在COMPUTEX 2023, NVIDIA 宣布NVIDIA DGX GH200,這標志著 GPU 的又一突破——加速計算,為最苛刻的巨型人工智能工作負載提供動力。除了描述 NVIDIA DGX GH200 體系結構的關鍵方面外,本文還討論了如何使用NVIDIA Base Command實現快速部署,加快用戶入職,并簡化系統管理。
GPU 的統一內存編程模型是過去 7 年來復雜加速計算應用取得各種突破的基石。 2016 年, NVIDIA 推出NVLink技術和帶有 CUDA-6 的統一內存編程模型,旨在增加 GPU 加速工作負載的可用內存。
從那時起,每個 DGX 系統的核心都是與 NVLink 互連的基板上的 GPU 復合體,其中每個 GPU 可以以 NVLink 的速度訪問另一個的存儲器。許多具有 GPU 復合體的 DGX 通過高速網絡互連,形成更大的超級計算機,如NVIDIA Selene 超級計算機。然而,一類新興的萬億參數的巨型人工智能模型要么需要幾個月的訓練,要么即使在當今最好的超級計算機上也無法求解。
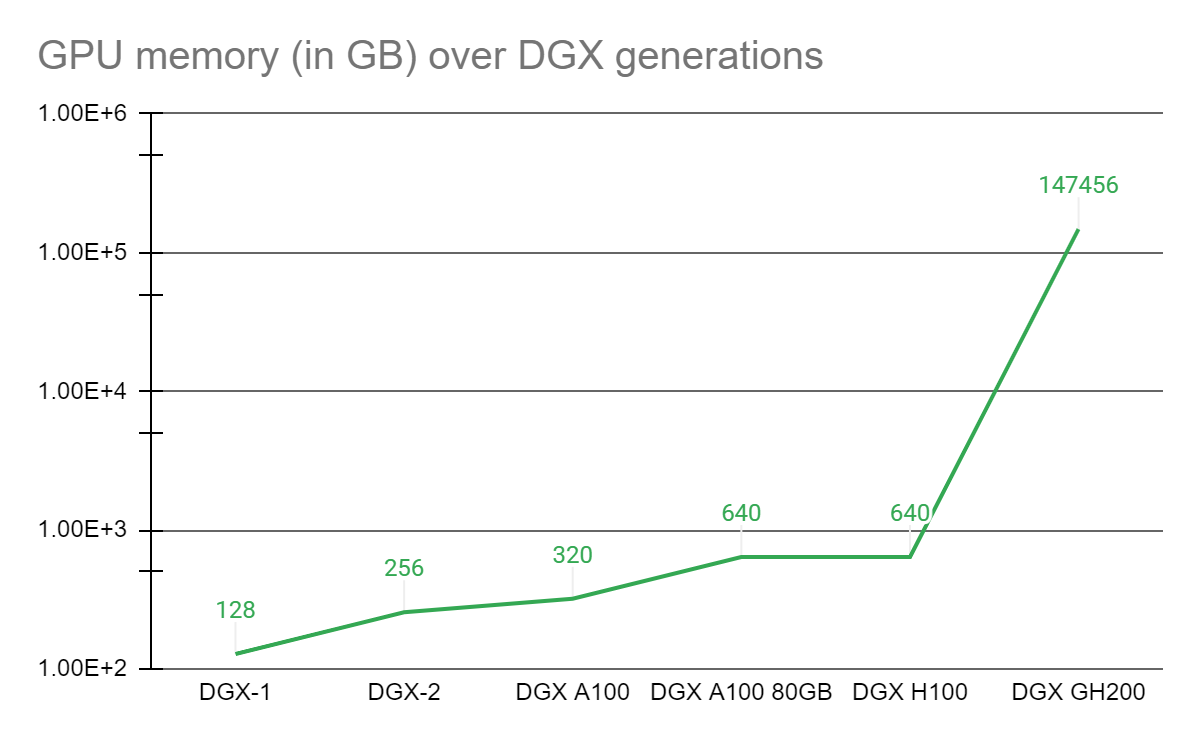
為了讓需要一個能夠解決這些非凡挑戰的先進平臺的科學家們獲得力量, NVIDIA NVIDIA Grace Hopper Superchip與 NVLink 交換系統,在 NVIDIA DGX GH200 系統中集成多達 256 GPU 。在 DGX GH200 系統中, GPU 共享內存編程模型可以通過 NVLink 高速訪問 144 TB 的內存。
與單個相比NVIDIA DGX A100 320 GB 系統, NVIDIA DGX GH200 通過 NVLink 為 GPU 共享內存編程模型提供了近 500 倍的內存,形成了一個巨大的數據中心大小的 GPU 。 NVIDIA DGX GH200 是第一臺突破 NVLink 上 GPU 可訪問內存 100 TB 障礙的超級計算機。
NVIDIA DGX GH200 系統架構
NVIDIA Grace Hopper 超級芯片和 NVLink Switch System 是 NVIDIA DGX GH200 架構的構建塊。 NVIDIA Grace Hopper 超級芯片結合了 Grace 和 Hopper 架構,使用 NVIDIA NVLink-C2C以傳遞 CPU + GPU 相干存儲器模型。 NVLink 交換系統由第四代 NVLink 技術提供動力,將 NVLink 連接擴展到超級芯片,以創建無縫、高帶寬、多 GPU 系統。
