檢索增強生成 (RAG) 應用程序如果能夠處理各種數據類型,包括表格、圖形和圖表,而不僅僅是文本,其效用將會呈指數級增長。這就需要一個能夠通過一致的解釋文本、視覺和其他形式的信息來理解和生成響應的框架。
在本文中,我們將討論應對多種模式和方法以構建多模態 RAG 工作流所面臨的挑戰。為保持討論簡潔,我們只關注兩種模式,即圖像和文本。
為什么多模態很難實現?
企業 (非結構化) 數據通常分布在多種模式下,無論是充滿高分辨率圖像的文件夾,還是包含混合文本表格、圖表、圖形等的 PDF 文件。
在使用這種模式時,需要考慮兩個要點:每種模式都有自己的挑戰,以及如何跨模式管理信息?
每種模式都有自己的挑戰
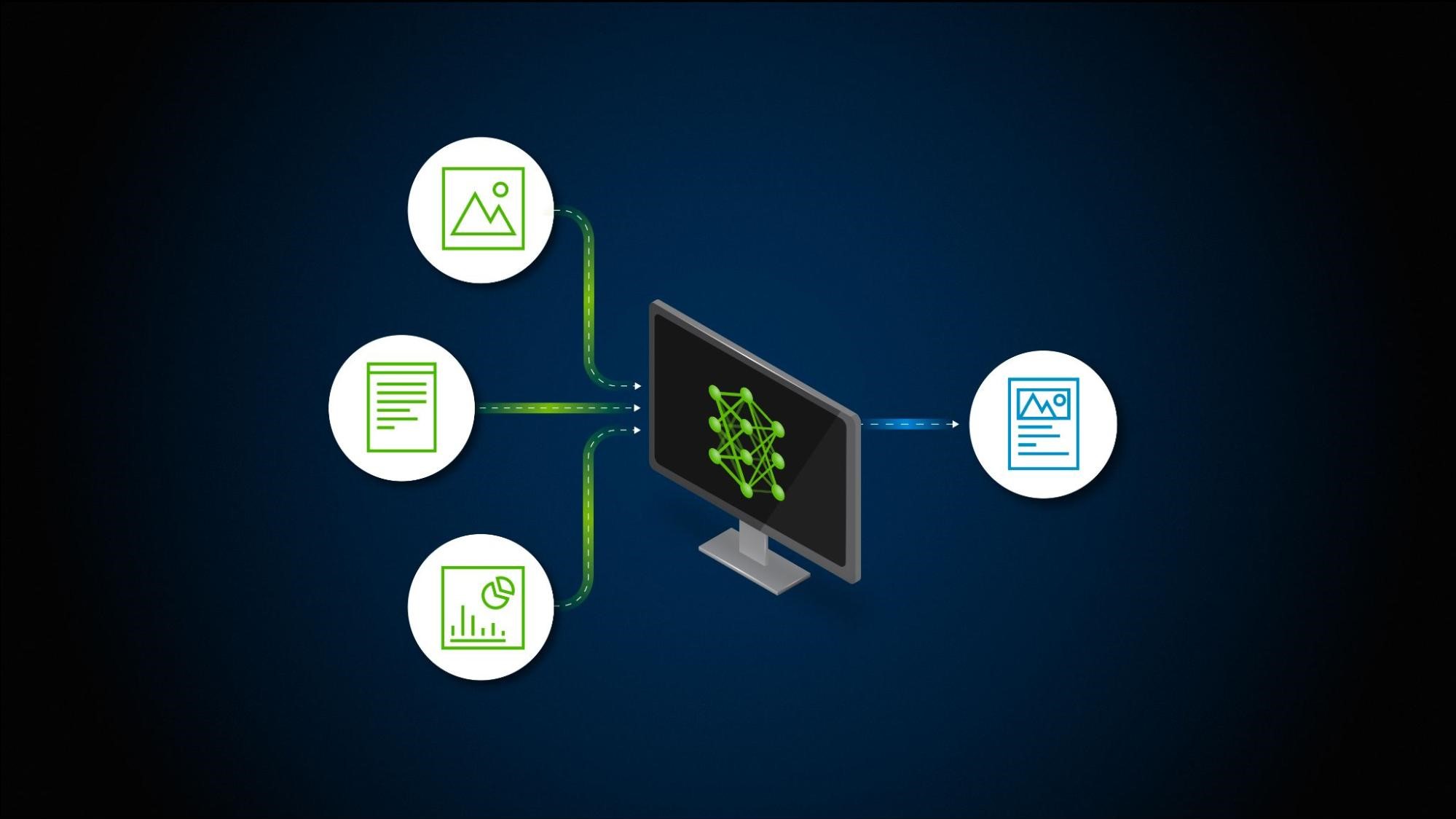
以圖像為例 (圖 1)。對于左側的圖像,重點更多的是一般圖像,而不是微小的細節。只關注幾個關鍵點,如池邊、海洋、樹木和沙灘。

報告和文檔可能包含信息密集型圖像 (如圖表和圖表),這些圖像具有許多興趣點和可從圖像衍生的其他上下文。無論您構建何種工作流,都必須捕捉并解決這些細微差別,以有效嵌入信息。
如何跨模式管理信息?
