構建多模態檢索增強生成 (RAG) 系統極具挑戰性 。困難在于捕獲和索引來自多種模式的信息,包括文本、圖像、表格、音頻、視頻等。在上一篇博文《 多模態檢索增強型生成的簡單介紹 》中,我們討論了如何處理文本和圖像。本文將對話擴展到音頻和視頻。具體來說,我們將探討如何構建多模 odal RAG pipeline 來搜索視頻中的信息。
為文本、圖像和視頻構建 RAG?
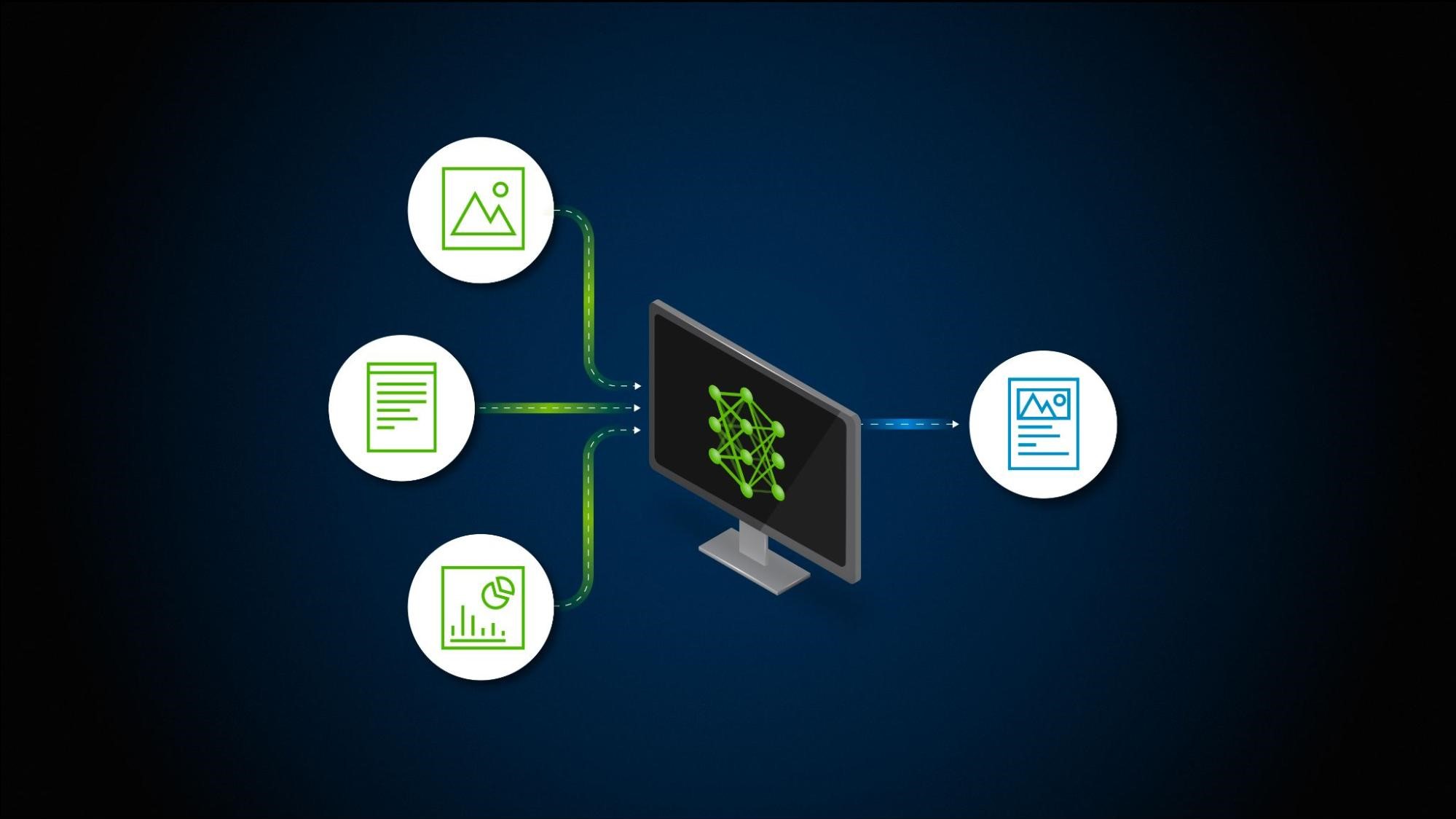
基于第一條原則,我們可以說,構建跨多個模式的 RAG 工作流有三種方法,詳見下文和圖 1。
使用通用嵌入空間
構建跨多個模態的 RAG 工作流的第一種方法是使用通用嵌入空間。這種方法依賴于單個模型來投射存儲在同一嵌入空間中不同模式下的信息表示。使用具有圖像和文本編碼器的 CLIP 等模型屬于此類別。使用這種方法的好處是降低架構復雜性。根據用于訓練模型的數據的多樣性,還可以考慮適用用例的靈活性。
這種方法的缺點是,如果模型能夠處理兩個以上的模態,或者甚至能夠處理大量子模態,則很難對其進行調整。例如,CLIP 在處理自然圖像并將其與文本描述相匹配時表現出色。然而,僅編碼文本甚至合成圖像并不可行。Fine-tuning 是提高模型性能的一個選項,但創建單個嵌入模型來編碼所有形式的信息并非易事。
構建 N 個并行檢索管道 (Brute Force)
第二種方法是使模態甚至子模態原生搜索和查詢所有管道。這將生成分布在不同模態下的多組數據塊。在這種情況下,會出現兩個問題。首先,大語言模型(LLM)需要提取的 tokens 數量大幅增加,從而增加了運行 RAG 管道的成本。其次,需要能夠跨多個模態吸收信息的 LLM。這種方法只是將問題從檢索階段轉移到生成階段并增加成本,但反過來又簡化了提取流程和基礎設施。
以通用模式接地?
最后,可以從所有模式中提取信息,并以一種常見模式 (例如文本) 為基礎。這意味著,來自圖像、PDF、視頻、音頻等的所有關鍵信息都需要轉換為文本,以便設置工作流。這種方法會產生一些提取成本,并可能導致有損嵌入,但可用于有效地統一所有模式以進行檢索和生成。