NVIDIA DGX GH200 中的每個 NVIDIA Grace Hopper 超級芯片都有 480 GB LPDDR5 CPU 內存,與 DDR5 和 96 GB 快速 HBM3 相比,每 GB 的功率是其八分之一。 NVIDIA Grace CPU 和 Hopper GPU 與 NVLink-C2C 互連,以五分之一的功率提供比 PCIe Gen5 多 7 倍的帶寬。
NVLink 交換系統形成了一個兩級、無阻塞、fat-tree NVLink 結構,可在 DGX GH200 系統中完全連接 256 個 Grace Hopper 超級芯片。 DGX GH200 中的每個 GPU 都可以以 900GBps 訪問所有 NVIDIA Grace CPU 的其他 GPU 和擴展 GPU 存儲器。
托管 Grace Hopper 超級芯片的計算基板使用第一層 NVLink 結構的自定義線束連接到 NVLink 交換機系統。 LinkX 電纜擴展了 NVLink 結構第二層的連接。
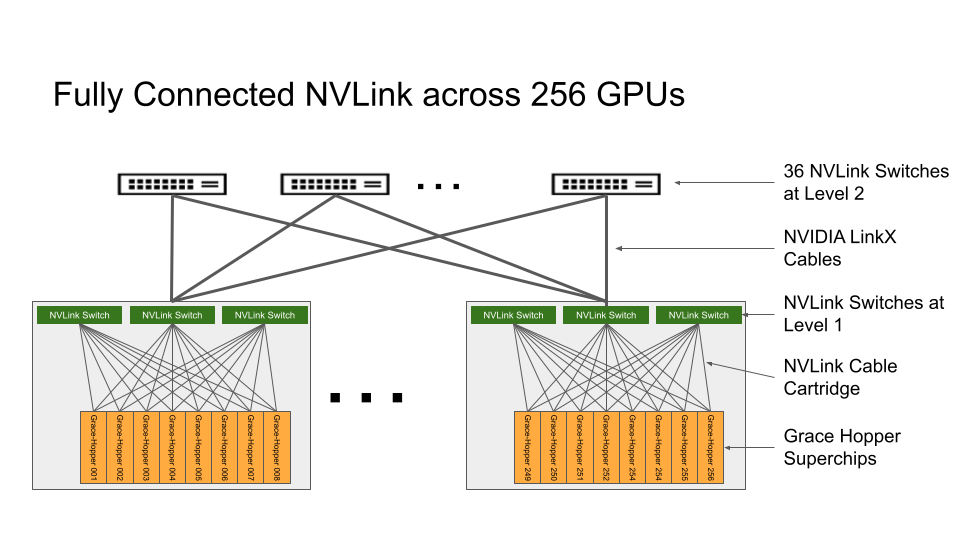
在 DGX GH200 系統中, GPU 線程可以使用 NVLink 頁表從 NVLink 網絡中的其他 Grace Hopper 超級芯片尋址對等 HBM3 和 LPDDR5X 內存。NVIDIA Magnum IO加速庫優化了 GPU 通信以提高效率,并通過所有 256 個 GPU 來增強應用程序的可擴展性。
DGX GH200 中的每個 Grace Hopper 超級芯片都配有一個NVIDIA ConnectX-7網絡適配器和一個NVIDIA BlueField-3 NICDGX GH200 在網絡計算中具有 128 TBps 的雙段帶寬和 230 . 4 TFLOPS 的 NVIDIA SHARP ,以加速人工智能中常用的集體操作,并通過減少集體操作的通信開銷使 NVLink 網絡系統的有效帶寬翻倍。
