視覺轉換器( ViT )正在掀起計算機視覺的風暴,為具有挑戰性的現實世界場景提供了令人難以置信的準確性、強大的解決方案,并提高了可推廣性。這些算法在提升計算機視覺應用程序方面發揮著關鍵作用, NVIDIA 使用 NVIDIA TAO Toolkit 和 NVIDIA L4 GPU 可以輕松地將 ViT 集成到您的應用程序中。
ViT 的不同之處
ViT 是一種機器學習模型,它將最初為自然語言處理設計的 transformer 架構應用于視覺數據。與基于 CNN 的同類產品相比,它們有幾個優勢,并且能夠對大規模輸入進行并行處理。雖然 CNNs 使用的本地操作缺乏對圖像的全局理解,但 ViT 提供了長期依賴性和全局上下文。他們通過以并行和基于自我關注的方式處理圖像,實現所有圖像補丁之間的交互,從而有效地做到了這一點。
圖 1 顯示了 ViT 模型中圖像的處理,其中輸入圖像被劃分為較小的固定大小的補丁,這些補丁被展平并轉換為令牌序列。然后,這些標記與位置編碼一起被饋送到 transformer 編碼器中,該編碼器由多層自注意和前饋神經網絡組成。
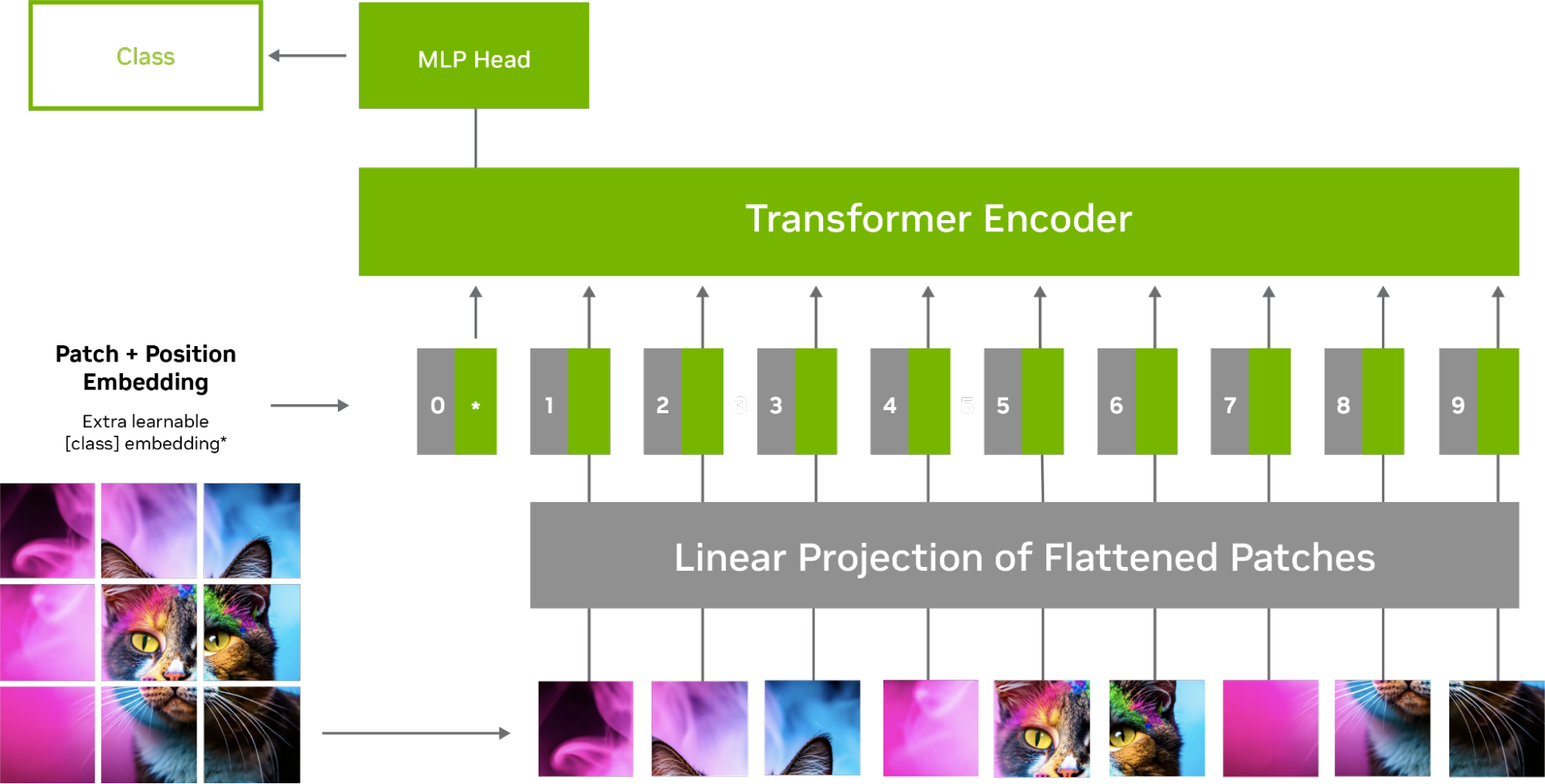
通過自關注機制,圖像的每個令牌或補丁與其他令牌交互,以決定哪些令牌是重要的。這有助于模型捕獲令牌之間的關系和依賴關系,并了解哪些令牌被認為比其他令牌重要。
例如,對于鳥的圖像,模型更關注重要特征,如眼睛、喙和羽毛,而不是背景。這轉化為提高了訓練效率,增強了對圖像損壞和噪聲的魯棒性,以及對看不見的對象的卓越泛化能力。
為什么 ViT 對計算機視覺應用至關重要
現實世界的環境具有多樣而復雜的視覺模式。 ViT 的可擴展性和適應性使其能夠處理各種各樣的任務,而無需對特定任務的架構進行調整,這與 CNN 不同。

在下面的視頻中,我們比較了在基于 CNN 的模型和基于 ViT 的模型上運行的嘈雜視頻。在任何情況下, ViT 都優于基于 CNN 的模型。
將 ViTs 與 TAO Toolkit 5.0 集成
TAO 是一個用于構建和加速視覺人工智能模型的低代碼人工智能工具包,現在您可以輕松地構建 ViT 并將其集成到您的應用程序和人工智能工作流中。用戶可以通過簡單的界面和配置文件快速開始訓練 ViT ,而無需深入了解模型架構。
TAO Toolkit 5.0 為流行的計算機視覺任務提供了幾個高級 ViT ,包括以下內容。
全注意力網絡( FAN )
作為 NVIDIA Research 的一個基于 transformer 的主干系列, FAN 實現了 SOTA 對各種損壞的魯棒性,如表 1 所示。這個主干族可以很容易地推廣到新的領域,對抗噪聲和模糊。表 1 顯示了 ImageNet-1K 數據集上所有 FAN 模型對于干凈版本和損壞版本的準確性。
| 模 | #第頁,共頁 | 精度(清潔/損壞) |
