這篇文章介紹了 NVIDIA GPU s 上異步計算和重疊的最佳實踐。要在應用程序中獲得高且一致的幀速率,請參閱所有高級 API 性能提示.
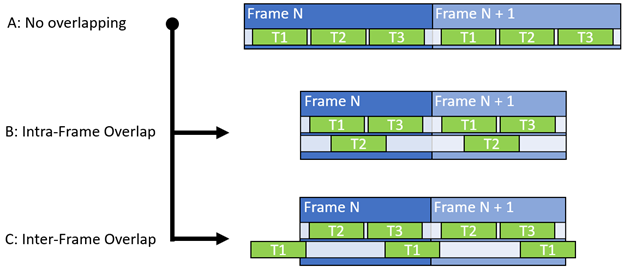
異步計算背后的一般原則是通過減少未使用的扭曲插槽的數量來提高整體單元吞吐量,并促進同時使用非沖突數據路徑。 GPU 最基本的通信設置使用單個隊列同步推送和執行圖形、計算和復制工作負載(圖 1-a )。
在理想情況下,所有工作負載都會產生較高的單位吞吐量(圖 2-A ),并使用所有可用的扭曲插槽(圖 2-B )和不同的數據路徑。實際上,只有一小部分最大單位吞吐量被真正使用。異步計算通過并行處理多個工作負載并有效提高總體處理吞吐量,為您提供了增加硬件單元使用的機會。
一個典型的錯誤是只關注 SM 占用(未使用的扭曲插槽)來識別潛在的異步計算工作負載。 GPU 是一個復雜的龐然大物,其他指標,如最高單位吞吐量( SOL )發揮著與 SM 占用率同等甚至更重要的作用。有關更多信息,請參閱優化任何 GPU 工作負載的峰值性能百分比分析方法。
因此,除了 SM 占用之外,還應該考慮單位吞吐量、登記文件占用、組共享內存和不同數據通路。在確定理想對之后,計算工作負載被移動到異步隊列(圖 1 、 B 和 C )。它使用圍欄與同步/主隊列同步,以確保正確的執行順序。
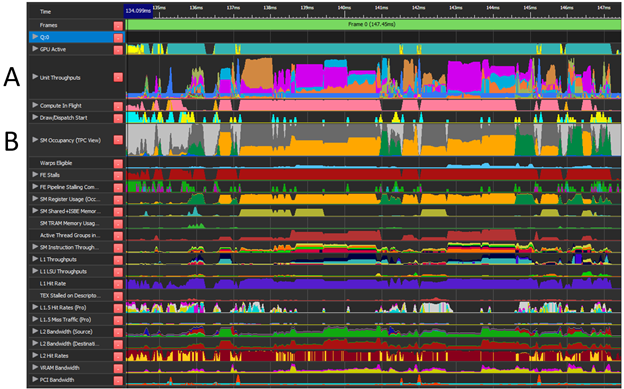
NSight Graphics 提供了 GPU 跟蹤功能(圖 2 ),它提供了在整個幀中采樣的各種 GPU 單元的詳細性能信息。此性能信息對于確定潛在的工作負載重疊至關重要。
知道從哪里開始尋找是識別潛在重疊機會的關鍵。總是首先考慮單位吞吐量,因為它代表某一單元類型可以操作的理論最大百分比( SOL )。它還有助于識別正在使用的數據路徑的類型。
試圖將工作負載和單位吞吐量疊加到最大百分比( 100% )上不僅不起作用,還會降低總體性能。
當你在尋找單位吞吐量和 SM 占用時,也考慮資源障礙和管道變化。 GPU 完全能夠跨不同的 SMs 同時處理一批微小的 draw 呼叫,其中每個呼叫分別負責少量的扭曲。如果條件合適,它甚至可以將它們合并成一個塊。
更改圖形、計算或復制工作負載類型(也稱為子通道開關)或在同一隊列上使用 UAV 屏障會觸發等待空閑( WFI )任務。 WFI 強制將同一隊列上的所有扭曲完全排空,從而在單位吞吐量和 SM 占用率中留下工作負載間隙。
如果 WFI 是不可避免的,并且會導致很大的吞吐量缺口,那么使用異步計算來填補這一缺口可能是一個很好的解決方案。屏障和 WFI 的共同來源如下:
- 繪制、分派或復制調用之間的資源轉換(障礙)
- 無人機屏障
- 光柵狀態更改
- 在同一隊列上背對背混合使用 draw 、 dispatch 和 copy 調用
- 描述符堆更改
推薦
- 使用 NSight NVIDIA 圖形提供的 GPU 軌跡識別潛在的重疊對:
- 尋找低頂層單元吞吐量指標的組合。
- 如果 SM 占用顯示了大量未使用的扭曲槽,那么它可能是一個有效的重疊。 SM Idle% 在沒有沖突的高通量單元的情況下幾乎總是一個有保證的改進。
- 捕獲另一個 GPU 跟蹤以確認結果。
- 嘗試重疊不同的數據路徑。例如, FP 、 ALU 、內存請求、 RT 核、張量核、圖形管道。
- FP 、 ALU 和 Tensor 共享不同的寄存器文件。