對于超過 256 GPU 的擴展, ConnectX-7 適配器可以將多個 DGX GH200 系統互連,以擴展到更大的解決方案中。 BlueField -3 DPU 的強大功能將任何企業計算環境轉變為安全且加速的虛擬私有云,使組織能夠在安全的多租戶環境中運行應用程序工作負載。
目標使用案例和性能優勢
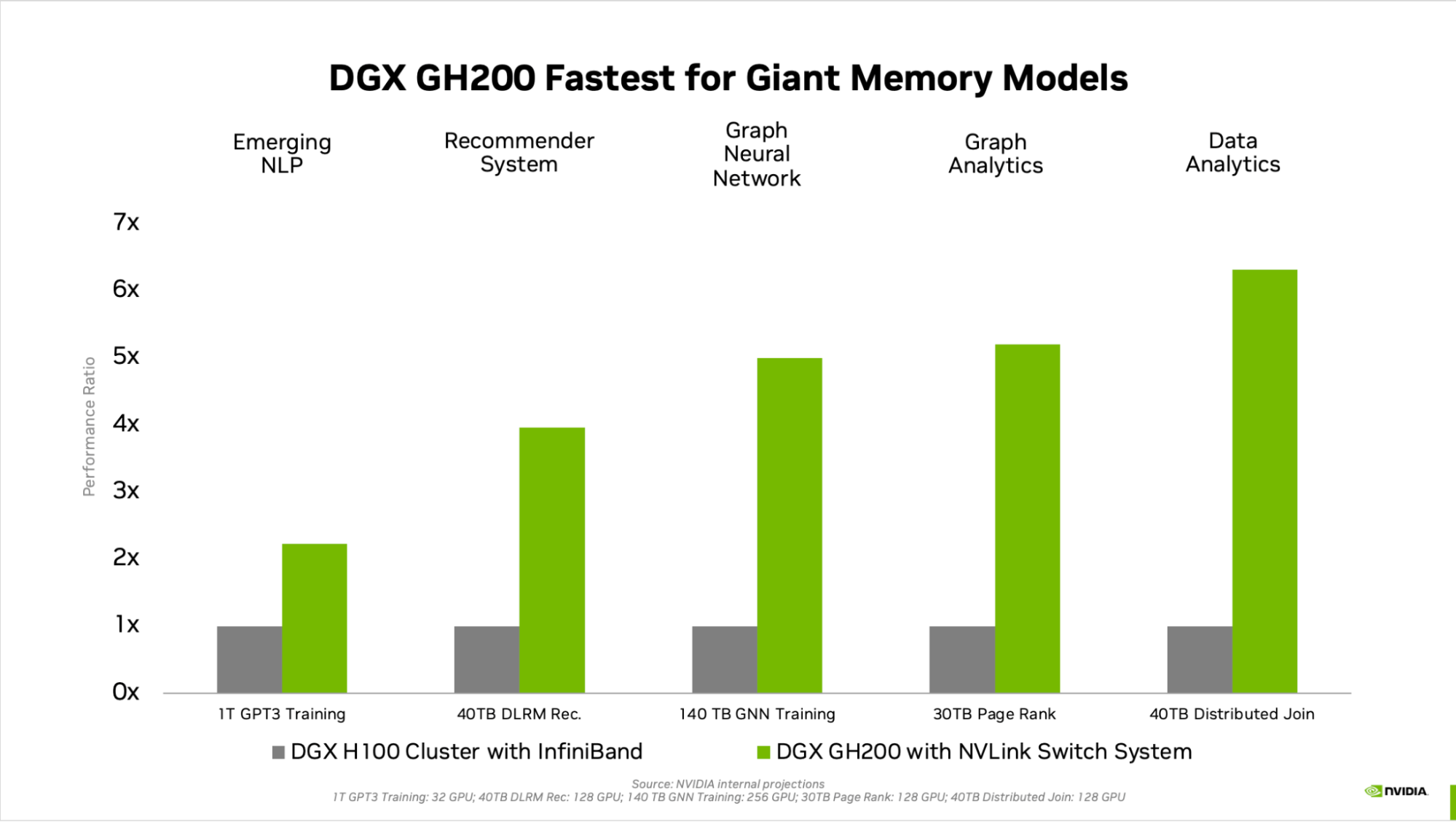
GPU 內存的跨代顯著提高了受 GPU ‘內存大小限制的 AI 和 HPC 應用程序的性能。許多主流 AI 和 HPC 工作負載可以完全駐留在單個NVIDIA DGX H100對于此類工作負載, DGX H100 是性能效率最高的培訓解決方案。
其他工作負載,如具有數 TB 嵌入式表的深度學習推薦模型( DLRM )、數 TB 規模的圖形神經網絡訓練模型或大數據分析工作負載,使用 DGX GH200 可實現 4 到 7 倍的加速。這表明 DGX GH200 是更先進的 AI 和 HPC 模型的更好解決方案,這些模型需要大量內存用于 GPU 共享內存編程。
加速的機制在 NVIDIA Grace Hopper Superchip Architecture白皮書。
專為最苛刻的工作負載而設計
整個 DGX GH200 的每個組件都經過選擇,以最大限度地減少瓶頸,同時最大限度地提高關鍵工作負載的網絡性能,并充分利用所有擴展硬件功能。其結果是線性可擴展性和對大量共享內存空間的高利用率。
為了充分利用這一先進系統, NVIDIA 還構建了一個超高速存儲結構,以在峰值容量下運行,并處理各種數據類型(文本、表格數據、音頻和視頻)- 并行且性能穩定。
全棧 NVIDIA 解決方案
DGX GH200 附帶NVIDIA Base Command,包括針對 AI 工作負載優化的操作系統、集群管理器、加速計算、存儲的庫,以及針對 DGX GH200 系統架構優化的網絡基礎設施。
DGX GH200 還包括NVIDIA AI 企業版,提供了一套優化的軟件和框架,以簡化人工智能的開發和部署。此全棧解決方案使客戶能夠專注于創新,而不用擔心管理其 IT 基礎架構。

增壓巨大的 AI 和 HPC 工作負載
NVIDIA 正致力于在今年年底推出 DGX GH200 。 NVIDIA 渴望提供這臺令人難以置信的第一臺同類超級計算機,讓您能夠在解決當今最大的人工智能和 HPC 挑戰時進行創新并追求自己的激情。了解更多.
?