| FAN 微型混合動力 | 740 萬 | 80 . 1 / 57 . 4 |
| FAN 小型混合動力 | 2630 萬 | 83 . 5 / 64 . 7 |
| FAN Base Hybrid | 5040 萬 | 83 . 9 / 66 . 4 |
| FAN 大型混合動力 | 76 . 8 米 | 84 . 3 / 68 . 3 |
全球語境視野 transformer ( GC ViT )
GC ViT 是 NVIDIA Research 的一種新穎架構,可實現非常高的精度和計算效率。它解決了視覺轉換器中缺乏感應偏置的問題。它還通過使用局部自注意在 ImageNet 上使用較少的參數獲得了更好的結果,局部自注意與全局自注意相結合可以提供更好的局部和全局空間交互。
| 模 | #第頁,共頁 | 精確 |
| GC ViT xxTiny | 12 米 | 79 . 9 |
| GC ViT xTiny | 20 米 | 82 |
| GC ViT Tiny | 2800 萬 | 83 . 5 |
| GC ViT 小型 | 5100 萬 | 84 . 3 |
| GC ViT 基礎 | 90 米 | 85 |
| GC ViT 大型 | 2 . 01 億 | 85 . 7 |
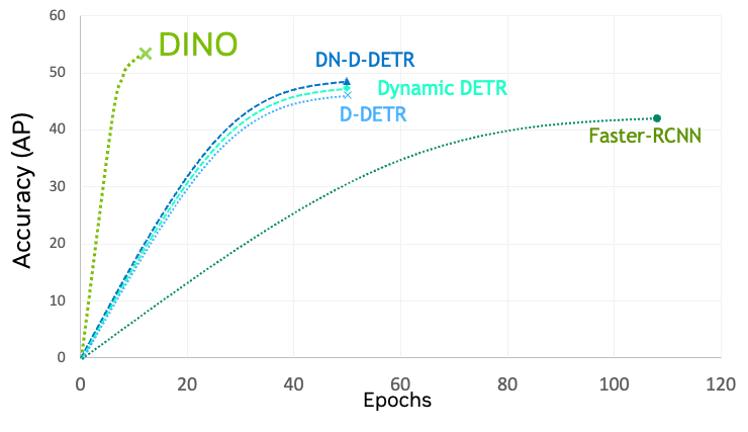
用改進的去噪錨( DINO )進行檢測 transformer
DINO 是最新一代的檢測 transformers( DETR ),與其他 ViT 和 CNNs 相比,具有更快的訓練收斂性。 TAO 工具包中的 DINO 是靈活的,可以與傳統 CNN 的各種骨干(如 ResNets )和基于 transformer 的骨干(如 FAN 和 GC ViT )相結合。
Segformer
Segformer 是一種基于 transformer 的輕量級、健壯的語義分割方法。解碼器由輕量級的多頭感知層組成。它避免了使用位置編碼(主要由 transformer s 使用),這使得推理在不同分辨率下高效。
使用 NVIDIA L4 GPU 為高效變壓器供電
NVIDIA L4 GPUs 是專為下一代視覺 AI 工作負載而設計的。它們由旨在加速變革性人工智能技術的 NVIDIA Ada Lovelace 架構驅動。
L4 GPU 適用于運行 ViT 工作負載,具有 FP8 485 TFLOP 的高計算能力和稀疏性。與更高的精度相比, FP8 降低了內存壓力,并顯著加快了 AI 吞吐量。
L4 具有多功能性和節能性,具有單插槽、低外形,是視覺 AI 部署(包括邊緣位置)的理想選擇。
觀看這個Metropolis Developer Meetup,按需了解有關 ViTs、NVIDIA TAO Toolkit 5.0 和 L4 GPU 的更多信息。
?