另一個重要方面是跨不同模式表示信息。例如,如果您使用的是文檔,則必須確保圖表的語義表示與討論同一圖表的文本的語義表示保持一致。
多模態檢索方法
我們已了解關鍵挑戰,以下是構建 RAG 工作流以應對這些挑戰的具體內容。
構建多模態 RAG 工作流的主要方法有以下幾種:
- 將所有模式嵌入同一向量空間
- 將所有模式整合到一個主要模式中
- 為不同模式提供單獨的商店
為使本次討論保持簡潔,我們僅討論圖像和文本輸入。
將所有模式嵌入同一向量空間
對于圖像和文本,您可以使用 CLIP 在同一向量空間中對文本和圖像進行編碼。這使得您可以在很大程度上使用相同的純文本 RAG 基礎設施,并交換嵌入模型以適應另一種模式。對于生成通道,您可以替換 大型語言模型(LLM),使用多模態 LLM (MLLM) 來處理所有問答。這種方法簡化了管道,因為通用檢索管道中唯一需要的更改是交換嵌入模型。
在這種情況下,我們的取舍是訪問一個模型,該模型可以有效地嵌入不同類型的圖像和文本,并捕獲圖像和復雜表格中的文本等所有復雜內容。
將所有模式整合到一個主要模式中
另一種選擇是根據應用程序的重點選擇主要模式,并將所有其他模式都接入主要模式。
例如,假設您的應用程序主要圍繞基于文本的問答 (而非 PDF) 展開。在這種情況下,您通常會處理文本,但對于圖像,您會在預處理步驟中創建文本描述和元數據。您還會存儲圖像以供日后使用。
然后,在推理通道中,檢索主要從圖像的文本描述和元數據開始,根據檢索的圖像類型,混合使用 LLM 和 MLLM 生成答案。