- 將計算工作負載與其他計算工作負載重疊。這種方案在 NVIDIA 安培結構 GPU 上非常有效。
- 考慮將一些圖形工作(如后處理傳遞)轉換為計算:這可以提供新的重疊機會。
- 考慮在幀之間運行異步工作(圖 1-C )。
- 如果實現了幀內異步計算,則測量整個幀上的性能差異或多個幀上的平均性能差異。
- 驗證不同 GPU 層之間的行為。高端 GPU 有更多的 SM 單元,因此重疊的可能性更大。
- 驗證不同分辨率下的行為。低分辨率通常意味著更少的像素扭曲,因此 SMs 的空閑時間更長,重疊可能性更大。
不推薦
- 不要只關注 SM warp 的占用率,從查看單位吞吐量開始。
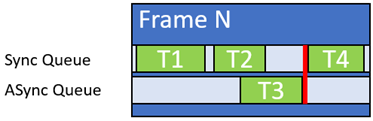
- 不要使用長異步計算工作負載,除非它們可以在依賴同步隊列之前輕松完成(圖 3 )。
- 不要重疊使用相同資源進行讀寫的工作負載,因為這會導致數據危險。
- 不要將工作負載與高 L1 和 L2 使用率以及 VRAM 吞吐量指標重疊。過度訂閱或緩存命中率降低將導致性能下降。
- 如果硬件加速 GPU 調度被禁用,請小心使用兩個以上的隊列。來自兩個以上隊列(復制隊列除外)的軟件計劃工作負載可能會導致工作負載序列化。
- 小心計算工作負載重疊,兩者都會導致 WFI 。在兩個隊列上同時進行計算期間, WFI 會導致跨工作負載的同步。異步隊列上頻繁的描述符堆更改可能會導致額外的 WFI 。
- 不要使用 DX12 命令隊列優先級來影響異步和同步工作負載優先級。該接口僅指示首先使用命令的隊列,并且不會以任何有意義的方式影響扭曲優先級。
- 不要重疊 RTCore 工作負載。兩者共享相同的吞吐量單元,并且由于干擾會降低性能。
GPU 視圖示例
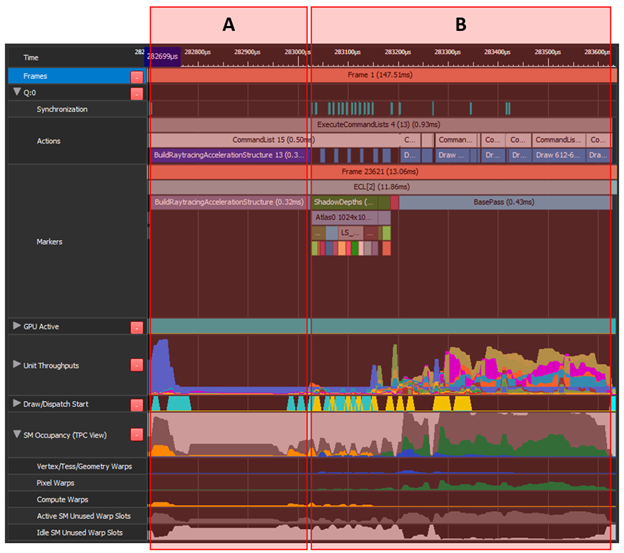
將“ A ”(構建加速結構)移動到“ B ”(陰影映射和 gbuffer )上的異步計算。“ A ”具有較低的頂部單元吞吐量和許多未使用的翹曲插槽。這同樣適用于“ B ”的前約 40% ,組合起來可以是有效的重疊。
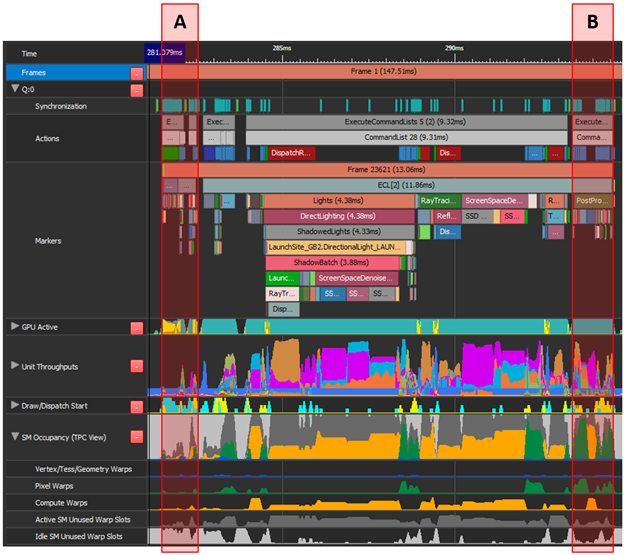
“ A ”由角色蒙皮、復制調用和一些圖形組成。最高吞吐量單元為 PCI 12 . 7% 。“ B ”執行后處理,即圖形和計算工作的混合,最高平均吞吐量指標為 37 . 6% 。
這兩個區域沒有沖突的最高吞吐量單元,并且在下一幀的“ A ”上重疊的“ B ”也利用了幀之間浪費的扭曲槽。然而,具有挑戰性的部分是將所有圖形工作轉換為計算并觸發異步隊列中存在的幀。
潛在重疊組合
表 1 顯示了一些常見的重疊組合和提供的 rational 。在執行這些應用程序之前,首先要考慮應用程序的單位吞吐量。
| Workload A | Workload B | Rational |
| Math-limited compute | Shadow map rasterization | Shadow maps are usually graphics-pipe dominated (CROP, PROP, ZROP, VPC, RASTER, PD, VAF, and so on) and have little interference with heavy compute work. |
