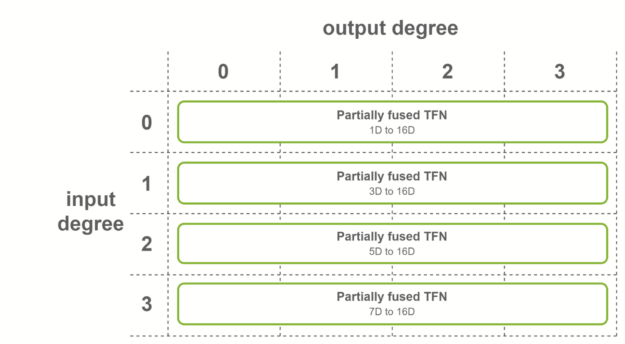
第二種情況是,所有輸入特征具有相同數量的通道,并且輸入度數的范圍從 0 到最大度數。在這種情況下,使用對融合輸入特征進行操作的融合卷積。該融合層用于 SE(3)-Transformers 的最后一層 TFN 。
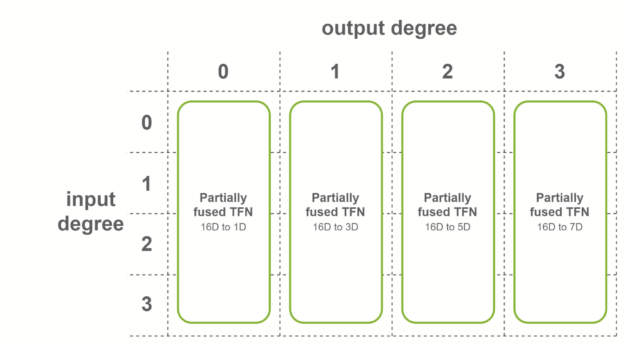
在最后一種情況下,當兩個條件都滿足時,使用完全融合的卷積。這些卷積作為輸入融合特征,輸出融合特征。這意味著每個 TFN 層只需要一個子層。內部 TFN 層使用此融合級別。
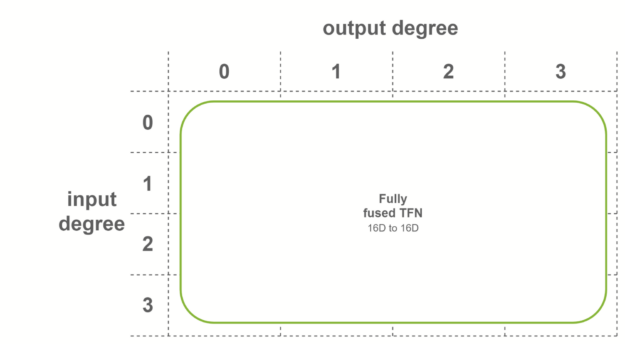
基預計算
除了輸入節點特性外, TFN 還需要基矩陣作為輸入。每個圖邊都有一組矩陣,這些矩陣取決于目標節點和源節點之間的相對位置。
在基線實現中,這些矩陣在前向傳遞開始時計算,并在所有 TFN 層中共享。它們依賴于球形 h ARM ,計算起來可能很昂貴。由于輸入圖不會隨著 QM9 數據集而改變(沒有數據擴充,沒有迭代位置細化),這就引入了跨時代的冗余計算。
NVIDIA 實現提供了在培訓開始時預計算這些基礎的選項。整個數據集迭代一次,基緩存在 RAM 中。前向傳遞開始時的計算基數過程被更快的 CPU 到 GPU 內存拷貝所取代。
結論
我鼓勵您在/PyTorch/DrugDiscovery/SE3Transformer NVIDIA GitHub 存儲庫中檢查 SE ( 3 ) – transformer 模型的實現。在評論中,分享您計劃如何采用和擴展此項目。