
這篇文章介紹了 NVIDIA GPU 上網格著色器的最佳實踐。要在應用程序中獲得高且一致的幀速率,請參閱所有高級 API 性能提示.
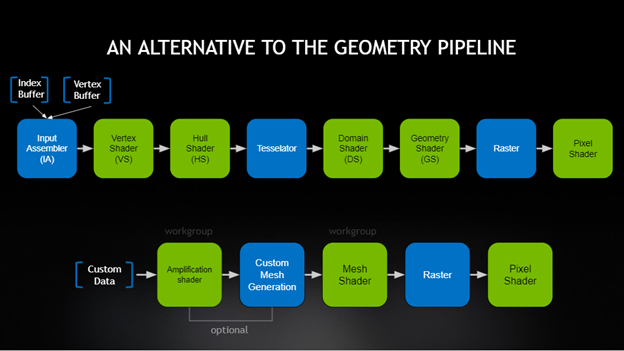
網格著色器是最近添加到編程管道中的一種,旨在克服經典幾何管道使用的固定布局的瓶頸。本文介紹了 DirectX 和 Vulkan 開發人員的最佳實踐。
推薦
- 分割數據時,使用 64 個唯一頂點和 126 個三角形基本體的值,中間甜點為 40 和 84 。這里的重點是組織實現,以便直接使用不同的分段進行實驗。
- 盡可能減少放大和網格著色器中的有效負載大小:
- 使用位壓縮和量化表示
- 用重心替換屬性,并允許像素著色器獲取和插值屬性
- 網格和放大著色器階段為 LoD 選擇和進一步剔除策略提供了機會。這些可在不同粒度下實現,例如:
- 在 AS 階段:剔除簇或進行管道 LoD 決策
- 在 MS 階段:剔除單個原語
- 如果很簡單,可以提前做出決策,并使用應用程序中可用的推斷數據。這樣可以節省大量的工作。請記住,不需要模擬更復雜的剔除方案,默認情況下,硬件會有效地模擬這些方案。
- 在處理程序實例化時,依賴放大著色器和網格著色器,例如頭發或植被、 iso 曲面(流體模擬、醫學成像中的體素數據)、從 3D 掃描獲得的資源、 LOD 以及 CAD 應用程序中經常遇到的一般詳細模型。
- 考慮特殊網格的拓撲連通性。與顯示稀疏拓撲的網格(如粒子)相比,我有單獨的實現來處理密集拓撲。
- 請注意,放大著色器階段會增加開銷,盡管通常這可以忽略不計。
- 有關更多信息,請參閱為專業圖形使用網格著色器。
Vulkan
- 與 DX 相比,
VK_NV_mesh_shader中的網格著色器允許對網格輸出進行任意讀寫訪問,這些輸出是預先分配的。您可以通過直接使用或重新調整這些輸出的用途來獲得性能,并避免額外的共享內存分配。
不推薦
- 避免放大著色器的大輸出,因為這會導致嚴重的性能損失。通常,我們鼓勵靈活的實現,允許微調。考慮到這一點,有許多通用因素會影響性能:
- 有效載荷的大小。 AS 有效負載最好保持在 108 / 236 字節以下。
- 放大著色器的調用次數。
- 由相應放大著色器發射的網格著色器數(放大率)。
- 不要嘗試使用放大和網格著色器模擬固定函數管道,因為這可能會增加冗余。
- 避免在每一幀的新網格中分割,并考慮脫機烘焙這些數據,這允許在空間或頂點重用中優化網格。
致謝
感謝 Jakub Boksansky 的建議和反饋。
?