| Ray tracing | Math-limited compute | If RT is RTCore dominated, the time spent traversing triangles in the BVH can be overlapped with something like denoising for the previous ray tracing pass or some other math-limited post-processing pass. |
| DLSS | Build Acceleration Structure | The majority of the DLSS workload is executed on Tensor Cores, leaving the FP and ALU datapaths mostly unused. Building acceleration structures usually has a low throughput impact and mostly depends on FP and ALU datapaths, making it an ideal overlap-candidate for DLSS. |
| Any long workload | Many short workloads with back-to-back resource synchronization or UAV barriers. | Back-to-back resource synchronization is usually damaging for efficient unit throughput and SM warp occupancy, which provides an opportunity to be overlapped with async compute. |
| Post-process at the end of previous frame | G-buffer fills at the start of next frame | Inter-frame overlap can provide substantial perf gains, provided the application is able to invoke Present() from the compute queue. |
| Build acceleration structure | G-Buffer, shadow maps, and so on | Both workloads A and B are common to underuse the throughput units or to use non-conflicting paths. In addition, build acceleration structure is a compute workload and is fairly easy to move onto the async queue. |
| Ray tracing | Shadow map rasterization | RTCore / FP overlaps Graphics (ZROP/PROP/RASTER) datapath. See Example 1. |
致謝
特別感謝您審閱并向 Alexey Pantelev 、 Leroy Sikkes 、 Louis Bavoil 和 Patrick Neill 提供寶貴反饋。