
近年來,隨著大語言模型 (LLMs)例如 GPT-3、Megatron-Turing、Chinchilla、PaLM-2、Falcon 和 Lama 2 在自然語言生成方面取得了顯著進展。然而,盡管這些 LLM 能夠生成類似人類的文本,但它們可能無法提供符合用戶偏好的有用且細致入微的響應。
當前改進大語言模型 (LLM) 的方法包括監督精調 (SFT),然后是從人類反饋中進行強化學習 (RLHF)。雖然 RLHF 可以提高性能,但它有一些局限性,包括訓練復雜性和缺乏用戶控制。
NVIDIA 研究團隊為了克服這些挑戰,開發并發布了 SteerLM,這是一種新的四步技術,可以簡化 LLM 的自定義,并根據您指定的屬性動態轉向模型輸出,作為 NVIDIA NeMo 的一部分。本文將深入探討 SteerLM 的工作原理,為什么它標志著一個顯著的進步,以及如何訓練 SteerLM 模型。
語言模型帶來前景和潛在陷阱
通過對海量文本語料庫進行預訓練,LLM 可以獲得廣泛的語言能力和世界知識。研究人員已經成功地將 大語言模型應用于多種自然語言處理 (NLP) 任務,例如翻譯、問答和文本生成。但是,這些模型通常無法遵循用戶提供的指示,而是會生成通用、重復或無意義的文本。獲取人工反饋對于自定義 LLM 至關重要。
現有方法帶來的機遇
SFT 增強了模型功能,但導致響應變得簡短而機械。RLHF 通過優先考慮人類偏好的響應而不是替代方案來進一步優化模型。但是,RLHF 需要極其復雜的訓練基礎設施,阻礙了廣泛采用。
隆重推出 SteerLM
SteerLM 利用監督式微調方法,使您能夠在推理期間控制響應。它克服了先前比對技術的限制,包含四個關鍵步驟:
- 在人工標注的數據集上訓練屬性預測模型,以評估有用性、幽默性和創造力等任意數量屬性的響應質量。
- 使用第 1 步中的模型來豐富模型可用數據的多樣性,通過預測不同數據集的屬性分數來對其進行標注。
- 通過訓練 LLM 以根據指定的屬性組合(例如用戶感知的質量和有用性)生成響應,執行屬性條件 SFT.
- 通過模型采樣通過生成以最大質量為條件的不同響應來引導訓練(圖 1,4a),然后對其進行微調以進一步改進對齊方式(圖 1,4b)。
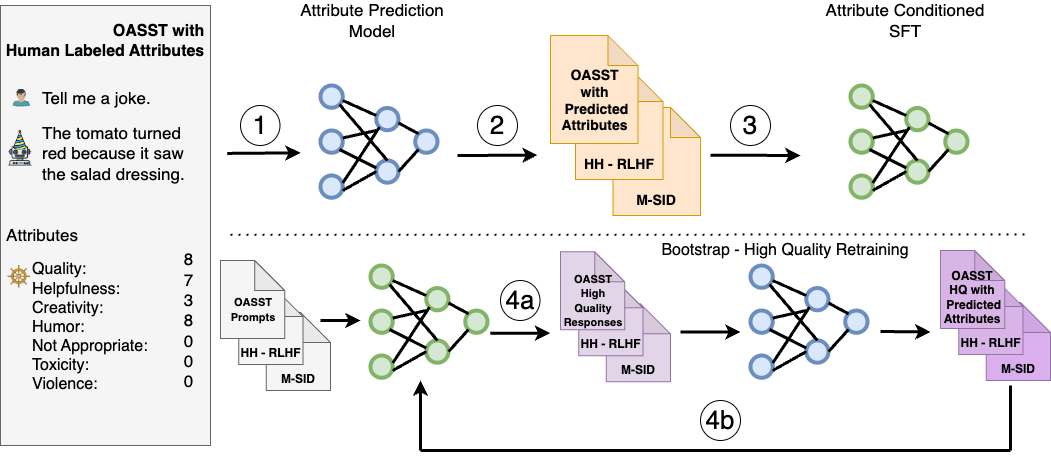
與 RLHF 相比,SteerLM 僅依賴于標準語言建模目標,簡化了對齊。它支持您在推理時調整屬性,從而支持用戶可操控的 AI.這使得開發者能夠定義與應用程序相關的首選項,這與需要使用預定義偏好的其他技術不同。
借助用戶指導解鎖可定制的 AI
SteerLM 的一項關鍵創新是,用戶可以在查詢模型時在推理時指定所需的屬性(例如幽默水平和耐毒性)。您可以從使用 SteerLM 運行一個自定義,轉向在推理時提供多個用例。
SteerLM 支持一系列應用,包括:
- 游戲:適用于游戲場景的各種非玩家角色對話。如需了解詳情,請參閱NVIDIA ACE 通過 NeMo SteerLM 為 AI 驅動的 NPC 添加情感。
- 教育:為學生保留正式且有用的角色。
- 企業:通過個性化功能為組織中的多個團隊提供服務。
- 可訪問性:通過控制敏感屬性,可以抑制不希望出現的模型偏差。
這種靈活性有望解鎖針對個人需求量身打造的新一代定制 AI 系統。
通過簡化的訓練普及先進的定制技術
與其他高級自定義技術所需的專用基礎設施相比,SteerLM 的簡單訓練方案使開發者更容易獲得先進的自定義功能。其性能清楚地表明,增強學習等技術對于穩健的指令調整是不需要的。
利用 SFT 等標準技術可簡化復雜性,盡可能減少對基礎設施和代碼的更改。通過有限的超參數優化,可以實現合理的結果。
總體而言,這帶來了一種簡單實用的方法來獲得高度準確的定制 LLM.在我們的實驗中,SteerLM 43B 在 Vicuna 基準測試中實現了先進的性能,優于現有的 RLHF 模型(如 LLaMA 30B RLHF)。具體來說,SteerLM 43B 在 Vicuna 自動評估中的平均分為 655.75,而 Guanaco 65B 和 LLaMA 30B RLHF 的平均分分別為 646.25 和 612.75.
這些結果突出表明,SteerLM 的簡單訓練過程可以實現與更復雜的 RLHF 技術同等準確的定制 LLM.通過簡化訓練,SteerLM 使開發者更容易實現如此高的準確性,從而更容易實現自定義的大眾化。
如需了解更多詳情,請參閱我們的論文 SteerLM: Attribute Conditioned SFT as an (User-Steerable) Alternative to RLHF。您還可以了解如何使用 SteerLM 方法自定義 Llama 2 13B model。
如何訓練 SteerLM 模型
本節是一個分步教程,將指導您如何使用 2B NeMo LLM 模型在 OASST 數據上運行完整的 SteerLM 工作流。它包括以下內容:
- 數據清理和預處理
- 訓練屬性預測(值模型)
- 訓練屬性條件 SFT (SteerLM 模型)
- 對具有不同屬性值的 SteerLM 模型進行推理
第 1 步:安裝要求
首先安裝必要的 Python 庫:
pip install fire langchain==0.0.133
第 2 步:下載并設置數據子集
本教程使用 OASST 數據集的一小部分。OASST 包含具有 13 種不同質量屬性的人工標注的開放領域對話。
首先下載并對其進行子集:
