
出色的 AI 性能需要高效的并行計算架構、高效的工具堆棧和深度優化的算法。NVIDIA 發布了 NVIDIA TensorRT-LLM,它包括專為 NVIDIA RTX GPU 設計的優化,以及針對 NVIDIA Hopper 架構 的優化,這些架構是 NVIDIA H100 Tensor Core GPU 的核心,位于 NVIDIA Omniverse 中。這些優化使得如 Lama 2 70B 等模型能夠在 H100 GPU 上利用加速的 FP8 運算進行執行,同時保持推理準確性。
在最近的一次發布活動中,AMD 談到了 H100 GPU 與其 MI300X 芯片相比的推理性能。分享的結果沒有使用經過優化的軟件,如果基準測試正確,H100 的速度會提高 2 倍。
以下是在 Llama 2 70B 模型上搭載 8 個 NVIDIA H100 GPU 的單個 NVIDIA DGX H100 服務器的實際測量性能。這包括“Batch-1”(一次處理一個推理請求)的結果,以及使用固定響應時間處理的結果。
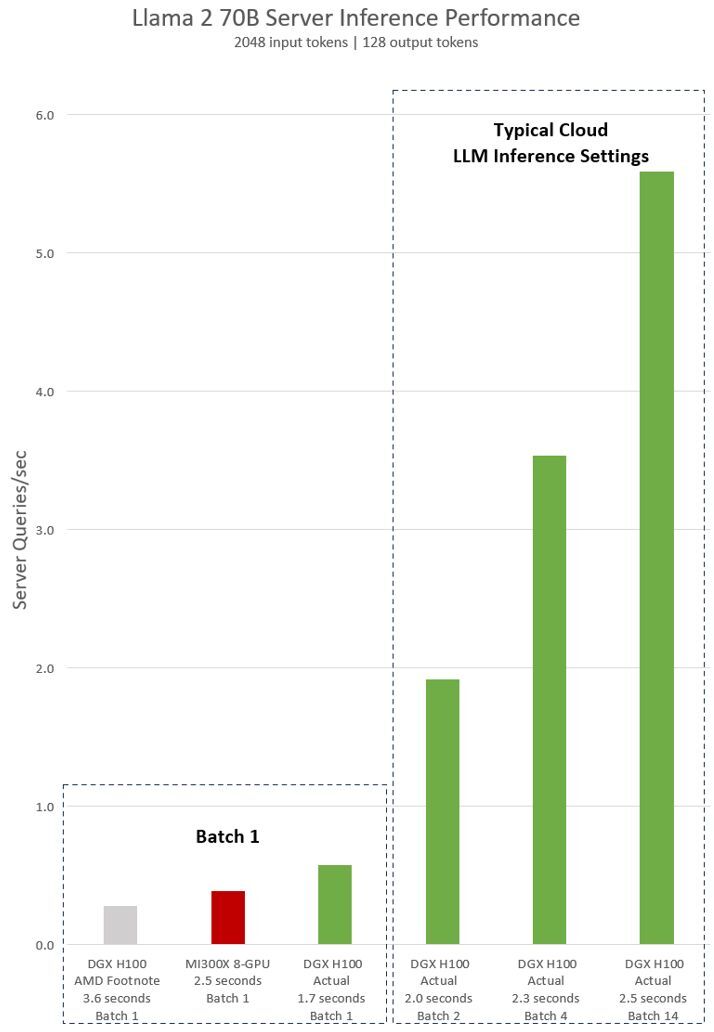 圖 1.Lama 2 70B 服務器每秒查詢的推理性能,具有“Batch 1”的 2048 個輸入令牌和 128 個輸出令牌,以及各種固定響應時間設置
圖 1.Lama 2 70B 服務器每秒查詢的推理性能,具有“Batch 1”的 2048 個輸入令牌和 128 個輸出令牌,以及各種固定響應時間設置AMD 對 H100 的隱含聲明基于 AMD 發布演示腳注#MI300-38 中的配置進行衡量。使用配備 NVIDIA DGX H100 系統的 vLLM v.02.2.2 推理軟件,Llama 2 70B 查詢的輸入序列長度為 2048,輸出序列長度為 128.他們聲稱與配備 8 塊 GPU MI300X 系統的 DGX H100 相比,性能相對較好。
對于 NVIDIA 測量數據,DGX H100 配備 8 塊 NVIDIA H100 Tensor Core GPU,搭載 80 GB HBM3 和公開發布的 NVIDIA TensorRT-LLM,v0.5.0 用于Batch 1,v0.6.1 用于延遲值測量。工作負載詳細信息與腳注#MI300-38 相同。
DGX H100 可以在 1.7 秒內處理單個推理,而批量大小為 1 (換言之,一次一個推理請求)。批量大小為 1 的結果可實現更快的模型響應時間。為了優化響應時間和數據中心吞吐量,云服務為特定服務設置固定的響應時間。這使他們能夠將多個推理請求組合成更大的“批量”,并增加服務器每秒的總體推理次數。MLPerf 等行業標準基準測試也使用這個固定的響應時間指標來衡量性能。
在響應時間方面進行細微的權衡會產生服務器可以實時處理的推理請求數量的 x 系數。使用固定的 2.5 秒響應時間預算,8 GPU DGX H100 服務器每秒可處理超過 5 次 Llama 2 70B 推理,而在批量 1 中,每秒可處理的推理不到 1 次。
AI 正在飛速發展,NVIDIA CUDA 生態系統讓我們能夠快速且持續地優化整個技術棧。我們期待每次軟件更新都能進一步提升 AI 性能,因此請確保查看我們的性能頁面以及GitHub 頁面以獲取最新信息。
如何重現這些 AI 推理結果
DGX H100 AMD 腳注由 NVIDIA 在 vLLM 中根據 AMD 在其腳注中提供的配置進行測量,并提供了vLLM 和基準測試腳本,使用以下命令行:
$ python benchmarks/benchmark_latency.py --model "meta-llama/Llama-2-70b-hf" --input-len 2048 --output-len 128 --batch-size 1 -tp 8 |
MI300X 8 芯片系統是基于 AMD 聲稱的DGX H100 AMD 腳注測量 vLLM 結果。
測量的 DGX H100 由 NVIDIA 使用公開可用的 TensorRT-LLM 版本進行測量,詳情請見 GitHub,并使用 TensorRT-LLM 基準測試中列出的命令行,參考 Llama 2 指南。
// Build TensorRT optimized Llama-2-70b for H100 fp8 tensorcore$ python examples/llama/build.py --remove_input_padding --enable_context_fmha --parallel_build --output_dir DTYPE.float16_TP.8_BS.14_ISL.2048_OSL.128 --dtype float16 --use_gpt_attention_plugin float16 --world_size 8 --tp_size 8 --pp_size 1 --max_batch_size 14 --max_input_len 2048 --max_output_len 128 --enable_fp8 --fp8_kv_cache --strongly_typed --n_head 64 --n_kv_head 8 --n_embd 8192 --inter_size 28672 --vocab_size 32000 --n_positions 4096 --hidden_act silu --ffn_dim_multiplier 1.3 --multiple_of 4096 --n_layer 80// Benchmark Llama-70B$ mpirun -n 8 --allow-run-as-root --oversubscribe ./cpp/build/benchmarks/gptSessionBenchmark --model llama_70b --engine_dir DTYPE.float16_TP.8_BS.14_ISL.2048_OSL.128 --warm_up 1 --batch_size 14 --duration 0 --num_runs 5 --input_output_len 2048,1;2048,128 |
?