這樣做的主要好處是,從信息豐富的圖像中生成的元數據對于回答客觀問題非常有幫助。這還可以解決調整用于嵌入圖像的新模型的需求,以及構建重新排名器以對不同模式下的結果進行排名的需求。主要缺點是預處理成本和圖像的一些細微差別。
為不同模式提供單獨的商店
Rank-rerank 是一種方法,您可以為不同的模式維護單獨的數據庫,并查詢所有數據庫以檢索 N 個結果。然后,讓專用的多模態重排名器提供最相關的結果。
這種方法簡化了建模過程,因此您不必對齊一個模型以使用多個模式。但是,它增加了重新排名器形式的復雜性,以安排 now – top-M*N塊 (N來自M模式)。
用于生成的多模態模型
LLM 旨在理解和生成基于文本的信息。這些模型基于大量文本數據進行訓練,能夠執行一系列自然語言處理任務,如文本生成、總結、問答等。
MLLM 可以感知的不僅僅是文本數據。MLLM 可以處理圖像、音頻和視頻等模式,這通常是真實數據的構成方式。它們將這些不同的數據類型結合起來,對信息進行更全面的解釋,從而提高預測的準確性和可靠性。
這些模型可以執行各種任務:
- 視覺語言理解和生成
- 多模態對話
- 圖片說明
- 視覺問答 (VQA)
在處理多種模式時,RAG 系統可以從這些任務中受益。要更深入地了解 MLLM 如何處理圖像和文本,需要了解這些模型的構建方式。