mkdir -p data cd data wget https://huggingface.co/datasets/OpenAssistant/oasst1/resolve/main/2023-04-12_oasst_all.trees.jsonl.gz gunzip -f 2023-04-12_oasst_all.trees.jsonl.gz mv 2023-04-12_oasst_all.trees.jsonl data.jsonl head -5000 data.jsonl > subset_data.jsonl cd -
第 3 步:下載 Lama 2 LLM 模型和分詞器并轉換
下載 Llama 2 7B LLM model 和 tokenizer。
然后將 Lama 2 LLM 轉換為 .nemo 格式:
python NeMo/scripts/nlp_language_modeling/convert_hf_llama_to_nemo.py --in-file /path/to/llama --out-file /output_path/llama7b.nemo
解壓縮 .nemo 文件以獲取 NeMo 格式的分詞器:
tar <path-to-model>/llama7b.nemo mv ba4632640484461f8ae9d61f6dfe0d0b_tokenizer.model tokenizer.model
提取時,分詞器的前綴會有所不同。請確保在運行上述命令時使用正確的分詞器文件。
第 4 步:預處理 OASST 數據
使用 NeMo 預處理腳本,然后創建單獨的文本到值和值到文本版本:
python scripts/nlp_language_modeling/sft/preprocessing.py \
--input_file=data/subset_data.jsonl \
--output_file_prefix=data/subset_data_output \
--mask_role=User \
--type=TEXT_TO_VALUE \
--split_ratio=0.95 \
--seed=10
python scripts/nlp_language_modeling/sft/preprocessing.py \
--input_file=data/subset_data.jsonl \
--output_file_prefix=data/subset_data_output_v2t \
--mask_role=User \
--type=VALUE_TO_TEXT \
--split_ratio=0.95 \
--seed=10
第 5 步:清理文本轉值數據
如果由于按序列長度截斷而屏蔽了所有標記,則運行以下腳本將刪除這些記錄。
python scripts/nlp_language_modeling/sft/data_clean.py \
--dataset_file=data/subset_data_output_train.jsonl \
--output_file=data/subset_data_output_train_clean.jsonl \
--library sentencepiece \
--model_file tokenizer.model \
--seq_len 4096
python scripts/nlp_language_modeling/sft/data_clean.py \
--dataset_file=data/subset_data_output_val.jsonl \
--output_file=data/subset_data_output_val_clean.jsonl \
--library sentencepiece \
--model_file tokenizer.model \
--seq_len 4096
第 6 步:使用經過清理的 OASST 數據訓練值模型
在本教程中,針對 1K 步長訓練值模型。請注意,我們建議對更多數據進行更長時間的訓練,以獲得良好的值模型。
python examples/nlp/language_modeling/tuning/megatron_gpt_sft.py \
++trainer.limit_val_batches=10 \
trainer.num_nodes=1 \
trainer.devices=2 \
trainer.max_epochs=null \
trainer.max_steps=1000 \
trainer.val_check_interval=100 \
trainer.precision=bf16 \
model.megatron_amp_O2=False \
model.restore_from_path=/model/llama7b.nemo \
model.tensor_model_parallel_size=2 \
model.pipeline_model_parallel_size=1 \
model.optim.lr=5e-6 \
model.optim.name=distributed_fused_adam \
model.optim.weight_decay=0.01 \
model.answer_only_loss=True \
model.activations_checkpoint_granularity=selective \
model.activations_checkpoint_method=uniform \
model.data.chat=True \
model.data.train_ds.max_seq_length=4096 \
model.data.train_ds.micro_batch_size=1 \