由于文本接地為處理多個子模態提供了靈活性,因此執行目標模型調優的能力只需產生一次性提取成本,即可簡化搜索和答案生成。它是構建可靠的 RAG 工作流的出色架構支柱。
以下各節將探討如何利用這一理念構建多模態 RAG 管道來搜索視頻中的信息。

視頻檢索的復雜性?
視頻內容有各種形狀和大小,包括社交媒體上的短片、長篇教程、教育系列、娛樂節目,甚至是監控錄像。每種類型的內容都以其獨特的方式保存信息,這使得視頻檢索有點平衡。
以頻譜為例 (圖 3)。從高度非結構化 (如真實視頻) 到結構化 (如教程),沿橫向軸查看視頻內容。沿垂直軸查看信息的傳輸方式。一方面,視頻包含豐富的動作序列,其中時間信息對于理解視頻至關重要。相反,視頻由幀組成,每個幀都可以獨立存在,而無需依賴序列進行理解。

另一點需要注意的是,這些信息通過音頻和視頻格式傳播。雖然我們討論了以文本等通用模式接地是設置 RAG 管道的可靠方法,但我們還需要幫助確保跨這兩種模式以’text’形式提取的信息適當對齊。
在音頻中對信息進行編碼基本上有兩種不同的方法 :
- 情感:此信息通常帶有有關信息來源的基礎上下文信息。例如,它可能是說話者的情緒激動的語氣,也可能是用來喚起視頻消費者情緒的背景評分。
- 目標:任何語言信息都被視為客觀信息,因為沒有任何主觀性的空間。
要處理視覺效果,需要考慮以下三個挑戰:
- 處理成本: 處理視頻需要大量計算。視頻的每秒通常包含 30 或 60 幀,具體取決于幀率,而幀率在存儲和處理方面會迅速增加。例如,每秒 60 幀 (FPS) 的 10 分鐘視頻包含 18,000 幀,每個視頻都需要某種程度的處理才能準確提取內容和檢索。
- 從幀中提取信息: 如之前文章所述,由于圖像包含的信息密度較大,因此很難從圖像中提取和表示信息。
- 保留分布在多個幀中的 “actions”:連續幀還可以捕獲包含重要信息的特定 actions 。很難在更大的上下文中識別 actions 并使用正確的權重表示該信息。
為視頻構建 RAG?
為了提供示例用例,假設我們想在解釋概念或演示方法的視頻講解員資源庫中提問。這些視頻類似于講座錄像、會議錄像、主題演講、教學方法和分步視頻。由于此用例主要側重于溝通和解釋信息,因此我們不需要專注于來自音頻的情感信息,也不需要保留視覺效果中的動作。
圖 4 顯示了具有五個主要部分的管道的高級架構:
- 音頻提取
- 視頻提取
- 融合音頻和視頻信息
- 設置檢索器
- 生成答案