MLLM 的一個熱門子類型是 Pix2Struct,這是一種預訓練的圖像到文本模型,通過其新穎的預訓練策略實現了對視覺輸入的語義理解。顧名思義,這些模型能夠生成基于圖像提取的結構化信息。例如,Pix2Struct 模型可以從圖表中提取關鍵信息,并以文本形式表示。
理解了這一點后,您可以在此處了解如何構建 RAG 管道。
為多模態 RAG 構建管道
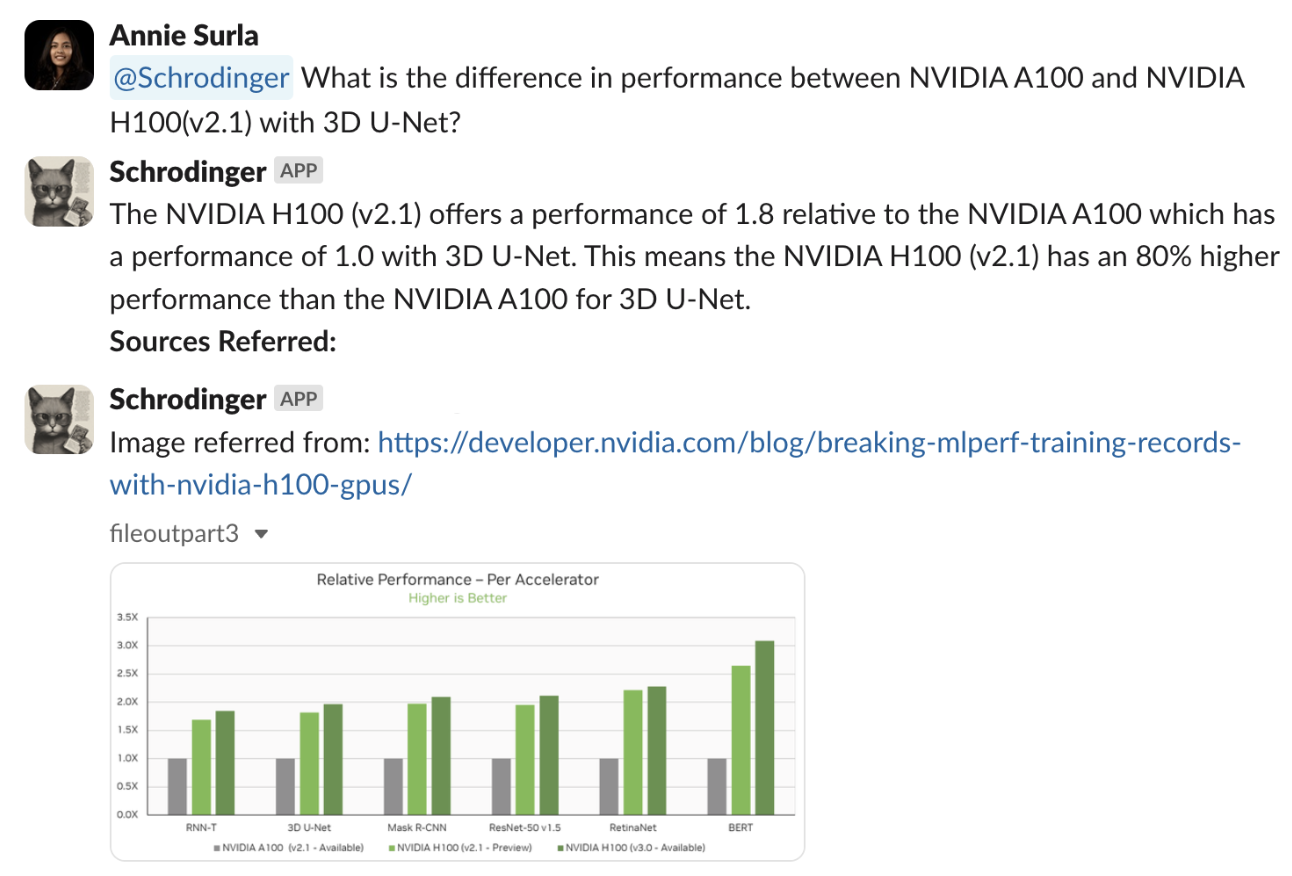
為了展示如何處理不同的數據模式,我們為您介紹了一個包含多個技術帖子索引的應用程序,例如 借助 NVIDIA H100 GPU 打破 MLPerf 訓練記錄. 本文包含復雜的圖像,這些圖像是包含豐富文本、表格數據的圖表和圖形,當然還有段落。
以下是您開始處理數據和構建 RAG 工作流之前所需的模型和工具:
- MLLM:用于圖像字幕和視覺問答(VQA)。
- LLM: 一般推理和問答。
- 嵌入模型:將數據編碼為向量。
- 向量數據庫:存儲已編碼的向量以供檢索。
解釋多模態數據并創建向量數據庫
構建 RAG 應用程序的第一步是預處理數據并將其存儲為向量,以便您可以根據查詢檢索相關向量。
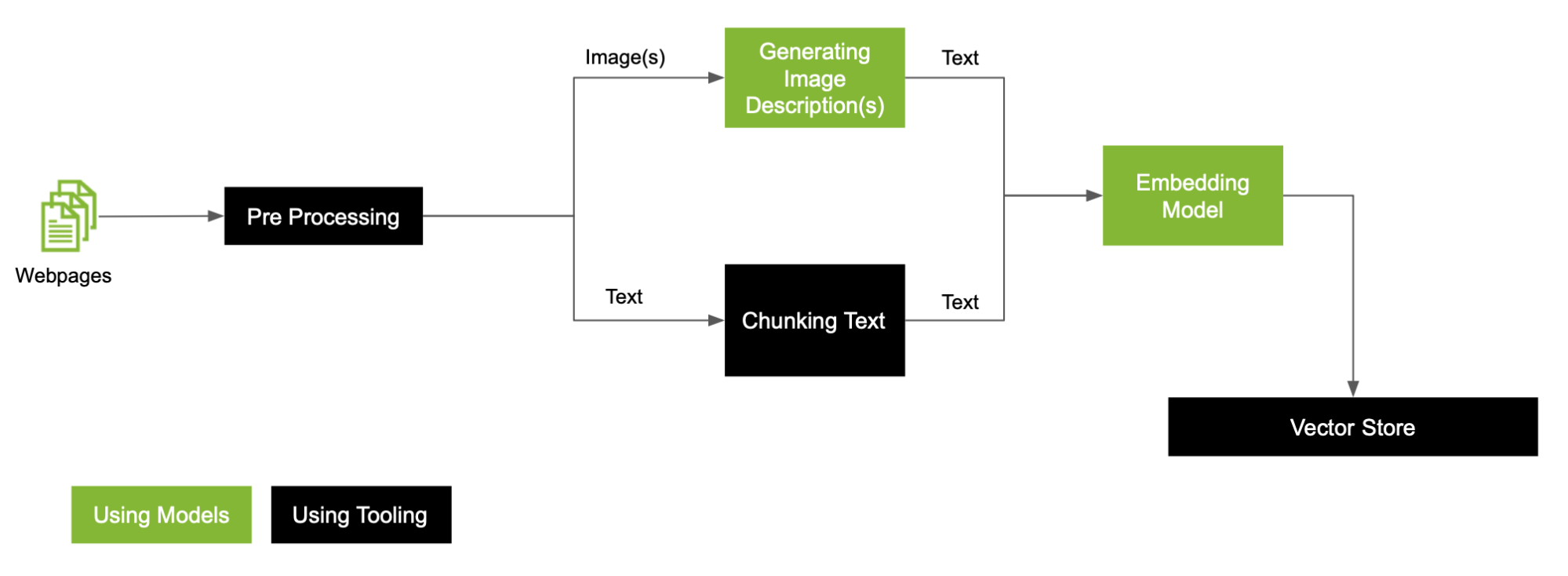
對于數據中存在的圖像,這是一個通用的 RAG 預處理工作流 (圖 2)。
這篇博文包含幾個條形圖,如圖 3 所示。要解釋這些條形圖,可以使用 Google 的 DePlot,這是一種視覺語言模型,能夠與大型語言模型(LLM)結合,以理解和解釋圖表和圖形。DePlot 模型可以在 NGC 上獲取。