model.data.train_ds.global_batch_size=1 \
model.data.train_ds.file_names=[data/subset_data_output_train_clean.jsonl] \
model.data.train_ds.concat_sampling_probabilities=[1.0] \
model.data.train_ds.num_workers=0 \
?? model.data.train_ds.hf_dataset=True \
model.data.train_ds.prompt_template='\{input\}\{output\}' \
model.data.train_ds.add_eos=False \
model.data.validation_ds.max_seq_length=4096 \
model.data.validation_ds.file_names=[data/subset_data_output_val_clean.jsonl] \
model.data.validation_ds.names=["oasst"] \
model.data.validation_ds.micro_batch_size=1 \
model.data.validation_ds.global_batch_size=1 \
model.data.validation_ds.num_workers=0 \
model.data.validation_ds.metric.name=loss \
model.data.validation_ds.index_mapping_dir=/indexmap_dir \
model.data.validation_ds.hf_dataset=True \
model.data.validation_ds.prompt_template='\{input\}\{output\}' \
model.data.validation_ds.add_eos=False \
model.data.test_ds.max_seq_length=4096 \
model.data.test_ds.file_names=[data/subset_data_output_val_clean.jsonl] \
model.data.test_ds.names=["oasst"] \
model.data.test_ds.micro_batch_size=1 \
model.data.test_ds.global_batch_size=1 \
model.data.test_ds.num_workers=0 \
model.data.test_ds.metric.name=loss \
model.data.test_ds.hf_dataset=True \
model.data.test_ds.prompt_template='\{input\}\{output\}' \
model.data.test_ds.add_eos=False \
exp_manager.explicit_log_dir="/home/value_model/" \
exp_manager.create_checkpoint_callback=True \
exp_manager.checkpoint_callback_params.monitor=val_loss \
exp_manager.checkpoint_callback_params.mode=min
第 7 步:生成標注
要生成標注,請在后臺運行以下命令以運行推理服務器:
python examples/nlp/language_modeling/megatron_gpt_eval.py \
gpt_model_file=/models/<TRAINED_ATTR_PREDICTION_MODEL.nemo> \
pipeline_model_parallel_split_rank=0 \
server=True \
tensor_model_parallel_size=1 \
pipeline_model_parallel_size=1 \
trainer.precision=bf16 \
trainer.devices=1 \
trainer.num_nodes=1 \
web_server=False \
port=1424
現在執行:
python scripts/nlp_language_modeling/sft/attribute_annotate.py --batch_size=1 --host=localhost --input_file_name=data/subset_data_output_v2t_train.jsonl --output_file_name=data/subset_data_v2t_train_value_output.jsonl --port_num=1424 python scripts/nlp_language_modeling/sft/attribute_annotate.py --batch_size=1 --host=localhost --input_file_name=data/subset_data_output_v2t_val.jsonl --output_file_name=data/subset_data_v2t_val_value_output.jsonl --port_num=1424
第 8 步:清理從值到文本的數據