音頻提取?
無需編碼任何情感含義,因此只需轉錄音頻即可。為此,我們采用了使用 NVIDIA Parakeet-CTC-0.6B-ASR 模型 構建的 自動語音識別 (ASR) 流程。使用該模型,轉錄音頻并創建臨時文本塊,以及詞語的詞級時間戳。雖然這種情況不需要情感含義,但語音情感識別模型或 音頻語言模型 可用于提供基于文本的描述。
視頻提取?
鑒于用例,我們將專注于降低處理視頻和從幀中提取信息的成本。
大多數視頻的錄制和存儲幀速率為 30 或 60 FPS。這意味著 1 分鐘的視頻可以包含多達 3,600 幀。雖然對于視覺消耗而言,這種高幀速率有助于提供更好的體驗,但連續幀之間的信息差異通常很小。雖然 Brute Force 方法是處理每幀幀,但這是一項極其昂貴的任務。因此,我們需要減少要處理的候選幀數量。
簡單的第一步是將視頻采樣率降至 4 FPS,將要處理的幀數大幅減少到 240 幀。視頻幀之間通常只有細微差別,因為每個視頻幀之間的時間差相對較小。這會導致大多數幀的信息重疊。
自然,下一步是識別關鍵幀,這些關鍵幀所攜帶的信息量是“局部最大值”,這包括三個步驟。
首先,通過識別鏡頭邊界對視頻進行分節。為此,我們可以使用經典的計算機視覺技術,利用不斷變化的 色彩空間 中的圖案,或利用 鏡頭檢測模型 。需要進行章節化,以創建本地上下文來判斷幀中存在的信息。
其次,識別每個章節中的“關鍵片段”。這需要識別視覺效果在感知上獨特或捕捉某些獨特活動的所有片段。這可以使用 image encoder 或 signal processing filter 來完成,后者可以在兩個連續幀中捕獲差異。
為簡單起見,假設我們使用 Structural Similarity Index (SSIM) 計算跨幀差異 (圖 5)。然后,我們使用差異大于場景均值標準差的起始幀,并將結束幀用作相似性指標的局部最大值,以此來識別這些片段。使用一個標準偏差差表示唯一差值,并等待再次達到局部最大值,從而在連續結構相似的幀開始最大化相似度得分時捕獲大部分動作。

最后,檢測到這些片段后,我們會拒絕所有模糊濾鏡和重復濾鏡。然后選擇所有具有高熵的幀,因為它們擁有更多信息。
所有討論的步驟都有助于將幀數減少到 40 幀,遠低于每分鐘 3600 幀的處理速度。請注意,我們使用的是經典的計算機視覺算法。使用微調模型進行幀選擇和重復數據刪除將產生更少的選定幀,從而進一步減少要處理的幀數量。
現在我們已經提取了代表性幀,下一步是從中提取所有可能的信息。為此,我們使用 Llama-3-90B VLM NIM 。我們提示 VLM 為屏幕上的所有文本和信息生成轉錄,并生成語義描述。
融合音頻和視頻信息?
從音頻和視頻內容中提取的文本信息被捆綁在一起,以從視頻中獲得統一的提取。 NVIDIA Riva ASR 使用詞級時間戳進行轉錄,從而輕松關聯回選定的關鍵幀。
請記住,來自關鍵幀 (之前選擇的) 的信息必須與圍繞幀播放的音頻對齊。這使得關鍵幀能夠獲取暫時發生的情況的上下文。一種簡單的方法是使用先前生成的場景時間戳在場景級別混合信息。有了它,我們可以提取時間戳內的音頻,并將從多個關鍵幀中提取的文本附加到音頻塊中,以便為場景創建文本塊。
您可以嘗試在時間級別(而非場景級別)將視頻內容與音頻內容完美融合。請注意,這些方法可能會出現重復信息,其中視頻內容直接附加音頻。例如,如果音頻中的演講者通過幻燈片講話,音頻和視頻內容會有很大的重疊,從而生成額外的 tokens,添加到額外的延遲和成本。
或者,我們可以使用較小的 LLM 來幫助將提取的視覺環境附加到音頻中。額外的 LLM 調用有助于在提取期間減少 token,這有助于節省對檢索和答案生成進行實時推理的時間和成本。
設置檢索器?
在發布基于文本的音視頻混合后,我們現在對視頻進行了連貫一致的文本描述。我們還保留詞級句子和幀的時間戳以及文件級元數據,例如文件名。使用這些信息,我們創建由元數據增強的數據塊,并使用嵌入模型生成嵌入。這些嵌入與作為元數據的塊級時間戳一起存儲在向量數據庫中。
生成答案?
設置好 Vector Store 后,您現在可以與視頻對話。對于傳入用戶查詢,嵌入要檢索的查詢,然后重新排序以獲取最相關的數據塊。然后,這些數據塊作為上下文提供給 LLM,以生成答案。附加到數據塊的相應元數據有助于提供引用的視頻和時間戳,這些視頻和時間戳用于回答問題。

開始使用?
準備好開始構建本博文中討論的多模態 RAG 工作流了嗎?使用 NVIDIA API Catalog 中的 NVIDIA NIM 微服務和 NVIDIA Blueprint 示例。