有關在 RAG 應用中使用 DePlot API 的更多信息,請參閱 使用優化的 DePlot 模型查詢圖形。
此示例專注于圖表和圖形。其他文檔可能包含的圖像可能需要模型自定義來處理專用圖像,例如醫學影像或原理圖。這取決于用例,但您有幾個選項可以解決圖像中的這種差異:調整一個 MLLM 以處理所有類型的圖像,或者為不同類型的圖像構建模型集合。
為了簡化解釋,這是一個包含兩個類別的簡單集成案例:
在本文中,我們擴展了預處理工作流,以更深入地探討如何處理工作流中的每種模式,這些模式利用自定義文本分割器、自定義 MLLM 和 LLM 來創建 VectorDB (圖 4)。
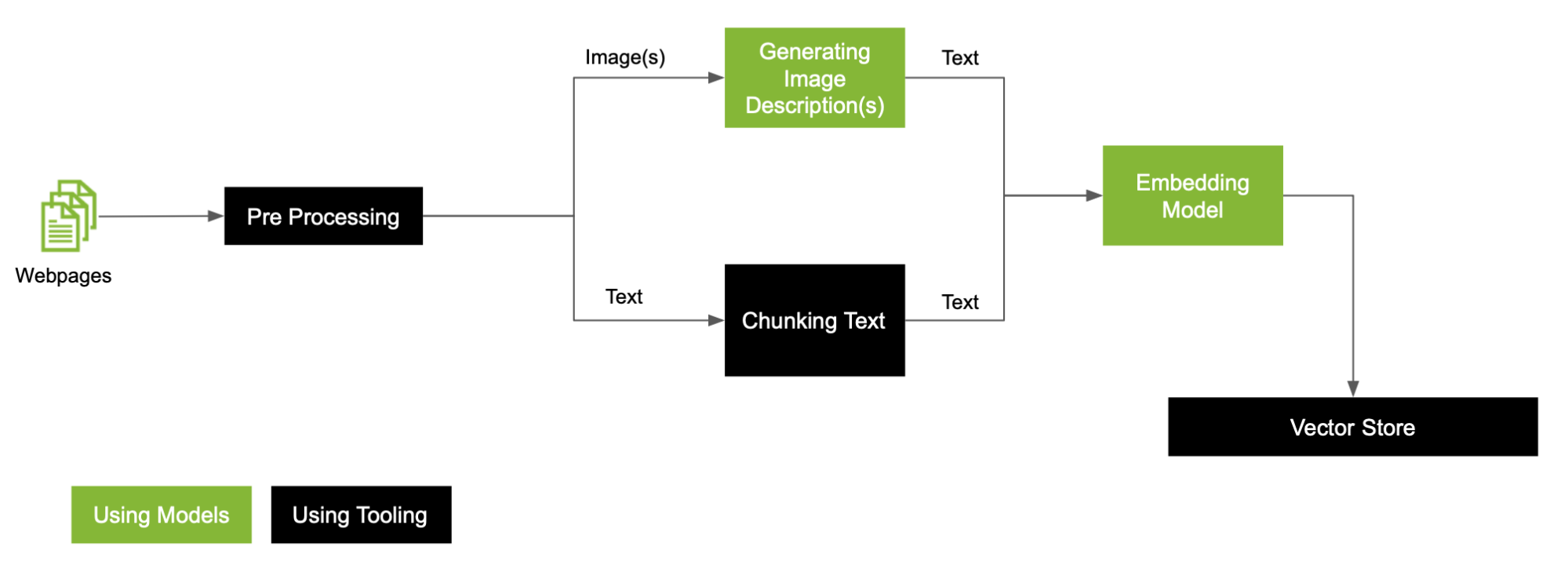
以下是預處理工作流程中的一些關鍵步驟:
- 單獨的圖像和文本
- 根據圖像類型,使用 MLLM 對圖像進行分類
- 在 PDF 中嵌入文本
單獨的圖像和文本
目標是將圖像打磨為文本模式。首先,提取和清理數據以分離圖像和文本。然后,您可以繼續處理這兩種模式,最終將其存儲在向量存儲中。
根據圖像類型,使用 MLLM 對圖像進行分類
無論圖像是否為圖形,MLLM 生成的圖像描述都可用于將圖像分為類別。根據分類,對包含圖形的圖像使用 DePlot,以生成線性化的表格文本。此文本在語義上不同于普通文本,因此在推理期間執行搜索時,很難檢索相關信息。
我們建議使用線性化文本的摘要作為塊存儲在向量存儲中,并將自定義 MLLM 的輸出作為元數據存儲,以便您在推理期間使用。