如果在按序列長度截斷后對所有標記進行了遮罩,則刪除記錄:
python scripts/data_clean.py \
--dataset_file=data/subset_data_v2t_train_value_output.jsonl \
--output_file=data/subset_data_v2t_train_value_output_clean.jsonl \
--library sentencepiece \
--model_file tokenizer.model \
--seq_len 4096
python scripts/data_clean.py \
--dataset_file=data/subset_data_v2t_val_value_output.jsonl \
--output_file=data/subset_data_v2t_val_value_output_clean.jsonl \
--library sentencepiece \
--model_file tokenizer.model \
--seq_len 4096
第 9 步:訓練 SteerLM 模型
出于本教程的目的,SteerLM 模型經過 1K 步長的訓練。請注意,我們建議使用更多數據進行更長時間的訓練,以獲得經過良好調優的模型。
python examples/nlp/language_modeling/tuning/megatron_gpt_sft.py \
++trainer.limit_val_batches=10 \
trainer.num_nodes=1 \
trainer.devices=2 \
trainer.max_epochs=null \
trainer.max_steps=1000 \
trainer.val_check_interval=100 \
trainer.precision=bf16 \
model.megatron_amp_O2=False \
model.restore_from_path=/model/llama7b.nemo \
model.tensor_model_parallel_size=2 \
model.pipeline_model_parallel_size=1 \
model.optim.lr=5e-6 \
model.optim.name=distributed_fused_adam \
model.optim.weight_decay=0.01 \
model.answer_only_loss=True \
model.activations_checkpoint_granularity=selective \
model.activations_checkpoint_method=uniform \
model.data.chat=True \
model.data.train_ds.max_seq_length=4096 \
model.data.train_ds.micro_batch_size=1 \
model.data.train_ds.global_batch_size=1 \
model.data.train_ds.file_names=[data/subset_data_v2t_train_value_output_clean.jsonl] \
model.data.train_ds.concat_sampling_probabilities=[1.0] \
model.data.train_ds.num_workers=0 \
model.data.train_ds.prompt_template='\{input\}\{output\}' \
model.data.train_ds.add_eos=False \
model.data.validation_ds.max_seq_length=4096 \
model.data.validation_ds.file_names=[data/subset_data_v2t_val_value_output_clean.jsonl] \
model.data.validation_ds.names=["oasst"] \
model.data.validation_ds.micro_batch_size=1 \
model.data.validation_ds.global_batch_size=1 \
model.data.validation_ds.num_workers=0 \
model.data.validation_ds.metric.name=loss \
model.data.validation_ds.index_mapping_dir=/indexmap_dir \
model.data.validation_ds.prompt_template='\{input\}\{output\}' \
model.data.validation_ds.add_eos=False \
model.data.test_ds.max_seq_length=4096 \
model.data.test_ds.file_names=[data/subset_data_v2t_val_value_output_clean.jsonl] \
model.data.test_ds.names=["oasst"] \
model.data.test_ds.micro_batch_size=1 \
model.data.test_ds.global_batch_size=1 \
model.data.test_ds.num_workers=0 \