在 PDF 中嵌入文本
您可以根據所處理的數據探索各種文本分割技術,以獲得最佳 RAG 性能。為簡單起見,請將每個段落存儲為一個塊。
與向量數據庫對話
完成此流程后,您可以成功捕獲 PDF 中存在的所有多模態信息。以下是用戶提出問題時 RAG 流程的工作原理。
當用戶向系統提示問題時,簡單的 RAG 工作流會將問題轉換為嵌入,并執行語義搜索以檢索一些相關信息塊。考慮到檢索到的數據塊也來自圖像,請執行一些其他步驟,然后將所有數據塊發送到 LLM 以生成最終響應。
圖 5 展示了如何使用從圖像和文本中檢索的信息塊處理用戶查詢以回答問題的參考流程。
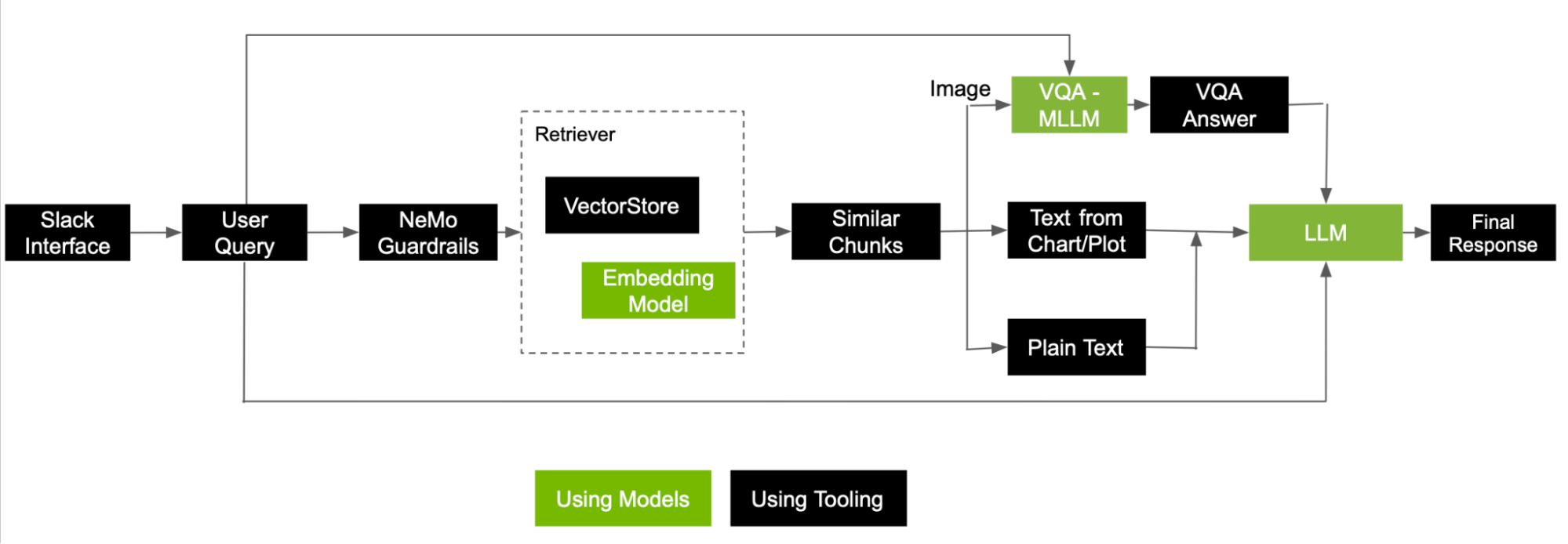
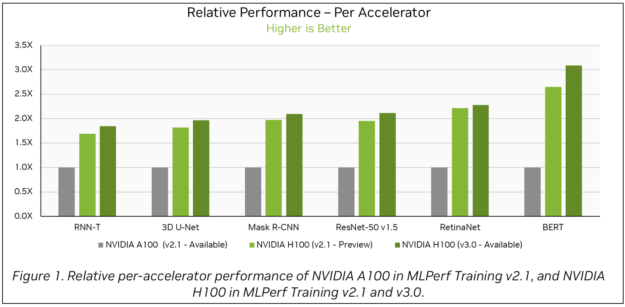
這是一個示例問題,提示可以訪問相關 PDF 的支持 RAG 的多模態機器人“ NVIDIA A100 和使用 3D U-Net 的 NVIDIA H100 (v2.1) 之間的性能差異是什么?”
該流程成功檢索了相關圖形圖像,并準確解釋了 NVIDIA H100 (v2.1),在 3D U-Net 基準測試中,每個加速器的相對性能比 NVIDIA A100 高出 80%。
以下是在執行搜索并檢索前五個相關數據塊后處理問題所涉及的一些關鍵步驟:
- 如果從圖像中提取數據塊,MLLM 會將圖像與用戶問題一起作為輸入,以生成答案。這不過是 VQA 任務。然后,生成的答案將用作 LLM 響應的最終上下文。
- 如果從圖表或繪圖中提取數據塊,請調用存儲為元數據的線性化表,并將文本作為上下文附加到 LLM。
- 最后,來自純文本的數據塊按原樣使用。
所有這些數據塊以及用戶問題現已準備就緒,可供 LLM 生成最終答案。從圖 6 中列出的來源來看,機器人參考了顯示不同基準測試的相對性能的圖表,以生成準確的最終答案。
擴展 RAG 管道
本文介紹了使用跨多種模式傳播的數據回答簡單文本問題的場景。為了進一步發展多模態 RAG 技術并擴展其功能,我們推薦以下研究領域。
解決涉及不同模式的用戶問題
假設用戶問題由包含圖形和問題列表的圖像組成,需要對流程進行哪些更改才能適應此類多模態請求?
多模態響應
基于文本的答案可能包含代表其他模式的引文,如圖 6 所示。然而,對于用戶查詢來說,書面解釋并不總是最佳結果類型。例如,可以進一步擴展多模態響應,根據請求生成圖像,如堆疊條形圖。
多模態代理
解決復雜的問題或任務不僅僅是簡單的信息檢索。這需要規劃、專用工具和提取引擎。有關更多信息,請參閱 LLM 智能體簡介。
總結
在生成式 AI 應用中,改進和探索未來多模態功能的空間仍然很大,這要歸功于多模態模型以及對 RAG 驅動的工具和服務的需求不斷增加。
如果企業能夠將多模態功能集成到其核心運營和技術工具中,則可以更好地擴展其 AI 服務和產品,以用于待列出的用例。
獲取實施 NVIDIA Omniverse 多模態 RAG 工作流程 的指導,該流程已在 GitHub 上發布。
?