model.data.test_ds.metric.name=loss \
model.data.test_ds.prompt_template='\{input\}\{output\}' \
model.data.test_ds.add_eos=False \
exp_manager.explicit_log_dir="/home/steerlm_model/" \
exp_manager.create_checkpoint_callback=True \
exp_manager.checkpoint_callback_params.monitor=val_loss \
exp_manager.checkpoint_callback_params.mode=min
第 10 步:推理
要開始推理,請使用以下命令在后臺運行推理服務器:
python examples/nlp/language_modeling/megatron_gpt_eval.py \
gpt_model_file=/models/<TRAINED_STEERLM_MODEL.nemo> \
pipeline_model_parallel_split_rank=0 \
server=True \
tensor_model_parallel_size=1 \
pipeline_model_parallel_size=1 \
trainer.precision=bf16 \
trainer.devices=1 \
trainer.num_nodes=1 \
web_server=False \
port=1427
接下來,創建 Python 輔助函數:
def get_answer(question, max_tokens, values, eval_port='1427'): prompt = f"""<extra_id_0>SystemA chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions.<extra_id_1>User{question}<extra_id_1>Assistant<extra_id_2>{values}""" prompts = [prompt] data = { "sentences": prompts, "tokens_to_generate": max_tokens, "top_k": 1, 'greedy': True, 'end_strings': ["<extra_id_1>", "quality:", "quality:4", "quality:0"] } response = requests.put(url, json=data) json_response = response.json() response_sentence = json_response['sentences'][0][len(prompt):] return response_sentence |
def encode_labels(labels): items = [] for key in labels: value = labels[key] items.append(f'{key}:{value}') return ','.join(items) |
接下來,更改以下值以指導語言模型:
values = OrderedDict([ ('quality', 4), ('toxicity', 0), ('humor', 0), ('creativity', 0), ('violence', 0), ('helpfulness', 4), ('not_appropriate', 0), ('hate_speech', 0), ('sexual_content', 0), ('fails_task', 0), ('political_content', 0), ('moral_judgement', 0),])values = encode_labels(values) |
最后,提出問題并生成回復:
question = """Where and when did techno music originate?"""print (get_answer(question, 4096, values)) |
SteerLM 用戶可以使用本教程中提到的腳本和實用程序執行其他引導步驟。此步驟有助于進一步提高不同基準測試中的模型準確性。
借助 SteerLM 實現 AI 的未來
SteerLM 提供了一種新技術,用于以可控的方式實現符合人類偏好的新一代 AI 系統。其概念簡單、性能提升和可定制性凸顯了用戶可操控 AI 的變革性可能性。SteerLM 現已作為開源軟件提供,可通過NVIDIA/NeMo 的 GitHub 存儲庫獲取。您還可以獲取有關如何嘗試使用Llama 2 13B model 進行 SteerLM 方法自定義的信息。
為了獲得全面的企業安全和支持,SteerLM 將被集成到NVIDIA NeMo,這是一個用于構建、自定義和部署大型生成式 AI 模型的豐富框架。SteerLM 方法適用于 NeMo 支持的所有模型,包括流行的社區構建的預訓練 LLM,例如 Llama 2、Falcon LLM 和 MPT。我們希望我們的工作能夠促進進一步的研究,以開發能夠為用戶提供動力而不是約束他們的模型。借助 SteerLM,AI 的未來是可操控的。
致謝
我們要感謝 Xianchao Wu 和 Oleksii Kuchaiev 為這篇博文以及 SteerLM 的創立所做的貢獻。
?






